異常検出を試してみたい、プラントのデータを使って異常なのか正常なのか推定してみたら、どれくらいの異常を推定できるのか確認してみたい、という方はいらっしゃると思います。
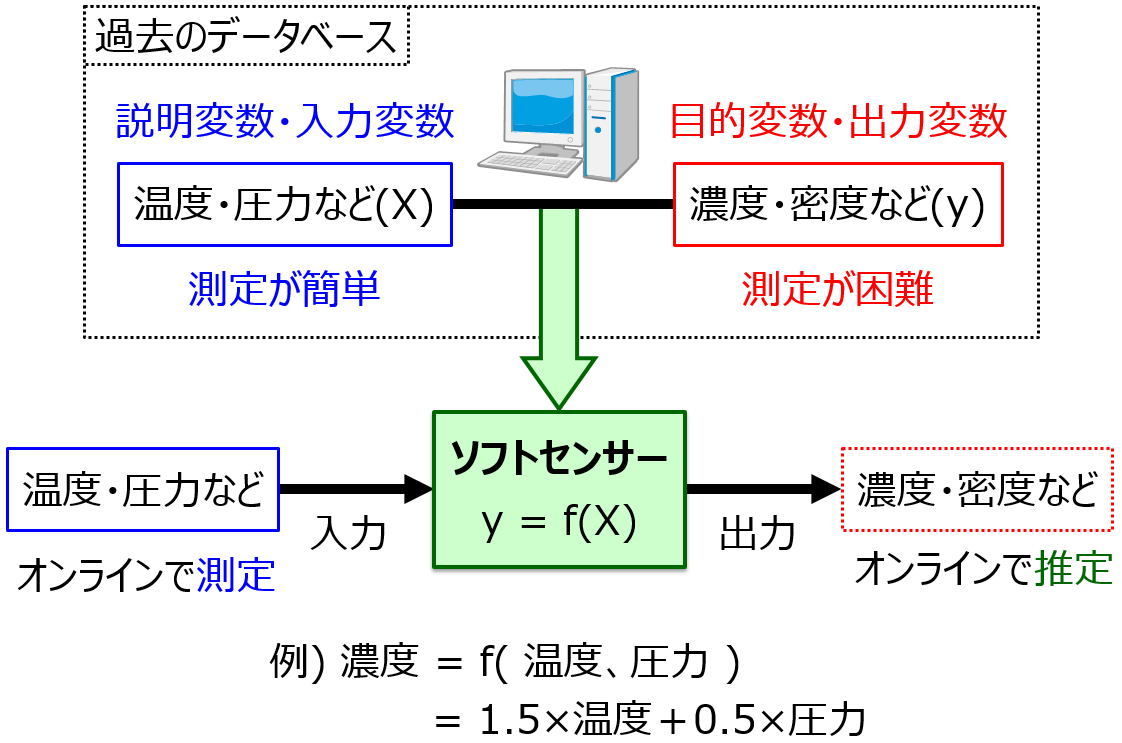
試してみて良い結果が出ると、さらに異常検出について勉強するモチベーションも上がりますしね。
ただ、とりあえず試してみるといっても、異常検出モデルを構築するためには、ツールとかアプリの使い方を調べたり、プログラミングを学んだりしないといけません。ハードルは高めです。
また、ちょっと試してみるにしても、間違って解析してしまって、悪い結果が出たらそれで諦めてしまい、もったいないです。逆に良い結果が出ても、それが間違えによって良い結果になっていたら、それに気付くまでの時間がもったいないです。
そのため、
簡単に、妥当な異常検出を試してみる
ことが求められているわけです。
そこで今回は、クリックだけで異常検出を試せるアプリ 「DCE fault detection」 を作りました。なお Windows 10 Pro でのみ動作確認をしており、特に macOS では使用できないと思います。ご注意ください。
搭載されている手法は、主成分分析 (Principal Component Analysis, PCA) → T2統計量・Q統計量と
One-Class Support Vector Machine (OCSVM) です。
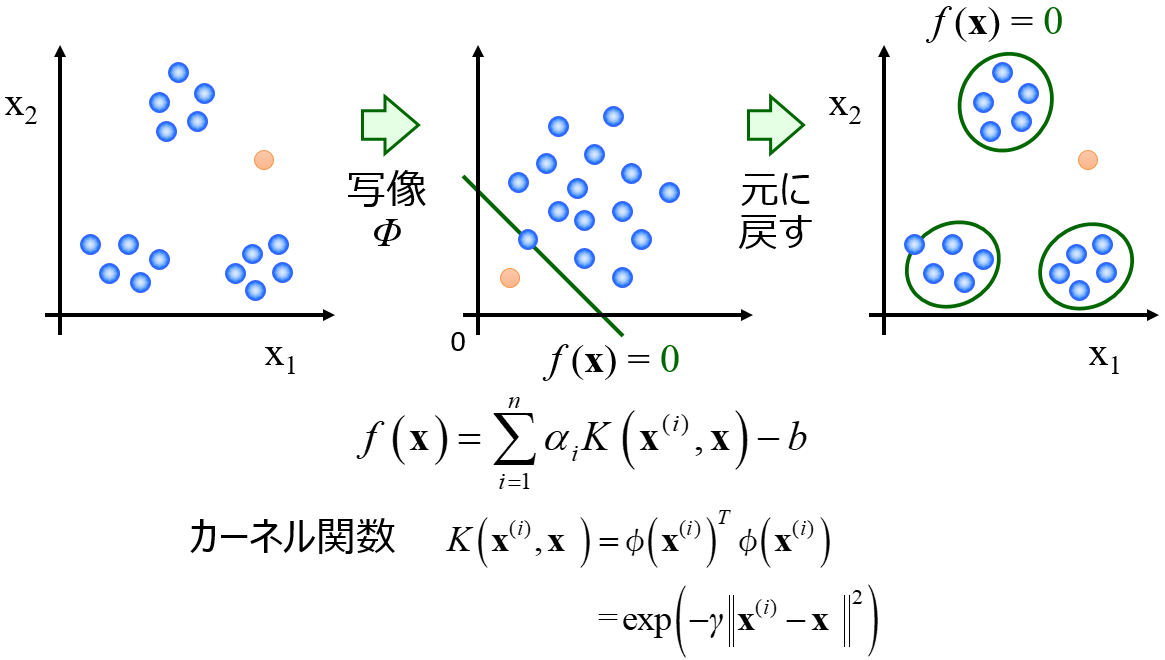
これらの PCA, OCSVM により、以下の 5 つのことができます。
- トレーニングデータを用いて異常検出モデルを構築し、テストデータの異常を推定する (テストデータの異常推定はなしでも OK)
