化学プラント・産業プラントは、温度・圧力・流量・濃度といった いろいろなプロセス変数を制御 (コントロール) しながら運転する必要があります。
設定値の変更
たとえば、製品の生産量を増やしたい・減らしたいときや製品の銘柄を変えたいとき、なるべく早く目標の生産量・銘柄にするため、原料の量や反応器内の温度などを適切に変えなければいけません。プラントにおける設定値を変更するときに制御が必要になるわけです (明治大学応用化学科の3年生にとって、応用化学実験4機器実験4で、水温の目標値を目指して制御するのと同じです)。
外乱
またプラントでは、原料の濃度・外気温・大気圧に変化があるように、プラント周辺の環境が変わります。このようにプロセスを乱すものを外乱と呼びます。外乱がある中で、プラントで作る製品の品質・量を、一定に保つよう制御しなければなりません。もちろん、爆発が起きないように、異常な状態にならないようにするため、温度・圧力・流量といったプロセス変数を正常の範囲内に制御する必要もあります。
プロセス制御・プロセス管理
このように、
- 設定値変更
- 外乱
があるなかで、早く・安定的に、プラントを理想的な状態に保ちたいため、制御する必要があるわけです。
明治大学応用化学科の3年生は、応用化学実験4機器実験4で、水温のPID制御をやります (実験していなくてPID制御をまだやっていない方は、PID制御とは運転する車の速度を変えたいときにどれくらいアクセルを踏めばよいか計算してくれるもの、と考えてください)。水温の設定値を変更したとき、どのくらいヒーターで加熱するかを PID制御の式で計算します (実際はPID制御のパラメータを入力すればサイリスタがやってくれます)。もちろん、入口の水の流量が多少変わり、水温を維持するために必要な熱量が変わってしまうときも (外乱)、PID制御で水温が一定に保たれます。たとえば、水温が29.7℃より下がってほしくない、30.3℃より上がってほしくないときに、その範囲内におさまるように制御できるわけです。
