
これまで化学データ・化学工学データのデータ解析に役立つツールや金子研で開発された手法に関する Python コードを Github にて公開してきました。このたびは、これらのツール・手法 (の一部) に加えて、新たな機能を追加して、DCEKit (Data Chemical Engineering toolkit) という形でリリースします!
Github: https://github.com/hkaneko1985/dcekit
PyPI: https://pypi.org/project/dcekit/
PyPI に登録しましたので、
pip install dcekit
とすれば簡単にインストールできます。たとえば Anaconda を使っている方は、Anaconda Prompt を起動して、
pip install dcekit
と入力して実行すれば OK です。Anaconda Prompt の起動の仕方についてはこちらをご覧ください。

こちらが DCEKit の取説です。

今後は、DCEKit に機能を追加する形で、引き続き研究・開発を行って参ります。DCEKit がどんどん拡張するわけですね。
Github のページには、DCEKit における各機能のデモンストレーションの Python コードやサンプルデータセットもありますので (これらのコードは pip install dcekit ではインストールされません)、DCEKit をインストールしてから、まずはそちらからお試しいただくのがよいと思います。
それでは、デモンストレーションの Python コードの案内を含めて、DCEKit の機能を紹介します。
Generative Topographic Mapping (GTM)
データの可視化手法の GTM を実行できます。GTM の詳細はこちらを御覧ください。
デモンストレーションとして、demo_gtm.py をお試しください。
k3n error (k–nearest neighbor normalized error for visualization and reconstruction)
GTM をはじめとして、可視化手法は教師なし学習ですので、可視化した結果を評価することが難しいです。これまでは主観での評価しかされていませんでした。そんな中、k3n error という、可視化した結果を評価する指標を開発しまして、
DCEKit にも搭載しました。
GTM のハイパーパラメータを最適化する k3n error のデモンストレーションとして、demo_opt_gtm_with_k3nerror.py をお試しください。
Sparse Generative Topographic Mapping (SGTM)
GTM はデータの可視化手法ですので、データのクラスタリングをしたいときは、k-means, 階層的クラスタリングなど、別途クラスタリングを行う必要があります。これは面倒ですし、可視化の手法とクラスタリング手法は別物ですので、基本的には可視化結果とクラスタリング結果とは整合性が取れません。そこで、GTM のアルゴリズムを改良して、データの可視化とクラスタリングを同時にできる手法 SGTM を開発しました。
SGTM も DCEKit に搭載されています。
デモンストレーションとして、demo_sgtm.py をお試しください。
Generative Topographic Mapping Regression (GTMR)
GTM を改良して回帰分析にも応用できるようにしまして、それにともない、モデルの逆解析やモデルの適用範囲の設定も同時にできるようになりました。

デモンストレーションとして、以下のものをお試しください。
- 回帰分析: demo_gtmr.py
- 回帰分析(目的変数が複数) : demo_gtmr_multi_y.py
- クロスバリデーション: demo_opt_gtmr_with_cv_multi_y.py
- モデルの逆解析: demo_inverse_gtmr.py
- モデルの逆解析(目的変数が複数): demo_inverse_gtmr_with_multi_y.py
Gaussian Mixture Regression (GMR)
もともとはクラスタリング手法であった Gaussian Mixture Models (GMM) を回帰分析にも応用できるようにした手法です。GTMR と同じく、モデルの逆解析やモデルの適用範囲の設定も同時にできますし、目的変数が複数あっても OK です。
デモンストレーションとして、以下のものをお試しください。
- 回帰分析・モデルの逆解析(目的変数が複数): demo_gmr.py
- クロスバリデーション: demo_gmr_with_cross_validation.py
さらに、こちらに書いたように