- 説明変数 X の時間遅れを考慮して異常検出モデルを構築したり、異常を推定したりする
- OCSVM における γ (ガンマ) として最適な値を選択する
- リアルタイムに測定される X の値に基づいて、その時刻のプロセス状態が異常かどうか判定する (csv ファイルが更新されたら、そのデータセットが異常かどうか自動的に診断する)
それでは今回のアプリ DCE fault detection の説明をします。まず以下から zip ファイルをダウンロードし、解凍してください。
解凍しましたら、その dce_fault_detection フォルダの中で、dce_fault_detection.exe を探してください (ファイルの数が多くてすみません。。。)。下図のように見つかると思います (拡張子を表示しない設定ですと、「dce_fault_detection」 しか表示されないかもしれません)。
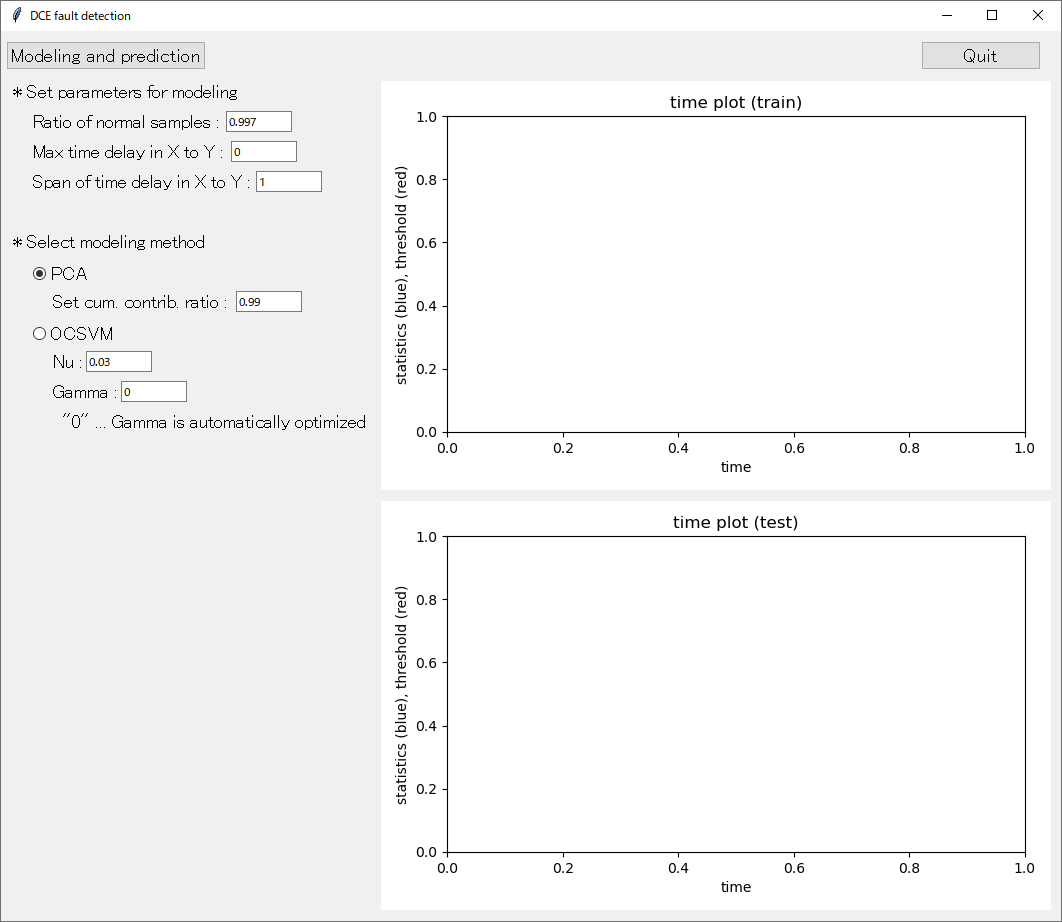
見つかりましたら、dce_soft_sensor.exe (もしくは dce_soft_sensor) をダブルクリックしてください。少し時間が経った後に、下のようなウィンドウが開くと思います。
同時に以下のような黒いウィンドウも開きますが、気にしなくて構いません (不具合が起きたときの原因探索に役立ち、問題ないときは特に使用しません)。
続いて DCE fault detection の設定についてです。まず DCE fault detection では、下図のような 「training_data.csv」 という名前のデータセットのファイルが必要です。
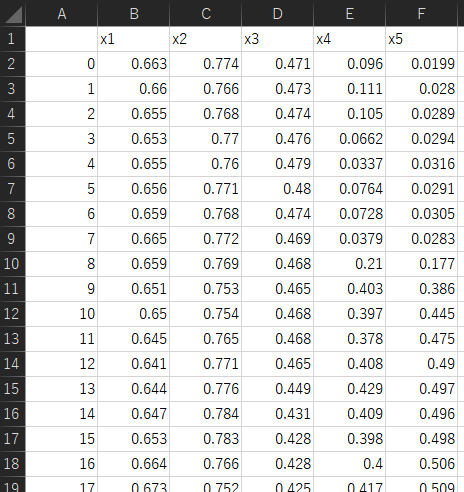
「training_data.csv」 の決まりごとは下の 6 つです。
