NMRにおけるスカラーカップリング定数を予測するための記述子を開発しました![金子研論文] 金子研の論文が Analytical Science Advances に掲載されましたので、ご紹介します。タイトルはPrediction of spin–spin coupling constants with machine learn... 2021.03.21 ケモインフォマティクスケモメトリックスデータ解析研究室
実験条件の最初の候補を選ぶとき、金子研ではどうして直交表を作らないのか? 実験計画法のお話です。こちらの記事では、わかりやすさのために () 付きで「直交表」としていますが、厳密に言えば、いわゆる古くから使われている直交表ではありません。直交表のようではありますが、それとは別の方法で最初の実験条件の候補を選んでい... 2021.03.21 ケモインフォマティクスケモメトリックスデータ解析プロセス制御・プロセス管理・ソフトセンサー研究室
ガウス過程回帰の使い方と注意点 説明変数 X と目的変数 Y との間でモデル Y = f(X) を構築するとき、特に Y が連続値の場合は回帰分析が行われます。回帰分析手法にはいろいろありますが、ここではガウス過程回帰 (Gaussian Process Regressi... 2021.03.14 ケモインフォマティクスケモメトリックスデータ解析プロセス制御・プロセス管理・ソフトセンサー研究室
カーネル関数の選び方 機械学習の手法の中には、カーネル関数を用いた手法があります。サポートベクターマシン、サポートベクター回帰、ガウス過程回帰あたりが有名と思います。他にもリッジ回帰や主成分分析、独立成分分析など、いろいろな手法とカーネル関数を組み合わせることが... 2021.02.21 ケモインフォマティクスケモメトリックスデータ解析プロセス制御・プロセス管理・ソフトセンサー研究室
欠損値のないサンプルがデータセットにないときの iGMR の使い方 データセットの中に欠損値があるときは、iGMR が有効であることはこちらに書きました。たとえば、論文や特許からデータを取得したときなど、他のデータ (研究室内や社内のデータなど) と合わせようとしたときに、論文や特許ではいくつかの実験条件が... 2021.02.21 ケモインフォマティクスケモメトリックスデータ解析プロセス制御・プロセス管理・ソフトセンサー研究室
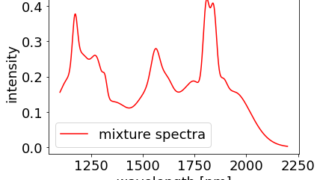
DCEKit に新機能追加 [v2.6.1]!トレーニングデータなしでスペクトルから濃度を推定する方法 DCEKit への新機能追加です。こちらの Iterative Optimization Technology (IOT) を実装しました。IOT では、純成分のスペクトルと混合物のスペクトルのみから、混合物における各純成分の濃度 (モル分... 2021.02.14 ケモインフォマティクスケモメトリックスデータ解析プロセス制御・プロセス管理・ソフトセンサー研究室
DCEKit に新機能追加 [v2.5.2]!Variational Bayesian Gaussian Mixture Regression(VBGMR)とクロスバリデーションによるGMR最適化 DCEKit に今回追加したのは Variational Bayesian Gaussian Mixture Regression (VBGMR) と、GMR や VBGMR におけるクロスバリデーションによるハイパーパラメータ最適化です。... 2021.02.11 ケモインフォマティクスケモメトリックスデータ解析プロセス制御・プロセス管理・ソフトセンサー研究室
勘をなめたらアカン ダジャレです。が、本心です。材料研究・材料開発の現場では、実験条件や製造条件を振って、実際に実験・製造してみて、その結果としての材料の物性・活性といった値を測定します。実験条件や製造条件を振るときに、すべて理論的に、化学的な背景や物理的な背... 2021.02.07 ケモインフォマティクスケモメトリックスデータ解析化学工学
ガウス過程による潜在変数モデルでプロセスデータの可視化やプロセス状態推定をしました![金子研論文] 金子研の論文が Analytical Science Advances に掲載されましたので、ご紹介します。タイトルはEstimation and visualization of process states using latent v... 2021.01.31 ケモメトリックスデータ解析プロセス制御・プロセス管理・ソフトセンサー化学工学研究室論文
「化学のためのPythonによるデータ解析・機械学習入門(改訂2版)」 化学・化学工学のデータ解析・機械学習をしたい方へ 金子弘昌, 「化学のためのPythonによるデータ解析・機械学習入門(改訂2版)」, オーム社, 2023オーム社: Amazon: 自分の本の紹介で恐縮です。ただ、データ解析や機械学習による分子設計、材料設計、プロセス設計、プロセス管理・... 2021.01.24 ケモインフォマティクスケモメトリックスデータ解析プログラミングプロセス制御・プロセス管理・ソフトセンサー化学工学研究室