うまく制御・管理できないとき
ただ実は、上の実験のような流体加熱プロセスをPID制御で (わりと簡単に) 管理できたのは、いくつかの条件がそろっていたから、なのです。たとえば、
① 管理するのが水温1つだけだった
② 温度をリアルタイムに測定できた
です。順に説明します。
① たくさんのプロセス変数をまとめて管理する (多変量プロセス管理)
管理したいプロセス変数が水温のように1つだけでなく、複数あるときを考えてみましょう。たとえば、多段蒸留塔における どこかの2つの段の温度のように、管理したい温度が2つあるとします。これらの2つの温度が、それぞれ独立して変化するのであれば問題はありません。ただ、蒸留塔で加熱量を大きくしたとき、ある段の温度が上がれば、別の段の温度も上がるわけです。このように多くの場合、複数のプロセス変数はそれぞれ独立に変化するわけではなく、相関関係があります。このとき、どうして2つの温度の管理に問題が起きるのでしょうか。下にある2つの温度の時間プロットをご覧ください。
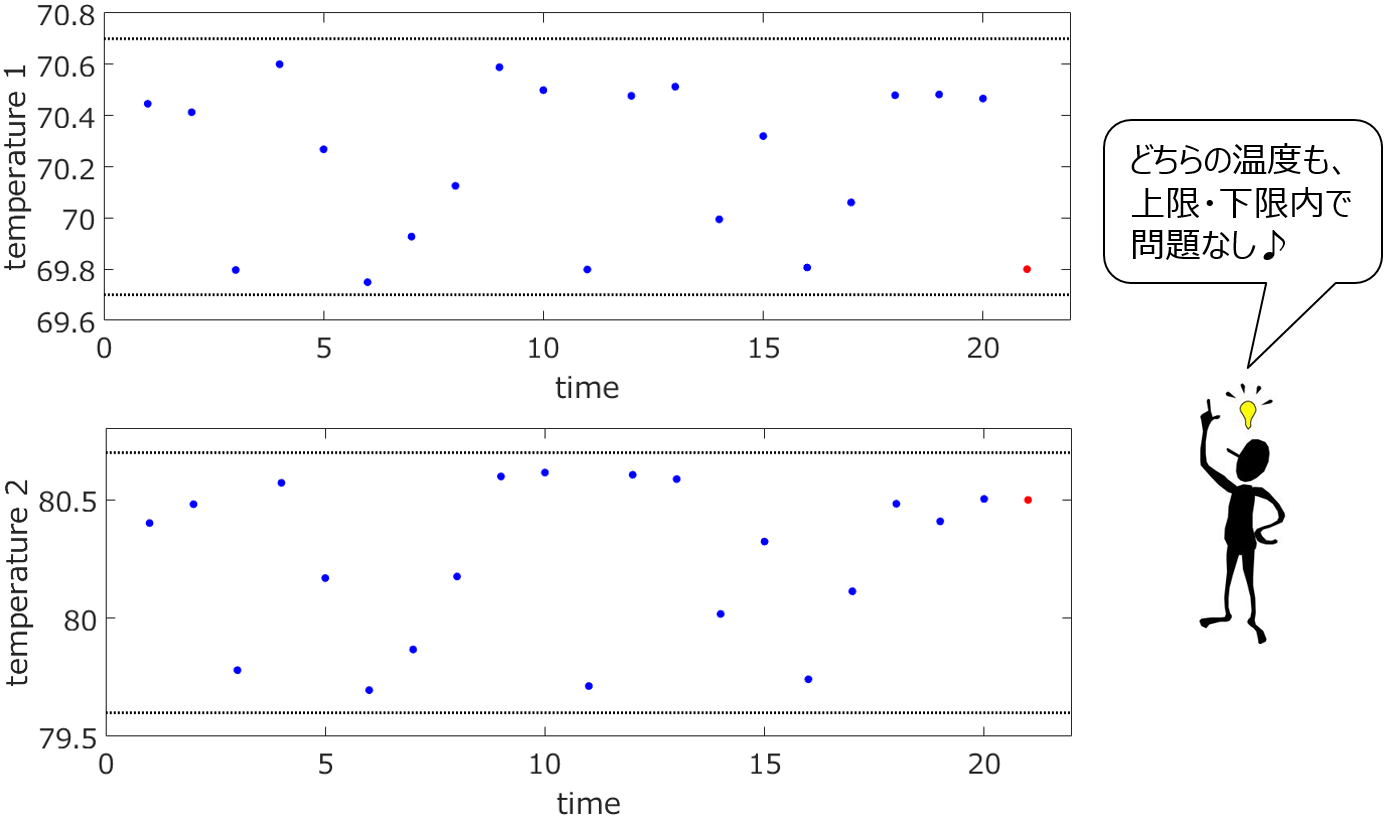
2つの温度は、それぞれ黒い点線で表わされる上限と下限の間に入っています。問題なさそうです。ただ、2つの温度の散布図が下のようになります。
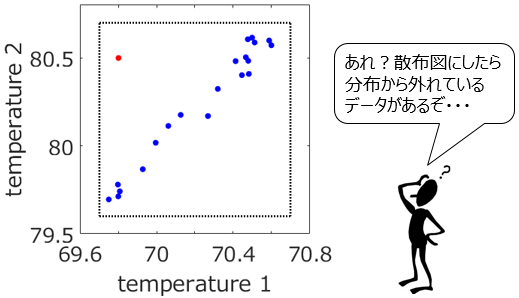
黒い点線はそれぞれの温度の上限と下限です。時間プロットの赤い点は、散布図の赤い点に対応します。散布図を見ると、赤い点で表したデータは、他の青い点のデータと離れたところにあることが分かります。つまり、2つの温度は相関関係をもって変化していたにもかかわらず、赤い点の時刻ではその相関関係からズレた、ということです。何か異常が起きていると考えられます。
