モデリングを工夫することで、すべてのデータを活用しよう! 分子設計・材料設計・プロセス設計・プロセス管理において、分子記述子・実験条件・合成条件・製造条件・評価条件・プロセス条件・プロセス変数などの特徴量 x と分子・材料の物性・活性・特性や製品の品質などの目的変数 y との間で数理モデル y =... 2023.10.15 ケモインフォマティクスケモメトリックスデータ解析研究室
手動・自動の特徴量エンジニアリングの考え方 分子設計・材料設計・プロセス設計・プロセス管理において、分子記述子・実験条件・合成条件・製造条件・評価条件・プロセス条件・プロセス変数などの特徴量 x と分子・材料の物性・活性・特性や製品の品質などの目的変数 y との間で数理モデル y =... 2023.10.08 ケモインフォマティクスケモメトリックスデータ解析プロセス制御・プロセス管理・ソフトセンサー研究室
小嗣真人 氏を明治大学生田キャンパスにお招きして講演していただきました 2023年10月3日(火)に、東京理科大学先進工学部マテリアル創成工学科で教授をされている 小嗣真人 氏を明治大学生田キャンパスにお招きしまして、拡張型自由エネルギーモデルを用いた材料機能の最適化に関するご講演をしていただきました。小嗣先生... 2023.10.08 ケモインフォマティクスケモメトリックスデータ解析研究室
目的変数yとの相関では説明変数xを選択しません!選択するときは多変量解析で! 分子設計・材料設計・プロセス設計・プロセス管理において、分子記述子・実験条件・合成条件・製造条件・評価条件・プロセス条件・プロセス変数などの特徴量 x と分子・材料の物性・活性・特性や製品の品質などの目的変数 y との間で数理モデル y =... 2023.10.01 ケモインフォマティクスケモメトリックスデータ解析プロセス制御・プロセス管理・ソフトセンサー研究室
説明変数の上限・下限はデータ解析・機械学習では決まりません!決めるときは実験系・シミュレーション系で! 分子設計・材料設計・プロセス設計・プロセス管理において、分子記述子・実験条件・合成条件・製造条件・評価条件・プロセス条件・プロセス変数などの特徴量 x と分子・材料の物性・活性・特性や製品の品質などの目的変数 y との間で数理モデル y =... 2023.10.01 ケモインフォマティクスケモメトリックスデータ解析プロセス制御・プロセス管理・ソフトセンサー研究室
機械学習モデルの逆解析の評価は、実験(もしくはそれに代わるシミュレーション)でしかできません 分子設計・材料設計・プロセス設計・プロセス管理において、分子記述子・実験条件・合成条件・製造条件・評価条件・プロセス条件・プロセス変数などの特徴量 x と分子・材料の物性・活性・特性や製品の品質などの目的変数 y との間で数理モデル y =... 2023.09.24 ケモインフォマティクスケモメトリックスデータ解析プロセス制御・プロセス管理・ソフトセンサー研究室
「組成データ解析入門―パーセント・データの問題点と解析方法―」 和が100や1になるデータを扱う際の注意点と対処法 太田亨 著, 「組成データ解析入門―パーセント・データの問題点と解析方法―」, 朝倉書店, 2023朝倉書店: Amazon: 組成データのように、0 から 1 まででいくつかの和が 1 になるようなデータを扱う際の注意点と対処法を学べる本... 2023.09.24 ケモインフォマティクスケモメトリックスデータ解析研究室
収率0から新たな反応の開拓に成功しました![理化学研究所&金子研の共同研究論文] 理化学研究所と金子研における共同研究の成果の論文が Journal of Chemical Information and Modeling に掲載されましたので、ご紹介します。タイトルはCatalyst Design and Featur... 2023.09.17 ケモインフォマティクスケモメトリックスデータ解析研究室論文
「化学のためのPythonによるデータ解析・機械学習入門(改訂2版)」 正誤表 タイトルの書籍をすでにお読みいただいた方々から、ご質問やご指摘をいただいております。感謝申し上げます。そこでいただいたご指摘から、間違えがあることもわかりましたので、正誤リストとして以下にまとめます。申し訳ございませんが、よろしくお願いいた... 2023.09.11 ケモインフォマティクスケモメトリックスデータ解析プログラミングプロセス制御・プロセス管理・ソフトセンサー化学工学研究室
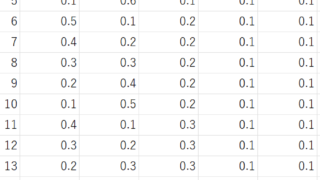
[ダウンロード可能] 網羅的な組成データのcsvファイルを共有します! 分子設計・材料設計・プロセス設計・プロセス管理において、分子記述子・実験条件・合成条件・製造条件・評価条件・プロセス条件・プロセス変数などの特徴量 x と分子・材料の物性・活性・特性や製品の品質などの目的変数 y との間で数理モデル y =... 2023.09.10 ケモインフォマティクスケモメトリックスデータ解析研究室