GMR により欠損値を補完することができます。デモンストレーションとして、demo_gmr_with_interpolation.py をお試しください。
midpoints between k-nearest-neighbor data points of a training dataset (midknn)
バリデーションデータをデータの中点で作成する方法です。クロスバリデーションの代わりに使うことができます。midknn の詳細はこちらをご覧ください。
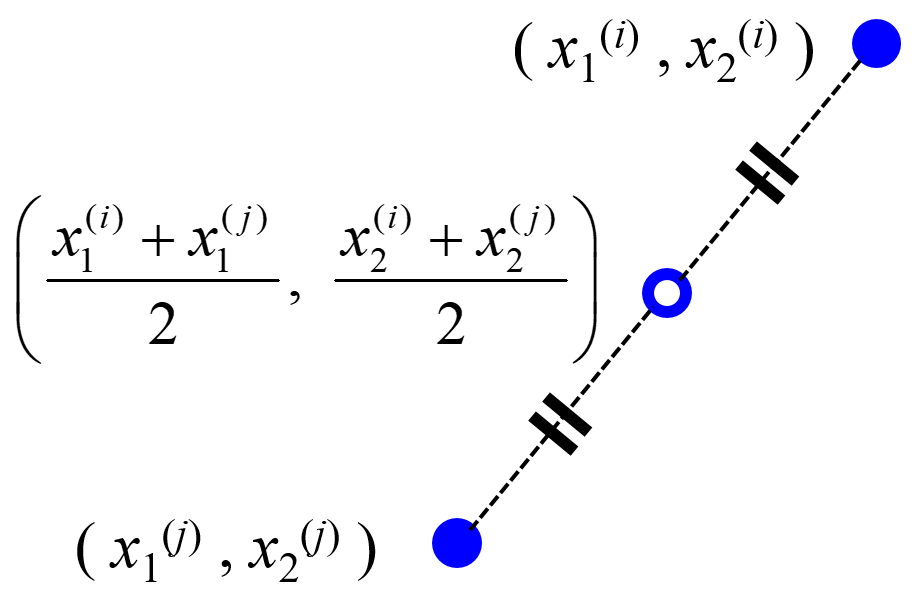
デモンストレーションとしてサポートベクター回帰 (Support Vector Regression, SVR) のハイパーパラメータの最適化に midknn を用いた例があります。demo_midknn_in_svr.py をお試しください。
サポートベクター回帰 (Support Vector Regression, SVR) のハイパーパラメータの高速最適化
こちらに書いた、SVR のハイパーパラメータの高速最適化です。

デモンストレーションとして、以下のものをお試しください。
- クロスバリデーションを用いた場合: demo_fast_opt_svr_hyperparams_cv.py
- midknn を用いた場合: demo_fast_opt_svr_hyperparams_midknn.py
Kennard-Stone アルゴリズムによるサンプル選択
こちらに書いたように
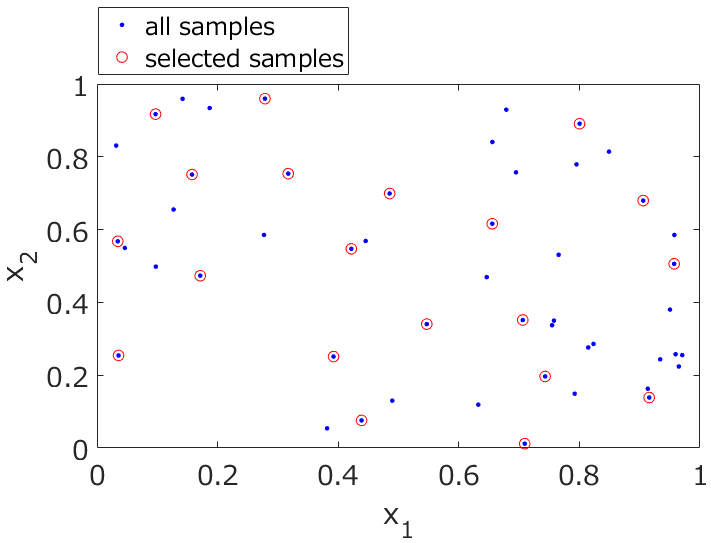
モデル構築用データ (トレーニングデータ) とモデル検証用データ (テストデータ) の分ける方法です。あるデータセットから、代表的なサンプルを選択することができます。
デモンストレーションとして、demo_kennard_stone.py をお試しください。
ダブルクロスバリデーション (Double Cross-Validation, DCV)
サンプル数が小さいときの、回帰分析手法・クラス分類手法を評価する方法であるダブルクロスバリデーション (Double Cross-Validation, DCV) です。

scikit-learn の GridSearchCV のオブジェクトさえ準備すれば、DCV を実行できますので、応用しやすいと思います。
PLS を対象とした DCV のデモンストレーションとして demo_double_cross_validation_for_pls.py をお試しください。
y-randomization
モデルの逆解析などに用いる最終的なモデルに、Chance Correlation (偶然の相関) がどれだけ潜んでいるか確認する y-randomization です。

