四年生たちがモデルの逆解析をした資料を金子研オンラインサロンに公開します(2019年度) 金子研ゼミ合宿における四年生の課題はモデルの逆解析です。逆解析するテーマは自由に決めて OK としていまして、自分の研究テーマに関するものもありますが、いろいろなテーマがあります。データを出せないものを除いて、ざっと紹介します。沸点の測定さ... 2019.10.06 ケモインフォマティクスケモメトリックスプロセス制御・プロセス管理・ソフトセンサー研究室
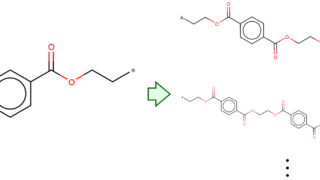
[高分子設計]モノマーの構造から二量体・三量体・・・を生成するPythonプログラムを作りましたのでぜひご活用ください こちらの Github にモノマーの構造から多量体を作成するPythonプログラム make_repeating_unit_homo.py を共有します。まず、モノマーの構造を monomer.mol という mol ファイルを準備します。... 2019.09.29 ケモインフォマティクスプログラミング研究室
人を成長させる人工知能 以前に、人工知能が本質的に何をしているかを書きました。人工知能をつくったら、それを使わない手はありません。うまく使うことで、人工知能によって人が成長できるようになります。たとえば高機能性材料を開発しているとき、実験条件 x を決めて、実験し... 2019.09.22 ケモインフォマティクスケモメトリックスデータ解析プロセス制御・プロセス管理・ソフトセンサー研究室
[デモのプログラムあり] ガウス過程回帰(Gaussian Process Regression, GPR)におけるカーネル関数を11個の中から最適化する (scikit-learn) こちらのガウス過程による回帰 (Gaussian Process Regression, GPR)において、カーネル関数をどうするか、というお話です。そもそも GPR のカーネル関数はサポートベクター回帰 (Support Vector R... 2019.09.16 ケモインフォマティクスケモメトリックスデータ解析プロセス制御・プロセス管理・ソフトセンサー研究室
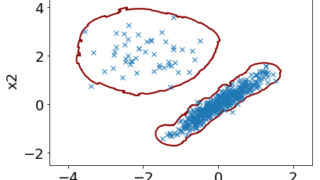
[デモのプログラムあり] Local Outlier Factor (LOF) によるデータ密度の推定・外れサンプル(外れ値)の検出・異常検出 Local Outlier Factor (LOF) について、パワーポイントの資料とその pdf ファイルを作成しました。LOF は k-nearest neighbor algorithm (k-NN) の発展版のようなもので、データ密... 2019.09.15 ケモインフォマティクスケモメトリックスデータ解析プロセス制御・プロセス管理・ソフトセンサー研究室
データ解析・機械学習のしやすいデータセットの作り方 データ化学工学研究室 (金子研) では、分子のデータや材料のデータやプロセスの時系列データなど、化学データ・化学工学データを扱ってデータ解析・機械学習をしています。データ解析の基本的な流れは、ある程度固まっていることから、データ解析を成功さ... 2019.09.10 ケモインフォマティクスケモメトリックスデータ解析プロセス制御・プロセス管理・ソフトセンサー研究室
人工知能は本質的に何をしているのか データ化学工学研究室 (金子研) では、基本的に化学データ・化学工学データを用いて、データ解析・統計解析・機械学習によって、数理モデル・数値モデル (人工知能) を作ったり、それを有効に使ったりする研究をしています。人工知能を作ところのイメ... 2019.09.08 ケモインフォマティクスケモメトリックスデータ解析プロセス制御・プロセス管理・ソフトセンサー研究室
DCEKit にバギングによるアンサンブル学習の機能を追加!scikit-learn の BaggingRegressor や BaggingClassifier との違いとは? データ解析・機械学習のためのツールキット DCEKit にバギングによるアンサンブル学習の機能を追加しました。アンサンブル学習というのは、回帰モデルだったりクラス分類モデルだったり、モデルをたくさん作って推定性能を上げよう!、といった手法で... 2019.09.02 ケモインフォマティクスケモメトリックスデータ解析プログラミングプロセス制御・プロセス管理・ソフトセンサー研究室
ポリマーとモノマーのデータセットがあれば、こんなことができるようになりました! [金子研論文] 昨年度の金子研の四年生が主に研究していたテーマの成果が、Journal of Computer Chemistry, Japan にて論文公開になりました。タイトルは高屈折率および高ガラス転移温度をもつ高分子材料のモノマー設計です。下の U... 2019.09.01 ケモインフォマティクスケモメトリックスデータ解析化学工学研究室研究発表論文
設計の目的は問題解決 設計の目的は設計することではなくて、何かしらの問題を解決することです。あたりまえのことかもしれませんが、少しお話しします。いろいろな設計問題があります。分子・化学構造を設計したり、材料の作り方 (実験条件・製造条件) を設計したり、プロセス... 2019.08.25 ケモインフォマティクスケモメトリックスデータ解析プロセス制御・プロセス管理・ソフトセンサー研究室