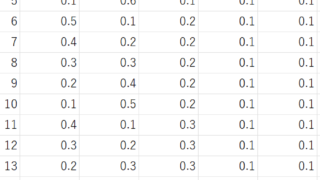
[ダウンロード可能] 網羅的な組成データのcsvファイルを共有します! 分子設計・材料設計・プロセス設計・プロセス管理において、分子記述子・実験条件・合成条件・製造条件・評価条件・プロセス条件・プロセス変数などの特徴量 x と分子・材料の物性・活性・特性や製品の品質などの目的変数 y との間で数理モデル y =... 2023.09.10 ケモインフォマティクスケモメトリックスデータ解析研究室
モデルの逆解析のための仮想的な時系列データを自動生成する手法を開発しました![金子研論文] 金子研の論文が Case Studies in Chemical and Environmental Engineering に掲載されましたので、ご紹介します。タイトルはT-Gen: Time series data generator ... 2023.09.10 ケモメトリックスデータ解析プロセス制御・プロセス管理・ソフトセンサー化学工学研究室論文
DFT計算を用いて複数の記述子セットを準備しておくことでベイズ最適化の探索性能の向上に成功しました![金子研論文] 金子研の論文が ACS Omega に掲載されましたので、ご紹介します。タイトルはEnhancing the Search Performance of Bayesian Optimization by Creating Different... 2023.09.03 ケモインフォマティクスケモメトリックスデータ解析研究室論文
[無料公開] 「化学のためのPythonによるデータ解析・機械学習入門(改訂2版)」の“改訂版の発行にあたって”、詳細な目次、第8章の一部 2023 年 8 月 30 日に、金子弘昌著の「化学のためのPythonによるデータ解析・機械学習入門(改訂2版)」が出版されました。オーム社: Amazon: こちらは、以前に出版した書籍 「化学のための Pythonによるデータ解析・機... 2023.08.27 ケモインフォマティクスケモメトリックスデータ解析プログラミングプロセス制御・プロセス管理・ソフトセンサー化学工学研究室
モデルの逆解析はxの唯一の解を求めることではありません、ご注意ください 分子設計・材料設計・プロセス設計・プロセス管理において、分子記述子・実験条件・合成条件・製造条件・評価条件・プロセス条件・プロセス変数などの特徴量 x と分子・材料の物性・活性・特性や製品の品質などの目的変数 y との間で数理モデル y =... 2023.08.20 ケモインフォマティクスケモメトリックスデータ解析プロセス制御・プロセス管理・ソフトセンサー研究室
ベイズ最適化のときカーネル関数に線形項を入れると外挿の方向を定めやすい 分子設計・材料設計・プロセス設計・プロセス管理において、分子記述子・実験条件・合成条件・製造条件・評価条件・プロセス条件・プロセス変数などの特徴量 x と分子・材料の物性・活性・特性や製品の品質などの目的変数 y との間で数理モデル y =... 2023.08.20 ケモインフォマティクスケモメトリックスデータ解析プロセス制御・プロセス管理・ソフトセンサー研究室
実験結果が人依存のデータ解析・機械学習の考え方 分子設計・材料設計・プロセス設計・プロセス管理において、分子記述子・実験条件・合成条件・製造条件・評価条件・プロセス条件・プロセス変数などの特徴量 x と分子・材料の物性・活性・特性や製品の品質などの目的変数 y との間で数理モデル y =... 2023.08.13 ケモインフォマティクスケモメトリックスデータ解析プロセス制御・プロセス管理・ソフトセンサー研究室
過学習(オーバーフィッティング)にとらわれない! 分子設計・材料設計・プロセス設計・プロセス管理において、分子記述子・実験条件・合成条件・製造条件・評価条件・プロセス条件・プロセス変数などの特徴量 x と分子・材料の物性・活性・特性や製品の品質などの目的変数 y との間で数理モデル y =... 2023.08.13 ケモインフォマティクスケモメトリックスデータ解析プロセス制御・プロセス管理・ソフトセンサー研究室
今のハイパーパラメータの決め方が本当に正しいのか不安になったときの対処法 分子設計・材料設計・プロセス設計・プロセス管理において、分子記述子・実験条件・合成条件・製造条件・評価条件・プロセス条件・プロセス変数などの特徴量 x と分子・材料の物性・活性・特性や製品の品質などの目的変数 y との間で数理モデル y =... 2023.08.06 ケモインフォマティクスケモメトリックスデータ解析プロセス制御・プロセス管理・ソフトセンサー研究室
ジメチルエーテル製造プロセスをベイズ最適化で頑健に設計すること(ロバストベイズ最適化)に成功しました![金子研論文] 金子研の論文が ACS Omega に掲載されましたので、ご紹介します。タイトルはRobust Design of a Dimethyl Ether Production Process Using Process Simulation a... 2023.08.06 ケモインフォマティクスケモメトリックスデータ解析プロセス制御・プロセス管理・ソフトセンサー化学工学研究室論文