新たなプログラムを作成する流れ~言語化が一番大事~ ケモインフォマティクスやマテリアルズインフォマティクスやプロセスインフォマティックスの研究をするなかで、手法の開発するときには、何らかのプログラミング言語でプログラムを作成することが必要になります。ちなみに金子研 (データ化学工学研究室) ... 2021.12.12 ケモインフォマティクスケモメトリックスデータ解析プログラミングプロセス制御・プロセス管理・ソフトセンサー研究室
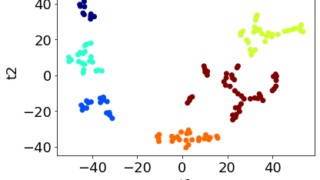
任意のクラスタリング手法においてクラスター数を自動的に決める方法 回帰分析やクラス分類などの教師あり学習における各手法のハイパーパラメータ (PLS における成分数や SVR における C, ε など) と比べて、データの可視化やクラスタリングなどの教師なし学習における各手法のハイパーパラメータ (t-S... 2021.12.12 ケモインフォマティクスケモメトリックスデータ解析プログラミングプロセス制御・プロセス管理・ソフトセンサー研究室
三つの本の使い分け 2021年8月1日現在、金子弘昌 著の3冊の本が出版されています。金子研オンラインサロンでは、本の内容に関する質問をいただいたり議論が深まったりして嬉しい限りです。修正点などのご指摘もいただき、実際に私の方で修正し、内容的にもアップデートさ... 2021.08.01 ケモインフォマティクスケモメトリックスデータ解析プログラミングプロセス制御・プロセス管理・ソフトセンサー化学工学研究室
「Pythonで学ぶ実験計画法入門 ベイズ最適化によるデータ解析」 化学・化学工学のデータ解析・機械学習を学びながら実験計画法やベイズ最適化を実践したい方へ 金子弘昌, 「Pythonで学ぶ実験計画法入門 ベイズ最適化によるデータ解析」, 講談社, 2021講談社: Amazon: 自分の本の紹介で恐縮です。ただ、ケモインフォマティクス、マテリアルズインフォマティクス、プロセスインフォマティクス... 2021.07.25 ケモインフォマティクスケモメトリックスデータ解析プログラミングプロセス制御・プロセス管理・ソフトセンサー化学工学研究室
「Pythonで気軽に化学・化学工学」 Python プログラミングを学びながら化学・化学工学のデータ解析・機械学習をしたい方へ 金子弘昌, 「Pythonで気軽に化学・化学工学」, 丸善, 2021丸善: Amazon: Amazon(Kindle): 自分の本の紹介で恐縮です。ただ、データ解析や機械学習による分子設計、材料設計、プロセス設計、プロセス管理・制御をし... 2021.07.18 ケモインフォマティクスケモメトリックスデータ解析プログラミングプロセス制御・プロセス管理・ソフトセンサー化学工学研究室講義
Anacondaを使わずにPythonでデータ解析・機械学習する方法 Anaconda が、ある条件のもとで有償化されています。参考: 原文: 個人的な趣味で Anaconda を利用したり、大学や研究所において教育・研究するために Anaconda を用いたりするときは問題ないと思いますが、例えば企業におい... 2021.07.11 ケモインフォマティクスケモメトリックスデータ解析プログラミングプロセス制御・プロセス管理・ソフトセンサー
「Pythonで気軽に化学・化学工学」 正誤表 「Pythonで気軽に化学・化学工学」 をご購入いただき感謝申し上げます。売れ行きも好調のようで嬉しい限りでございます。データを持っていたり、収集する予定だったりする多くの方が、プログラミングが未経験でもデータ解析・機械学習をできるようにな... 2021.07.04 ケモインフォマティクスケモメトリックスデータ解析プログラミングプロセス制御・プロセス管理・ソフトセンサー化学工学研究室
[無料公開] 「Pythonで学ぶ実験計画法入門 ベイズ最適化によるデータ解析」 の “まえがき”、目次の詳細、第1・2章 2021 年 6 月 3 日に、金子弘昌著の「Pythonで学ぶ実験計画法入門 ベイズ最適化によるデータ解析」が出版されました。講談社: Amazon: Amazon(Kindle): === 出版して約2年経過した 2023 年 4 月 ... 2021.06.06 ケモインフォマティクスケモメトリックスデータ解析プログラミングプロセス制御・プロセス管理・ソフトセンサー化学工学研究室
「Pythonで気軽に化学・化学工学」出版記念、購入者限定の無料講演会「教えて金子先生!『Pythonで気軽に化学・化学工学』をうまく活用するにはどうしたらいいの?」 を開催します![2021年6月2日(水)19時-] 2021年5月1日に、「Pythonで気軽に化学・化学工学」 が出版されました。初日に Amazon で売り切れになるなど、初速として好調のようです。ご購入いただいた皆さまにお礼申し上げます。ありがとうございます。プログラミングやPytho... 2021.05.02 ケモインフォマティクスケモメトリックスデータ解析プログラミングプロセス制御・プロセス管理・ソフトセンサー化学工学研究室
[無料公開] 「Pythonで気軽に化学・化学工学」 の “まえがき”、目次の詳細、第1・2・3章 2021 年 5 月 1 日に、金子弘昌著の「Pythonで気軽に化学・化学工学」が出版されました。丸善: Amazon: Amazon(Kindle): こちらの本は、前著の 「化学のための Pythonによるデータ解析・機械学習入門」 ... 2021.04.25 ケモインフォマティクスケモメトリックスデータ解析プログラミングプロセス制御・プロセス管理・ソフトセンサー化学工学研究室