しかし、それぞれの温度において、上限と下限で正常な状態を設定すると、この異常を検出することができません。そこで、複数のプロセス変数をまとめて管理しよう、という話になります。
たとえば、正常なデータが存在する領域を、下図の楕円のように設定します。
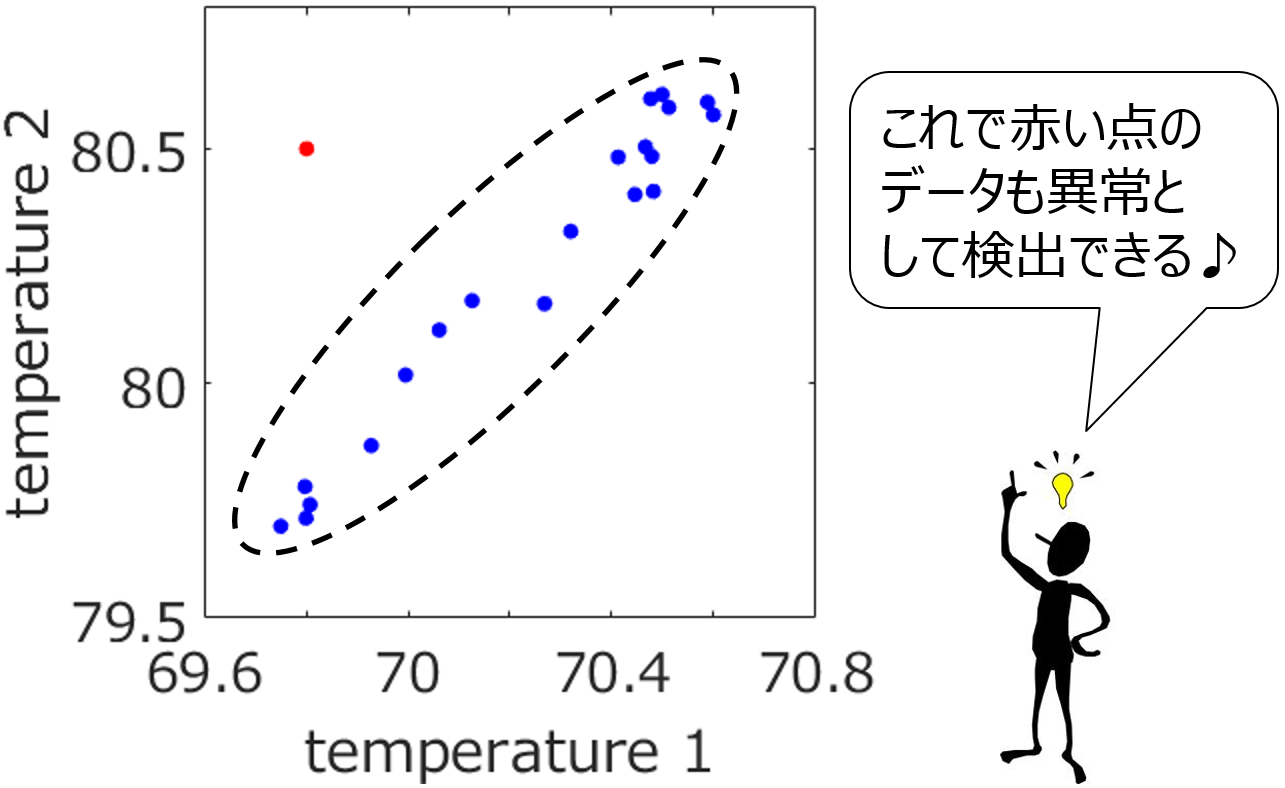
この楕円を設定できれば、それを超えたデータについては何らかの異常があるだろう、と判断できます。ちなみに楕円であれば、こちらの主成分分析 (Principal Component Analysis, PCA) をうまく使うと決めることができます。しかし、データの分布が複数に分かれるなど、分布が複雑になると、楕円でも対応できません。適切に正常なデータの領域を決める必要があります。
そして、上のようにプロセス変数をまとめて管理すると、プロセス変数の数が100とか1000とか多くなったとき、異常が検出されたあとに、どのプロセス変数が異常に関わっているのかを改めて考えなければなりません。そして、異常な状態から元の状態に戻すためには、異常の原因を探る必要があります。
まとめると、研究の方針としては
- 正常なデータが存在する適切なデータ領域を決める
- 異常と診断されたときにどのプロセス変数が異常に関わっているか診断する
- 異常の原因を解明する
となります。
② プロセス変数の値を推定しながら制御する (ソフトセンサー)
次に、流体加熱プロセスをPID制御で水温を管理できた条件の2つ目の話です。温度制御のとき、現在の温度の値がすぐにわかったからこそ、PID制御ができたわけです。
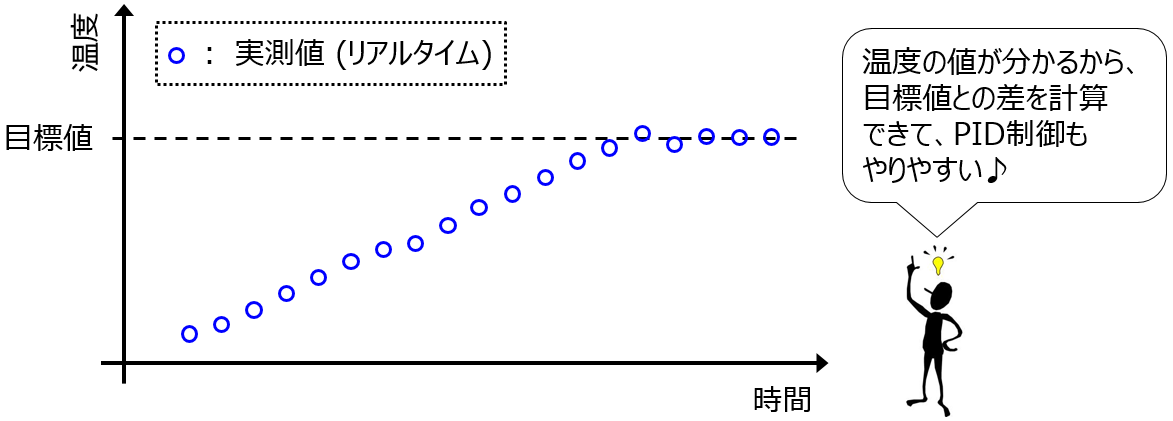