- 新しい時刻ほど下になるようにサンプルを並べ、一番左の列 (A列) は、0, 1, 2, … と、0 から 1 ずつ増える値にする
- B 列以降を X にする
- training_data.csv を dce_soft_sensor.exe と同じフォルダに置く
次にウィンドウの 「* Set parameters for modeling」 についてです。「Ratio of normal samples :」 には、トレーニングデータのサンプルの内、正常データとみなすサンプル数の割合を設定してください。もちろん、基本的にすべて正常データと思いますが、異常か正常かを判定する閾値を設定するための設定です。その割合のサンプルのみが正常データに含まれるように、異常検出モデルの閾値が決定されます。
「Max time delay in X to Y :」 と 「Span of time delay in X to Y :」 で、Y に対する X の時間遅れを設定します。前者で最大の時間遅れを、後者で時間遅れの幅を設定します。例えば、「Max time delay in X to Y :」 が 10、「Span of time delay in X to Y :」 が 2 のときには、Y に対して 0, 2, 4, 6, 8, 10 だけ遅れた X の変数を使用することになります (0 は時間遅れなしです)。なお時間は time_series_data.csv における A 列の時刻に対応します。
「* Select modeling method」 では PCA か OCSVM を選択します。PCA を選択した場合は、「Set cum. contrib. ratio :」 で主成分の数を決めるための累積寄与率の値を設定します。この値を超える最初の主成分の数にします。
