ランダムフォレスト(Random Forest, RF)について、pdfとパワーポイントの資料を作成しました。データセットが与えられたときに、RFで何ができるか、RFをどのように計算するかが説明されています。pdfもスライドも自由にご利用ください。
pdfファイルはこちらから、パワーポイント(pptx)ファイルはこちらからダウンロードできます。
興味のある方はぜひ参考にしていただき、どこかで使いたい方は遠慮なくご利用ください。
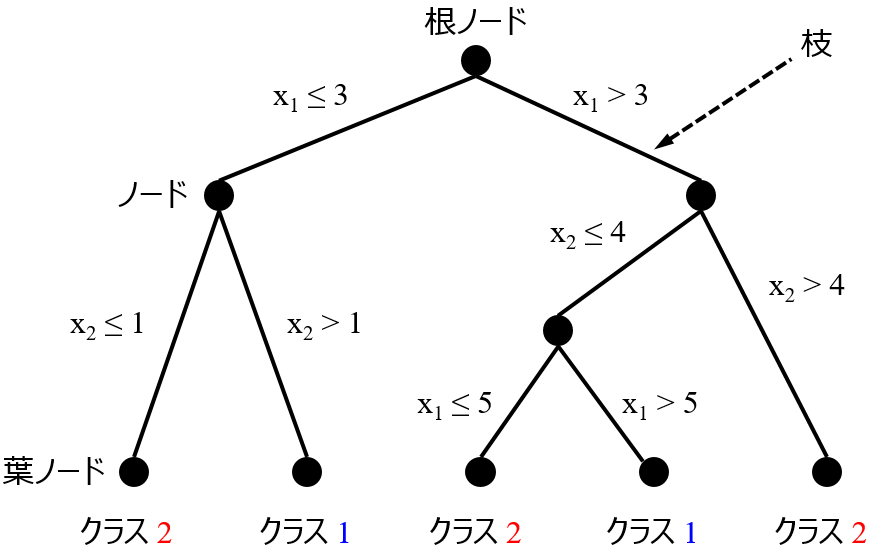
RFの概要
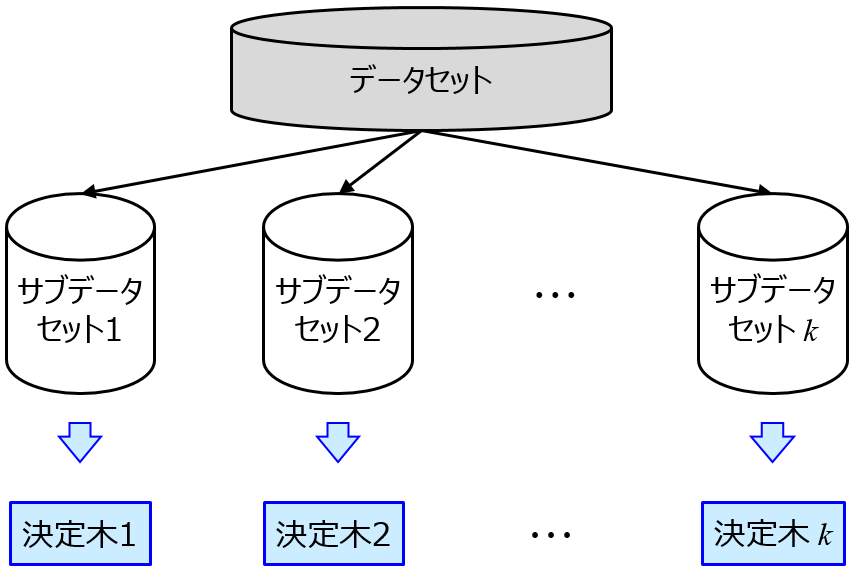
- サンプルと説明変数とをランダムにサンプリングして、決定木をたくさん作る
- 複数の決定木の推定結果を統合して、最終的な推定値とする
- アンサンブル(集団)学習 (Ensemble learning) の1つ
- 決定木と比べて精度は高くなることが多いが、モデルを解釈することは難しい
- 回帰分析にもクラス分類にも使える
- 説明変数の重要度を議論できる
スライドのタイトル
- Random Forest (RF) とは?
- RFの概略図
- どのようにサブデータセットを作るか?
- サブデータセットの数・説明変数の数はどうする?
- どのように推定結果を統合するか?
- 説明変数 (記述子) の重要度
- Out-Of-Bag (OOB)
- OOBを用いた説明変数 (記述子) の重要度
- 決定木の設定はどうする?
参考資料
- 金 明哲, Rによるデータサイエンス~データ解析の基礎から最新手法まで~, 森北出版 (2007)
RFのPythonのプログラムは、こちらの課題16をご参照ください。
以上です。
質問・コメントがありましたら、twitter・facebook・メールなどを通して教えていただけるとうれしいです。