温度の測定値がないと、目標温度との差が分かりませんよね (実験していない方は、現在の車の速度がわからない中で、車を運転しなければならない状況をお考えください。恐ろしいですね。ただ、これと同じことが現実の化学プラントでもあるわけです)。
たとえば、製品品質の1つとして濃度や密度を制御することを考えてみましょう。温度制御するときに温度の測定値が必要だったのと同じで、濃度や密度の測定値が必要です。
たとえば濃度では、製品の一部をサンプリングして、ガスクロマトグラフィーで濃度を測定します。サンプリング時間や測定時間を考えると、濃度の測定値が得られるまで数十分かかってしまいます。密度についても、製品をサンプリングして密度測定器に入れて、数時間後にその測定結果がわかる、といった具合です。つまり、製品品質に関わる変数の多くは、リアルタイムに頻繁に測定できるわけではないということです。
PID制御は、プロセス変数の目標の値と現在の測定値との差に応じて、操作変数の値を決める制御でした。濃度や密度のように、現在の測定値がわからないと、どのように操作すればよいかわかりません。現在の速度が分からない中で車を運転するようなものです。危険ですね。
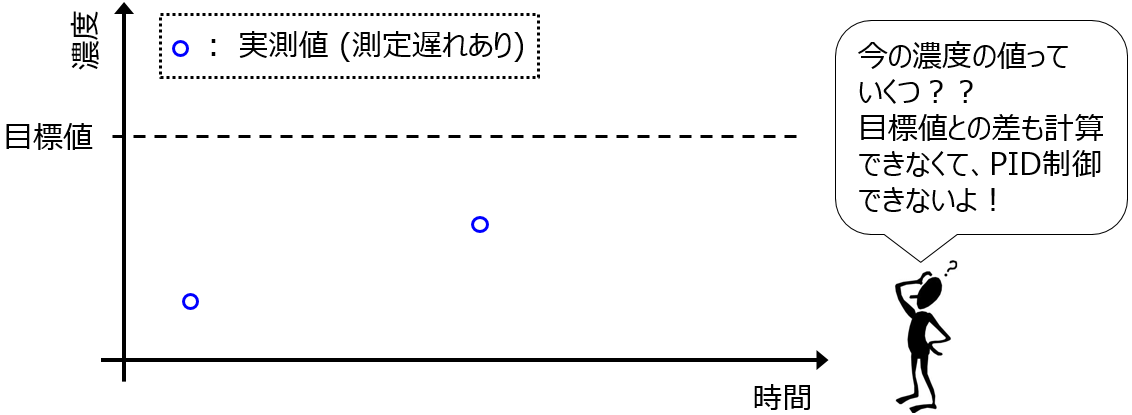
このような、測定が難しいプロセス変数の値を、推定する方法があります。この方法を、ソフトセンサーと呼びます。ソフトセンサーの概要を下図に示します。
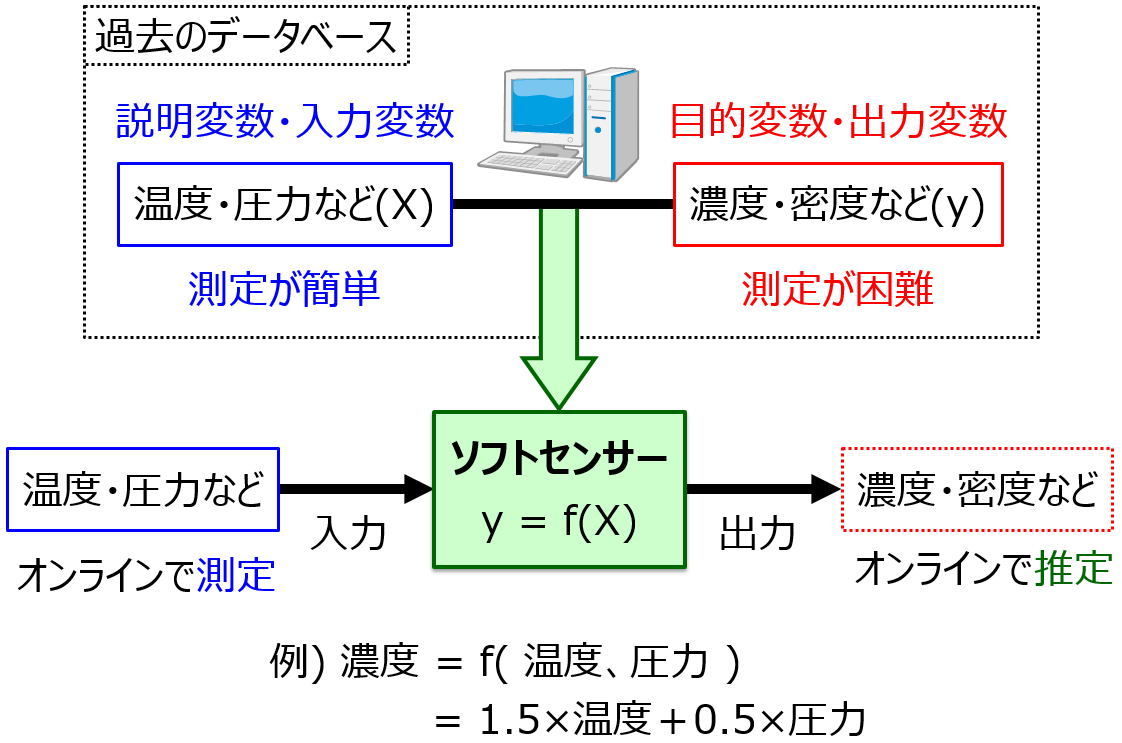
過去に化学プラントで測定されたデータを用いて、温度・圧力などの簡単に測定できるプロセス変数と、濃度・密度などの測定が難しいプロセス変数との間で、回帰分析を行います。その結果、たとえば、濃度 = 1.5×温度 + 0.5×圧力 のような式 (回帰モデル) が得られます。つまり、ソフトセンサーとは回帰モデルのことです。回帰分析やクラス分類の手法についてはこちらをご覧ください。ここでの回帰分析やクラス分類のことを、一般的にモデリングと呼びます。
