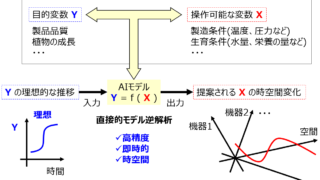
直接的逆解析法では特徴量の制約、定性的な特徴量、転移学習も扱えます 金子研で開発している直接的逆解析についてです。(直接的逆解析ではない) いわゆる一般的な逆解析では、モデルを構築した後に、説明変数 x の大量のサンプルを生成し、構築したモデルに入力し、目的変数 y の値を予測します。そして予測値が良さそう... 2021.07.25 ケモインフォマティクスケモメトリックスデータ解析プロセス制御・プロセス管理・ソフトセンサー研究室
「Pythonで気軽に化学・化学工学」 Python プログラミングを学びながら化学・化学工学のデータ解析・機械学習をしたい方へ 金子弘昌, 「Pythonで気軽に化学・化学工学」, 丸善, 2021丸善: Amazon: Amazon(Kindle): 自分の本の紹介で恐縮です。ただ、データ解析や機械学習による分子設計、材料設計、プロセス設計、プロセス管理・制御をし... 2021.07.18 ケモインフォマティクスケモメトリックスデータ解析プログラミングプロセス制御・プロセス管理・ソフトセンサー化学工学研究室講義
モデルの逆解析をふまえた特徴量設計 既存のデータセットを用いて、説明変数 x と目的変数 y の間で、回帰分析手法やクラス分類手法により、モデル y = f(x) を構築したり、構築したモデルを用いて、望ましい y の結果になるように x の値を設計したりします。予測精度の高... 2021.07.11 ケモインフォマティクスケモメトリックスデータ解析プロセス制御・プロセス管理・ソフトセンサー研究室
Anacondaを使わずにPythonでデータ解析・機械学習する方法 Anaconda が、ある条件のもとで有償化されています。参考: 原文: 個人的な趣味で Anaconda を利用したり、大学や研究所において教育・研究するために Anaconda を用いたりするときは問題ないと思いますが、例えば企業におい... 2021.07.11 ケモインフォマティクスケモメトリックスデータ解析プログラミングプロセス制御・プロセス管理・ソフトセンサー
「Pythonで気軽に化学・化学工学」 正誤表 「Pythonで気軽に化学・化学工学」 をご購入いただき感謝申し上げます。売れ行きも好調のようで嬉しい限りでございます。データを持っていたり、収集する予定だったりする多くの方が、プログラミングが未経験でもデータ解析・機械学習をできるようにな... 2021.07.04 ケモインフォマティクスケモメトリックスデータ解析プログラミングプロセス制御・プロセス管理・ソフトセンサー化学工学研究室
特徴量選択の結果をこのように整理してはいかがでしょうか?[Pythonコードあり] 説明変数 x と目的変数 y の間で回帰モデルやクラス分類モデルを構築するとき、モデルの予測精度やモデルの解釈性を向上させるため、特徴量選択 (変数選択) をすることがあります。例えば 1000 個の x があるとき、特徴量選択をして 50... 2021.07.04 ケモインフォマティクスケモメトリックスデータ解析プロセス制御・プロセス管理・ソフトセンサー研究室
IoTインフォマティクス、一緒にやりませんか? [さきがけのヒヤリングで落選した内容。申請書のpdfファイルあり] 2020 年度に 「時空間制御による運転最適化のためのモデルの高速逆解析」 という研究課題名で、研究領域 「IoTが拓く未来」 のさきがけに応募しました。首尾よくヒヤリングまで進んだのですが、ヒヤリングで落選してしまいました。残念ですが、研... 2021.06.27 ケモインフォマティクスケモメトリックスデータ解析プロセス制御・プロセス管理・ソフトセンサー化学工学研究室
特徴量選択手法について、モデルの予測精度・選択された特徴量の割合・選択された乱数の特徴量の割合で議論しました![金子研論文] 金子研の論文が Heliyon に掲載されましたので、ご紹介します。タイトルはExamining variable selection methods for the predictive performance of regression... 2021.06.20 ケモインフォマティクスケモメトリックスデータ解析プロセス制御・プロセス管理・ソフトセンサー研究室論文
転移学習における標準化(オートスケーリング) 転移学習は、対象としているデータセット (ターゲットドメイン) だけでなく、そのデータセットに少し関連はありますが、一緒には扱えなさそうな別のデータセット (ソースドメイン、こちらはサンプル数がある程度大きいことが前提です) を活用して、回... 2021.06.13 ケモインフォマティクスケモメトリックスデータ解析プロセス制御・プロセス管理・ソフトセンサー研究室
「Pythonで学ぶ実験計画法入門 ベイズ最適化によるデータ解析」 正誤表 「Pythonで学ぶ実験計画法入門 ベイズ最適化によるデータ解析」 をご購入いただき感謝申し上げます。売れ行きも好調のようで嬉しい限りでございます。多くの方々に実験計画法、適応的実験計画法、ベイズ最適化をご活用いただきたいという思いで執筆し... 2021.06.13 ケモインフォマティクスケモメトリックスデータ解析プロセス制御・プロセス管理・ソフトセンサー化学工学研究室