就活と大学院進学に関する座談会2020 今年も就活と大学院進学に関する座談会をやりました。ただ今回は状況が状況なので、Skype でつないだオンラインでの座談会です。ちなみに昨年度の様子はこちらをご覧ください。学生たちに質問したのは以下の内容です。 どうして就活したか? どうして... 2020.04.05 研究室雑記
金子研で人を雇うときの観点 もし金子研究室で人を雇うとしたら、どのような観点で人を選ぶか、のお話をします。就活でどのような人が求められるかの参考にしていただけたらと思います。もちろん、100 の企業があれば 100 以上の考え方がありますので、その中の一つくらいにお考... 2020.03.29 研究室雑記
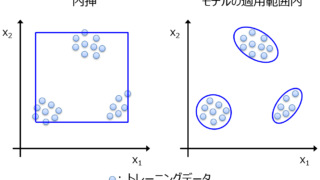
内挿・外挿は、モデルの適用範囲内・適用範囲外と違いますので注意が必要です 回帰分析やクラス分類によって構築された、目的変数 Y と説明変数 X との間のモデル Y = f(X) についてです。モデルについて議論するとき、モデルはデータの外挿は予測できない、内挿しか予測できない、とか、その予測結果は内挿なの?外挿な... 2020.03.29 ケモインフォマティクスケモメトリックスデータ解析プロセス制御・プロセス管理・ソフトセンサー研究室
[法人向け] 機械学習・データ解析・化学構造の扱い・Pythonに関するハンズオンセミナー (体験学習) の動画 これまで、いろいろな企業やセミナーにおいて、ケモインフォマティクス・マテリアルズインフォマティクス・プロセスインフォマティクスの講義や、Python のハンズオンセミナーを行って参りまして、そのような経験・実績をふまえて、以下の動画を作成い... 2020.03.22 ケモインフォマティクスケモメトリックスデータ解析プログラミングプロセス制御・プロセス管理・ソフトセンサー化学工学
研究成果をあげること、ではなく、研究成果をあげ続ける力を身につけること。金子研の方針です データ化学工学研究室 (金子研) の方針として、学生の成長を一番に考えています。配属になる学生に最初に伝えていることは、金子研で目指していることは、学生が研究成果をあげること、ではなく、学生が研究成果をあげ続ける力をつけることということです... 2020.03.15 研究室雑記
モデルの精度が低いときも、モデルの逆解析ってやるべき? いろいろと共同研究やコンサルティングをしていますとやはり多いのは、モデルの逆解析です。新たな分子を設計したり、新たな材料を作るための実験レシピやプロセスを設計したり、装置を設計したりといった話です。モデルの逆解析をするためには、もちろんモデ... 2020.03.15 ケモインフォマティクスケモメトリックスデータ解析プロセス制御・プロセス管理・ソフトセンサー研究室
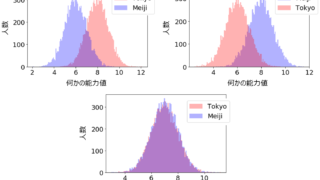
東大生と明大生、その違いとは? 大学ごとに学生を区別するのが妥当かどうかはさておき、少なくとも世間からは “東京大学の学生” とか ”明治大学の学生” という目で見られますので (たとえば就活とか)、その違いについて話したいと思います。東京大学の学生を “東大生”、明治大... 2020.03.08 雑記
ベイズ最適化において一度に複数の実験をするときに候補を選択するシンプルな方法 ベイズ最適化において、複数の実験候補を選択するお話です。ベイズ最適化についてはこちらをご覧ください。ベイズ最適化では、以下の 1. – 4. を繰り返すことで、物性や活性などの目的変数 Y が向上したり目標値を達成したりできる、実験条件など... 2020.03.08 ケモインフォマティクスケモメトリックスデータ解析プロセス制御・プロセス管理・ソフトセンサー研究室
2019新型コロナウイルス(SARS-CoV-2)による変化をメモしておきます 2019新型コロナウイルス (SARS-CoV-2) による情勢のため、わたしたちの生活はいろいろと変化したと思います。店頭やネットショップからマスク・トイレットペーパーが消えたり、色々なイベントが中止になったりしました。早く状況が落ち着く... 2020.03.01 雑記
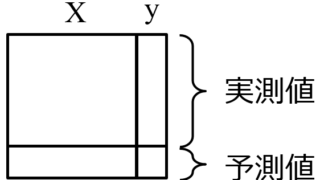
[Pythonコードあり] 特徴量ごとや特徴量間に制限があるときの、モデルの逆解析用のサンプル生成 回帰モデルやクラス分類モデルを構築した後の、モデルの逆解析の話です。上の 既存のサンプルの分布に従うように、モデルの逆解析用のサンプルをたくさん生成する方法 では、既存のサンプルのデータ分布を求めて、その分布に従うようにして新たなサンプルを... 2020.03.01 ケモインフォマティクスケモメトリックスデータ解析プログラミングプロセス制御・プロセス管理・ソフトセンサー研究室