高分子化合物を対象とした合成反応予測モデル(構造生成)&逆合成反応予測モデルを開発しました![金子研論文] 金子研の論文が Macromolecular Theory and Simulations に掲載されましたので、ご紹介します。タイトルはRetrosynthetic and Synthetic Reaction Prediction Mo... 2023.04.02 ケモインフォマティクスケモメトリックスデータ解析研究室論文
特徴量(変数)の重要度や目的変数の寄与はどのように検証するか 分子設計・材料設計・プロセス設計・プロセス管理において、分子記述子・実験条件・合成条件・製造条件・評価条件・プロセス条件・プロセス変数などの特徴量 x と分子・材料の物性・活性・特性や製品の品質などの目的変数 y との間で数理モデル y =... 2023.03.26 ケモインフォマティクスケモメトリックスデータ解析プロセス制御・プロセス管理・ソフトセンサー研究室
予測値+モデルの適用範囲か、ベイズ最適化か、直接的逆解析か 分子設計・材料設計・プロセス設計・プロセス管理において、分子記述子・実験条件・合成条件・製造条件・評価条件・プロセス条件・プロセス変数などの特徴量 x と分子・材料の物性・活性・特性や製品の品質などの目的変数 y との間で数理モデル y =... 2023.03.26 ケモインフォマティクスケモメトリックスデータ解析プロセス制御・プロセス管理・ソフトセンサー研究室
Datachemical LAB は他のソフトウェアと何が違うのか?~9つの大きなポイント~ いつも Datachemical LAB をご利用いただきありがとうございます。Datachemical LAB の利用を検討するとき、他のデータ解析・機械学習のソフトウェアと何が違うのか、気になる方もいらっしゃると思います。Datache... 2023.03.19 ケモインフォマティクスケモメトリックスデータ解析プロセス制御・プロセス管理・ソフトセンサー化学工学
yが0(もしくは1)の削除したサンプルをどう使うか? 分子設計・材料設計・プロセス設計・プロセス管理において、分子記述子・実験条件・合成条件・製造条件・評価条件・プロセス条件・プロセス変数などの特徴量 x と分子・材料の物性・活性・特性や製品の品質などの目的変数 y との間で数理モデル y =... 2023.03.19 ケモインフォマティクスケモメトリックスデータ解析プロセス制御・プロセス管理・ソフトセンサー研究室
(回帰モデルと比べて)クラス分類モデルで注意すること 分子設計・材料設計・プロセス設計・プロセス管理において、分子記述子・実験条件・合成条件・製造条件・評価条件・プロセス条件・プロセス変数などの特徴量 x と分子・材料の物性・活性・特性や製品の品質などの目的変数 y との間で数理モデル y =... 2023.03.12 ケモインフォマティクスケモメトリックスデータ解析プロセス制御・プロセス管理・ソフトセンサー研究室
Datachemical LABでクラス分類のモデル最適化と予測ができるようになりました いつも Datachemical LAB をご利用いただきありがとうございます。これまでご紹介させていただいた通り、Datachemical LAB を使用することで、データの前処理・データの可視化・回帰分析・モデルの逆解析・モデルの適用範... 2023.03.12 ケモインフォマティクスケモメトリックスデータ解析プログラミングプロセス制御・プロセス管理・ソフトセンサー
モデルの解釈の結果とドメイン知識(化学的背景・物理的背景等)とが合わないときはどうするか 分子設計・材料設計・プロセス設計・プロセス管理において、分子記述子・実験条件・合成条件・製造条件・評価条件・プロセス条件・プロセス変数などの特徴量 x と分子・材料の物性・活性・特性や製品の品質などの目的変数 y との間で数理モデル y =... 2023.03.05 ケモインフォマティクスケモメトリックスデータ解析プロセス制御・プロセス管理・ソフトセンサー研究室
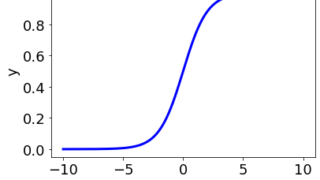
ロジスティック回帰(Logistic Regression)~名前は回帰だけど目的はクラス分類~ ロジスティック回帰 (Logistic Regression, LR) について、pdf とパワーポイントの資料を作成しました。LR の計算方法について説明されています。pdfもスライドも自由にご利用ください。pdfファイルはこちらから、パ... 2023.02.28 ケモインフォマティクスケモメトリックスデータ解析プロセス制御・プロセス管理・ソフトセンサー研究室
合成条件から材料の物性・活性や製品品質まで複数のモデルで繋ぐ 分子設計・材料設計・プロセス設計・プロセス管理において、分子記述子・実験条件・合成条件・製造条件・評価条件・プロセス条件・プロセス変数などの特徴量 x と分子・材料の物性・活性・特性や製品の品質などの目的変数 y との間で数理モデル y =... 2023.02.26 ケモインフォマティクスケモメトリックスデータ解析プロセス制御・プロセス管理・ソフトセンサー研究室