温度計や圧力計などの実際のセンサーのことをハードセンサーと呼ぶ一方で、ソフトセンサーとは、(ハードウェアではなく) コンピュータの中にあるソフトウェア的な、いわゆる計算式のことなのです。
新たに測定された温度や圧力の値を ソフトセンサー、つまり回帰モデルに入力することで、濃度や密度の値を推定することができます。温度や圧力はリアルタイムに測定されていますので、濃度・密度の推定値も同じようにリアルタイムに得られるわけです。この濃度・密度の推定値を、あたかも濃度の測定値として使うことで、迅速なプロセス制御を達成できます。
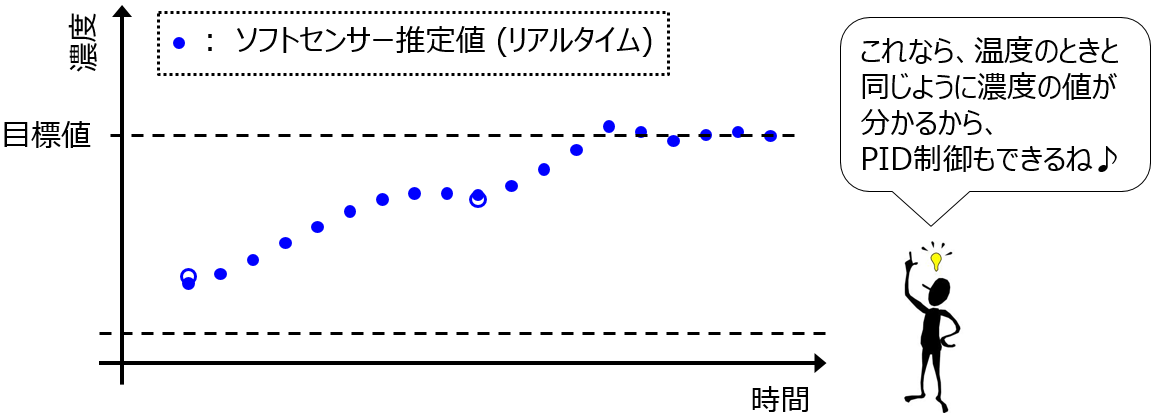
このソフトセンサーも一つのモデル、つまり化学プラントのモデル、ですので、この仮想的なプラントであるソフトセンサーを使って いろいろなシミュレーションができます。操作変数の値をどのようにすれが、より迅速に制御できるか検討できるわけです。つまり、研究の1つの方向性は、ソフトセンサーを使った迅速かつ効率的な制御です。
ただ、ソフトセンサーにはいくつか問題点があります。大きな問題の1つは、モデルの劣化と呼ばれているものです。化学プラントは長期的に運転されるため、その間に いろいろなことが起こります。たとえば、反応器内の触媒が劣化したり、原料の組成が変化したり、配管などの内側に汚れがついたりです。そうなると、最初にソフトセンサーを作ったときの、温度・圧力・濃度・密度などのプロセス変数の間の関係も、変化してしまいます。つまり、ソフトセンサーからの推定値と、実際の値とが合わなくなる、ということです。ソフトセンサーの推定性能が落ちる、ということもできます。このような時には、ソフトセンサーの推定値を信用することはできません。