OCSVM を選択した場合は、「Nu :」 で ν の値を、「Gamma :」 で γ の値を設定します。γ については、0 とすることでこちらの方法で自動的に最適化することができます。

設定が終了したら、「Modeling and prediction」 をクリックして実行しましょう。PCA では T2 統計量・Q 統計量それぞれ、「Ratio of normal samples :」 のトレーニングデータのサンプルのみ正常データになるように閾値を設定します。そして、それぞれ閾値で割ることで閾値が 1 になるように変換します (scaled T2, scaled Q)。最後に、scaled T2 と scaled Q の最大値を異常検出のための指標 (statistics) にして、この値が 1 を超えたときに異常と診断します。なお、いろいろと変換していますが、本質的には T2 統計量か Q 統計量のどちらかが閾値を超えたときに異常と診断することと同じです。
OCSVM では、OCSVM モデルを構築した後、OCSVM モデルの出力に対して −1 をかけることで、(PCA と合わせて) 値が大きいほど異常になるようにします。そして、トレーニグデータの最小値を引くことで、値が 0 以上になるように変換しています (adjusted inverse OCSVM)。adjusted inverse OCSVM に対して、「Ratio of normal samples :」 のトレーニングデータのサンプルのみ正常データになるように閾値を設定します。そして、adjusted inverse OCSVM を閾値で割ることで閾値が 1 になるように変換し、これを異常検出のための指標 (statistics) にしています。
