データセットの空欄を埋める方法 データセットにおいて、空欄があるときがあります。すべてのサンプル、そしてすべての特徴量に値が準備されているわけではなく、穴あきのデータセットということです。データ解析や機械学習をするためには、まずこの空欄を埋める必要があります。もちろん場合... 2021.10.03 ケモインフォマティクスケモメトリックスデータ解析プロセス制御・プロセス管理・ソフトセンサー研究室
データセットを解析したり新たな手法を開発したりする時にチェックしていること データ化学工学研究室 (金子研) では、いろいろなデータセットを解析したり、ケモインフォマティクス・マテリアルズインフォマティクス・プロセスインフォマティクスの新たな手法を開発したりしています。そのようなとき、共通する内容として、主に以下の... 2021.10.03 ケモインフォマティクスケモメトリックスデータ解析プロセス制御・プロセス管理・ソフトセンサー
データ解析や構築したモデルの目的によって特徴量や手法は異なる データセットを準備して、説明変数 x と目的変数 y との間で回帰モデルやクラス分類モデル y = f(x) を構築して、そのモデルを活用する、といったことはあります。このときモデルの予測精度は非常に重要です。予測精度を向上させるために、x... 2021.09.26 ケモインフォマティクスケモメトリックスプロセス制御・プロセス管理・ソフトセンサー研究室
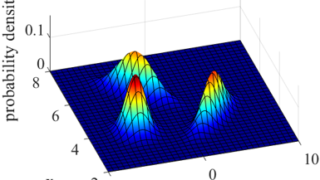
特徴量間の関係をすべて考慮してモデリングしたいならGMM 回帰分析やクラス分類では、説明変数 x と目的変数 y があり、x と y の間でモデル y = f(x) を構築します。モデルを用いて、x を入力して y を予測したり、y が目標値になるような x を設計したりします。ここでは、いろいろ... 2021.09.26 ケモインフォマティクスケモメトリックスデータ解析プロセス制御・プロセス管理・ソフトセンサー研究室
データセットに不要な特徴量があることよりも、重要な特徴量がないことの方が問題です 説明変数 x と目的変数 y の間のモデル y = f(x) について、モデルの予測精度を向上させようとするとき、x の特徴量の検討は非常に重要です。データ収集のときに適切な特徴量のデータを集めたり、データ収集後に特徴量を適切に変換したりす... 2021.09.19 ケモインフォマティクスケモメトリックスデータ解析プロセス制御・プロセス管理・ソフトセンサー研究室
測定条件・分析条件・評価条件の異なる物性や活性のデータの扱い 説明変数 x と目的変数 y の間で、機械学習によりデータセットからモデル y = f(x) を構築することがあります。y として物質の物性や活性が用いられますが、例えば温度や圧力といった、物性や活性の測定条件・分析条件・評価条件が異なるデ... 2021.09.19 ケモインフォマティクスケモメトリックスデータ解析プロセス制御・プロセス管理・ソフトセンサー研究室
データ解析や機械学習をするときは、常に目的を意識しましょう データセットがあるとき、例えば説明変数 x と目的変数 y の間で機械学習によりモデル y = f(x) を構築します。モデルに x の値を入力することで、y の値を予測でき、予測結果を活用します。このように機械学習によりデータセットを有効... 2021.09.12 ケモインフォマティクスケモメトリックスデータ解析プロセス制御・プロセス管理・ソフトセンサー研究室
困ったら基礎やアルゴリズムに立ち戻ることも大事です データ解析や機械学習を活用した研究・開発において、予測精度の高いモデルが作れなかったり、モデルの逆解析で有望そうなサンプルが得られなかったりして、困ったり壁を感じたりしたときの話です。一般的にはその状況を打破するような新たな手法や戦略を探し... 2021.09.05 ケモインフォマティクスケモメトリックスデータ解析プロセス制御・プロセス管理・ソフトセンサー研究室
可視化手法・低次元化手法の分類 説明変数 x の数が大きいときなど、データセットを用いてx を潜在変数 z に変換する手法を用いることがあります。z の数が二つのとき、データの可視化 (見える化) になります。手法の例としては、以下のものが挙げられます。 Principa... 2021.09.05 ケモインフォマティクスケモメトリックスデータ解析プロセス制御・プロセス管理・ソフトセンサー研究室
目的変数が複数あるときの解析の方針の決め方 説明変数 x と目的変数 y の間でモデル y = f(x) を構築して、新しいサンプルの x をモデルに入力して y を予測したり、y が望ましい値になる x を設計したり (モデルの逆解析) します。このとき、y が複数あることがありま... 2021.08.29 ケモインフォマティクスケモメトリックスデータ解析プロセス制御・プロセス管理・ソフトセンサー研究室