そこで適応的ソフトセンサーというものが提案されています。化学プラントでは、数は少ないですが濃度や密度の値も測定されています。これらの最新の測定値を使って、新たなソフトセンサーとして自動的に作り直そう、というわけです。そのため、研究の一つの方向性としては、推定精度の高い適応的ソフトセンサーを作る、となります。
もちろん、適応的ソフトセンサーを使ったとしても、濃度・密度などの値を完璧に推定できるわけではありません。では、推定性能が悪くなるときはどんなときか?、これを判断できるようになることも重要です。つまり、ソフトセンサーとして推定値を計算するだけでなく、推定値のエラーバーも合わせて推定結果とするということです。
つまり、モデルの適用範囲・適用領域を考慮する、ということです。そして、その範囲・領域と、推定誤差のばらつきとの間の関係を定量的に求める必要もあります。
そして、残念ながら、データから作成するモデルの場合、モデルの適用範囲・適用領域はデータベースに依存してしまいます。モデルの適用範囲・適用領域を拡張するための方向性として、プロセスモデルを活用することだと考えています。
研究の方向性 まとめ
これまでの研究の方向性を下にまとめます。
- たくさんのプロセス変数があるとき、それらをまとめて管理する
- 異常が起きたとき、どのプロセス変数が異常に関わっているかを診断する
- 異常の原因を解明する
- 推定性能の高いソフトセンサーを作る
- ソフトセンサーの信頼性を判断する
- プロセスモデルによりモデルの適用範囲・適用領域を拡張する
- ソフトセンサーを使って迅速かつ効率的な制御を検討する
以上です。
質問やコメントなどありましたら、twitter, facebook, メールなどでご連絡いただけるとうれしいです。