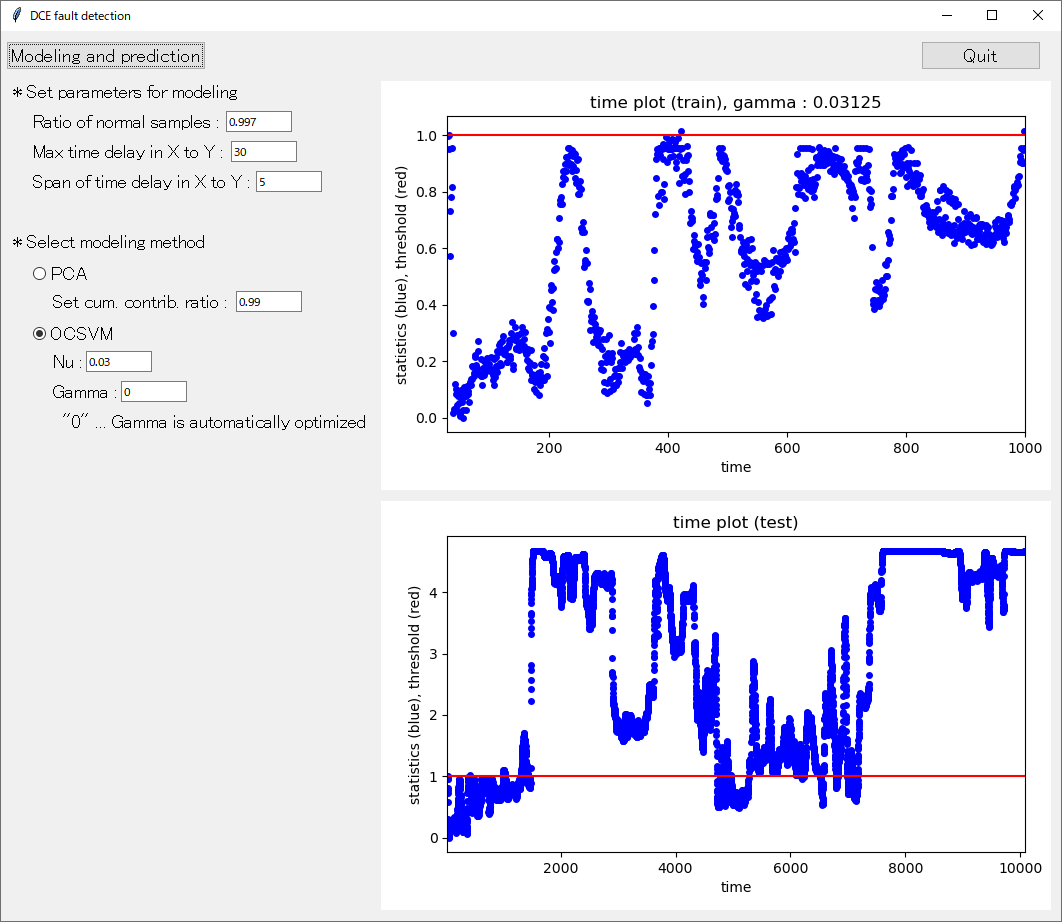
statistics はウィンドウの右上に横軸を時刻としてプロットされます。
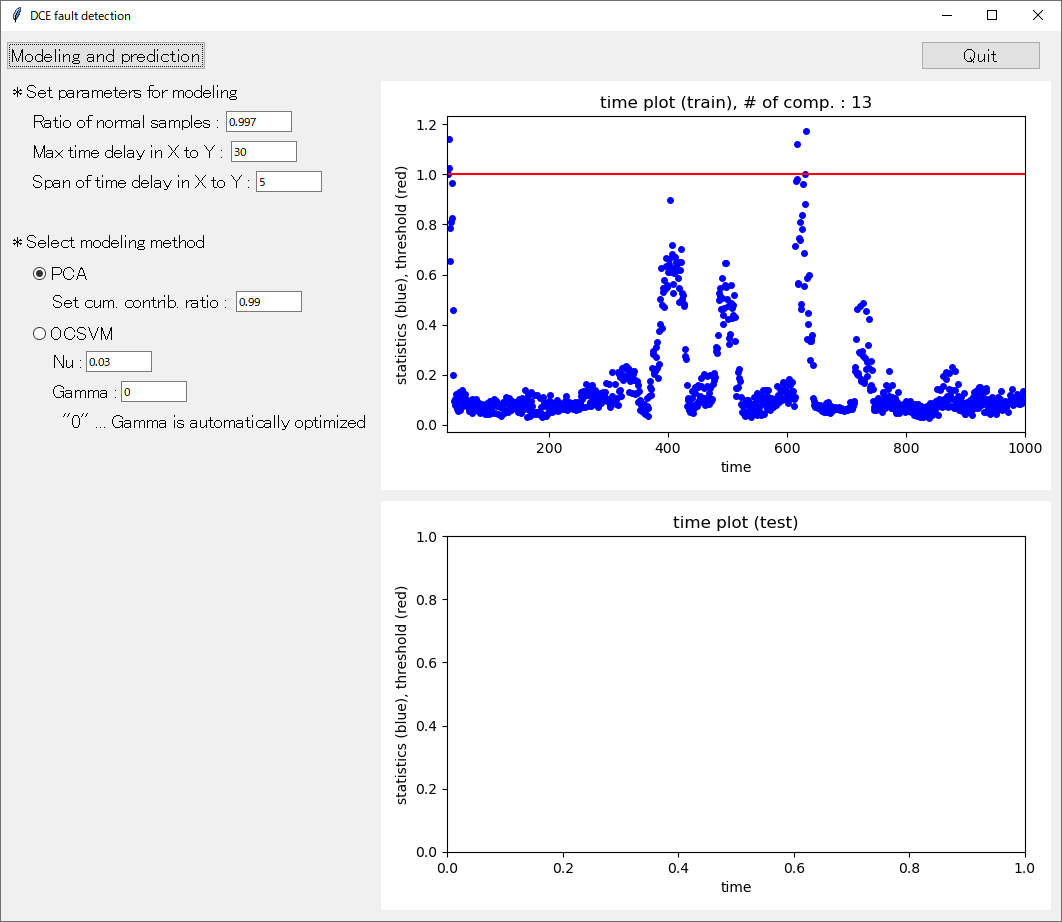
赤い線で表されている閾値を超えたサンプルが、異常と診断されたサンプルです。なお PCA を用いたときは、プロットのタイトルにおいて、「time plot (train),」 の右に 「# of comp. : 13」 として設定された主成分の数が表示されます。OCSVM を用いたときは、「gamma : 0.25」 のように用いられた γ の値が表示されます。
このプロットは statistics_plot_in_train_[手法の名前].png という名前の画像ファイルとして results フォルダに保存されます。その他、保存される csv ファイルの詳細は以下のとおりです。
- thresholds_[手法の名前].csv: PCA では T2 統計量と Q 統計量の閾値、OCSVM では adjusted inverse OCSVM の閾値があります
- statistics_train_[手法の名前].csv: トレーニングデータにおける、PCA では T2 統計量、Q 統計量、scaled T2、scaled Q、statistics が、OCSVM では adjusted inverse OCSVM と statistics がサンプルごとに計算された値があります
テストデータがあるときは、「training_data.csv」 と同じ形式で 「test_data.csv」 を準備してください (「test_data.csv」 は、なくても問題なく実行できます)。トレーニングデータで構築された異常検出モデルによって、推定された結果が、トレーニングデータと同様にして表示されたり、csv ファイルとして保存されたりします。