ガウス過程回帰 GP や線形重回帰分析OLS のようにハイパーパラメータのない手法に関しては、デモンストレーションとして demo_y_randomization.py をお試しください。
ハイパーパラメータのない手法に関しても、DCV と同じように scikit-learn の GridSearchCV のオブジェクトさえ準備すれば、y-randomization を実行できますので、応用しやすいと思います。デモンストレーションとして demo_y_randomization_with_hyperparameter.py をお試しください。
Chance Correlation‐Excluded Mean Absolute Error (MAECCE)
y-randomization を活用して、テストデータのMAEをトレーニングデータから推定する方法です。

こちらも scikit-learn の GridSearchCV のオブジェクトさえ準備すれば、y-randomization を実行できますので、応用しやすいと思います。デモンストレーションとして demo_maecce_for_pls.py をお試しください。
r2 based on the latest measured y-values (r2LM)
時系列データ用の r2 です。

デモンストレーションは次の LWPLS のデモンストレーションをご覧ください。
Locally-Weighted Partial Least Squares (LWPLS, 局所PLS)
PLSが非線形性に対応した手法です。ソフトセンサーにおいて just-in-time モデリングの 1 つです。scikit-learn に準拠していますので、cross_val_predict や GridSearchCV を使えます。
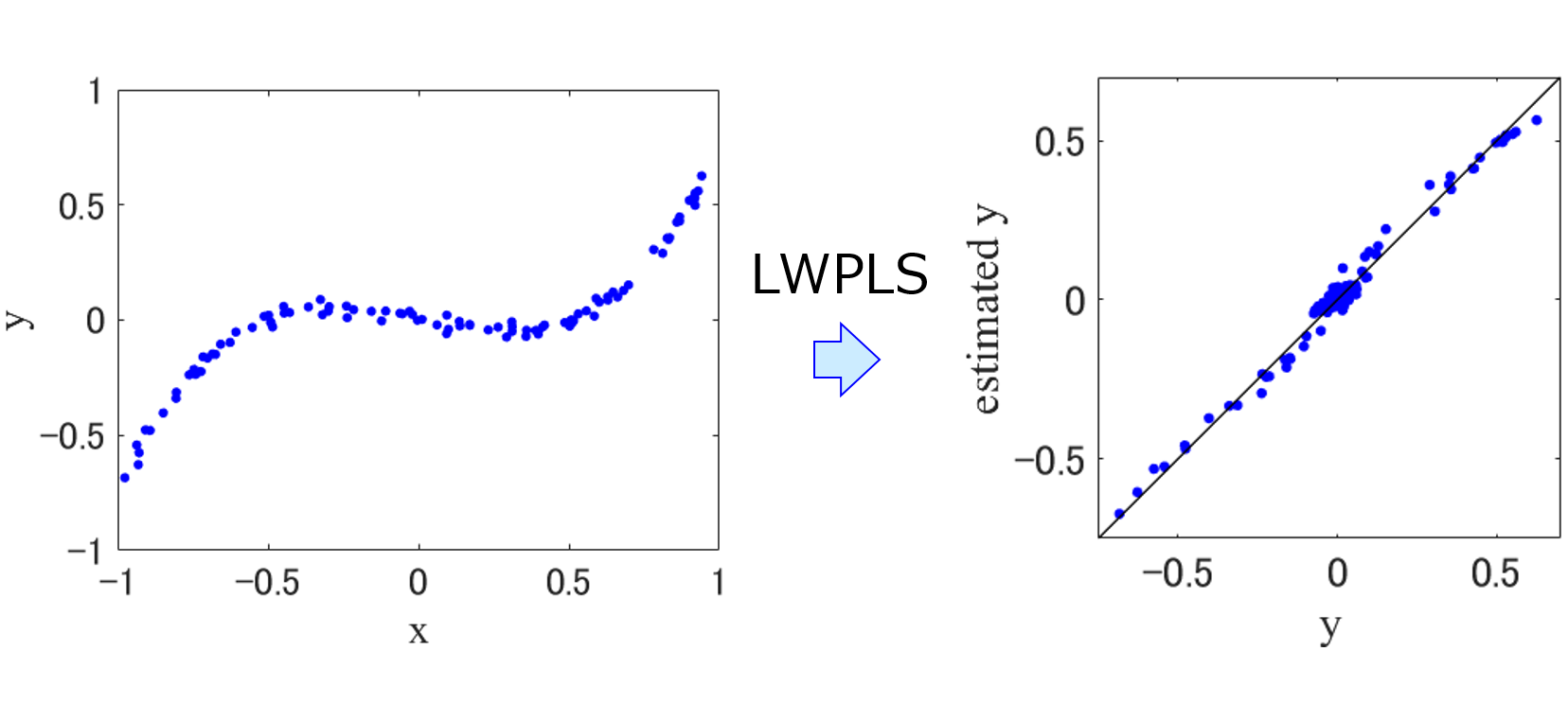
デモンストレーションとして demo_lwpls_r2lm.py をお試しください。LWPLS で時系列データの解析を行うデモンストレーション demo_time_series_data_analysis_lwpls_r2lm.py もあります。
相関係数 r に基づく変数選択・変数のクラスタリング
こちらの相関係数で変数選択したり変数のクラスタリングをしたりする方法です。