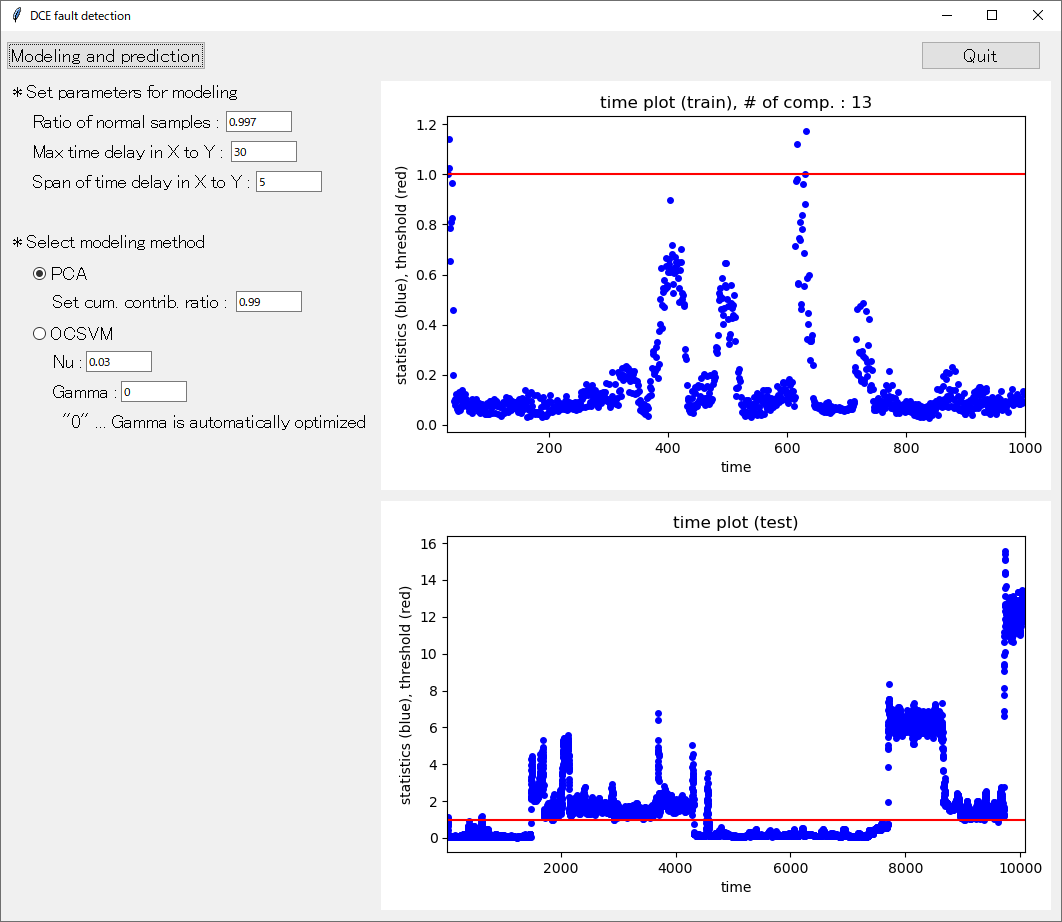
dce_fault_detection.exe があるフォルダに、「prediction」という名前のフォルダがあり、その中に new_samples.csv という csv ファイルがあります。この csv ファイルを更新すると、このファイルにある X のデータが異常か正常か、診断することができます。プラントや装置で測定されたデータを csv ファイルにすることで、そのデータから異常検出ができるわけです。
特徴量の名前 (x1, x2, x3, x4, x5) は、training_data.csv と new_samples.csv とでまったく同じにしてください。new_samples.csv の 1 列目の時刻は、0 からはじまる必要はありませんが、1 ずつ大きくなるようなデータセットにしてください。
「Modelling and prediction」 をクリックして異常検出モデルの構築をして、ウィンドウに結果が表示されます。この後に、「prediction」フォルダの new_samples.csv ファイルが更新されると (別の new_samples.csv ファイルで上書きしたり、ファイルの内容を書き換えたりすると)、new_samples.csv を読み込み、new_samples.csv の一番下の (時間的に最も新しい) X の値に対応する異常を推定します。推定した結果は 「results」 フォルダの statistics_new_[手法名].csv として保存されます。この中における statistics が 1 を超えていたら異常です。
DCE fault detection における最初の設定で X の時間遅れ変数を設定した場合は、予測するときも同じ X の時間遅れ変数が考慮されます。そのため、new_samples.csv には、予測したい時刻の X の値だけでなく、少なくとも最大の時間遅れ分の時間のデータを入れておいてください。
「prediction」フォルダの new_samples.csv ファイルが更新されるたびに、そのファイルを読み込んで 異常検出し、statistics_new_[手法名].csv として保存します。
最後に、DCE soft sensor を終了するときは、右上の × ボタンではなく 「Quit」 ボタンをクリックしてください。
ご自身のデータセットを、training_data.csv などと同様の形式で整理していただければ、このアプリで解析することができます。
なお最後になりますが、このアプリはモデルの適用範囲 (Applicability Domain, AD) の検討にも使えます。

training_data.csv を目的変数 Y の値がわかっている X のデータ (トレーニングデータ)、test_data.csv を Y の値がわからない新しいデータとすることで、statistics の値が 1 以下であれば AD 内、1 を超えていたら AD 外とできます。AD 設定に用いる場合は、「Max time delay in X to Y :」 を 0 にして、時間遅れ変数を考慮しないようにしてください。
以上が本アプリの説明になります。ぜひご活用いただき、異常検出や AD の検討のためのさらなるモチベーションにつなげていただければと思います。
以上です。
質問やコメントなどありましたら、twitter, facebook, メールなどでご連絡いただけるとうれしいです。