相関係数の高い変数を選択するデモンストレーションとして demo_search_highly_correlated_variables.py を、相関係数でクラスタリングするデモンストレーションとして demo_clustering_based_on_correlation_coefficients.py をご覧ください。
ベイズ最適化 (Bayesian Optimization, BO)
次元削減による半教師あり学習 (Semi-Supervised Learning) + AD による教師なしサンプルの選択
scikit-learn に準拠していますので、cross_val_predict や GridSearchCV を使えます。
- demo_semi_supervised_learning_low_dim_no_hyperparameters.py (GP, OLS のようにハイパーパラメータのないモデリング手法)
- demo_semi_supervised_learning_low_dim_no_hyperparameters_with_ad.py (GP, OLS のようにハイパーパラメータのないモデリング手法、AD を考慮して教師なしデータを選択)
- demo_semi_supervised_learning_low_dim_with_hyperparameters.py (PLS, SVR のようにハイパーパラメータがあるモデリング手法)
- demo_semi_supervised_learning_low_dim_with_hyperparameters_with_ad.py (PLS, SVR のようにハイパーパラメータがあるモデリング手法、AD を考慮して教師なしデータを選択)
があります!
サンプルを転移するタイプの転移学習 (Transfer Learning)
scikit-learn に準拠していますので、cross_val_predict や GridSearchCV を使えます。

- demo_transfer_learning_no_hyperparameters.py (GP, OLS のようにハイパーパラメータのないモデリング手法)
- demo_transfer_learning_with_hyperparameters.py (PLS, SVR のようにハイパーパラメータがあるモデリング手法)
があります!
バギングによるアンサンブル学習 (Ensemble Learning based on Bagging)
scikit-learn に準拠していますので、cross_val_predict や GridSearchCV を使えます。scikit-learn の BaggingRegressor や BaggingClassifier と比べて、サブモデルのハイパーパラメータもクロスバリデーションで最適化できたり、predict で推定値の標準偏差を計算できたりします。

- demo_bagging_regression_no_hyperparameters.py (GP, OLS のようにハイパーパラメータのない回帰分析手法)
- demo_bagging_regression_with_hyperparameters.py (PLS, SVR のようにハイパーパラメータがある回帰分析手法)
- demo_bagging_classification_no_hyperparameters.py (LDA のようにハイパーパラメータのないクラス分類手法)
- demo_bagging_classification_with_hyperparameters.py (SVM のようにハイパーパラメータがあるクラス分類手法)
があります!
アンサンブル学習に基づく外れサンプル検出 (Ensemble Learning Outlier sample detection, ELO)
- demo_elo_pls.py (PLS のアンサンブル)
があります!
モデルの適用範囲・適用領域 (Applicability Domain, AD) [データ密度]

- demo_ad.py (回帰分析手法は GP)
があります!
今後も DCEKit を拡張していく予定です。拡張次第、ご案内いたします。引き続きよろしくお願いいたします!
以上です。
質問やコメントなどありましたら、twitter, facebook, メールなどでご連絡いただけるとうれしいです。