データ解析前における、説明変数(特徴量・記述子)の決め方・選び方の方針 目的変数 Y と説明変数 (特徴量・記述子) X との間に、クラス分類や回帰分析によってモデル Y = f(X) を構築します。モデルを構築するためにはデータセットが必要ですので、Y, X を決めてからサンプルを集めなければなりません。モデ... 2020.06.28 ケモインフォマティクスケモメトリックスデータ解析プロセス制御・プロセス管理・ソフトセンサー研究室
モデルの予測精度は、目的変数Yの誤差だけでなくモデルの適用範囲を含めて議論しましょう 新型コロナウイルスの影響もあり、セミナーや講演会はオンラインで行うようになってきました。対面でやるときも、オンラインでやるときも、だいたいどこでも聞かれる質問に、サンプル数をどれくらい増やせば十分ですか?いくつのサンプルを集めれば十分に予測... 2020.06.21 ケモインフォマティクスケモメトリックスデータ解析プロセス制御・プロセス管理・ソフトセンサー
変数選択・特徴量選択のときの意識は、モデルの予測精度を上げることより、不要な変数・特徴量を削除することです 回帰モデルやクラス分類モデルの予測精度を上げるためモデルを解釈するため色々な目的で変数選択 (特徴量選択) をしていると思います。相関係数に基づく削除、Stepwise法、LASSO、GAPLS, GASVR、Boruta とかですね。変数... 2020.06.14 ケモインフォマティクスケモメトリックスデータ解析プロセス制御・プロセス管理・ソフトセンサー研究室
目的変数の値が0から1の間のとき、予測値も0から1の間にしたい!→ロジット変換はどうでしょう? 今回は、目的変数 Y の値が 0 から 1 の間にあり、回帰分析をするときの話です。例えば Y がモル分率などのときですね。このような Y と説明変数 X の間で回帰モデル Y=f(X) を構築して、X の値から Y の値を予測したとき、予... 2020.06.07 ケモインフォマティクスケモメトリックスデータ解析プロセス制御・プロセス管理・ソフトセンサー研究室
目的変数 Y における測定誤差などのばらつきを考慮したモデリング 目的変数 Y と説明変数 X との間で回帰モデル Y = f(X) を構築するとき、Y が物性・活性などの何らかの測定値である場合をはじめとして、一般的には X の値が全く同じであっても、Y は測定誤差などによってばらつきます。回帰分析では... 2020.05.31 ケモインフォマティクスケモメトリックスデータ解析プロセス制御・プロセス管理・ソフトセンサー研究室
どのようなときに目的変数Yではなくlog(Y)にしたほうがよいのか?~対数変換するメリットとデメリット~ 回帰分析では、目的変数 Y と説明変数 X との間でモデル Y = f(X) を構築します。このとき、Y ではなく、それを対数変換した log(Y) を用いることがあります。モデル log(Y) = f(X) を構築し、モデルに X を入力... 2020.05.31 ケモインフォマティクスケモメトリックスデータ解析プロセス制御・プロセス管理・ソフトセンサー研究室
ちょっとソフトセンサーを試してみたいという方へ、プログラミング不要で実行できるアプリ「DCE soft sensor」を作りました。ご自由にお使いください ソフトセンサーを試してみたい、プラントのデータを使ってソフトセンサーで推定してみたら、どれくらいの誤差で推定できるのか確認してみたい、という方はいらっしゃると思います。試してみて良い結果が出ると、さらにソフトセンサーを勉強するモチベーション... 2020.05.17 ケモメトリックスプロセス制御・プロセス管理・ソフトセンサー
「DCE tool」に機能を追加しました!その2 逆解析のための予測用サンプルの生成・化学構造モード 「DCE tool」に機能を追加しましたので報告します!追加した機能は、 逆解析のための予測用サンプルの生成 化学構造モードです。順に説明します。なお新しい DCE tool はこちら↓からダウンロードをお願いします。DCE tool ダウ... 2020.05.10 ケモインフォマティクスケモメトリックスデータ解析プロセス制御・プロセス管理・ソフトセンサー
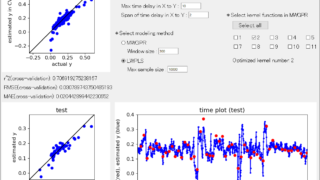
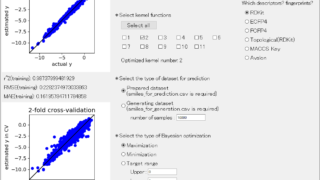
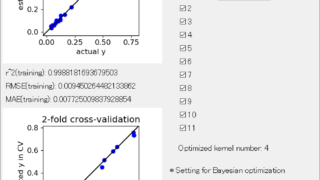
「DCE tool」に機能を追加しました!クロスバリデーション・カーネル関数・ベイズ最適化 「DCE tool」に機能を追加しましたので報告します!追加した機能は、 クロスバリデーションの fold 数の選択 カーネル関数のクロスバリデーションによる最適化 ベイズ最適化です。順に説明します。なお新しい DCE tool はこちら↓... 2020.05.03 ケモインフォマティクスケモメトリックスデータ解析プロセス制御・プロセス管理・ソフトセンサー
機械学習を手軽に試したい方へ、プログラミング不要で実行できるアプリ「DCE tool」を作りました。ご自由にお使いください 機械学習にチャレンジしてみたい、自分のもっているデータを使って機械学習してみたらどうなるか確認してみたい、という方はいらっしゃると思います。実際に機械学習をやってみて、よい結果が出ると、さらに機械学習をするモチベーションになるかもしれません... 2020.04.26 ケモインフォマティクスケモメトリックスデータ解析プロセス制御・プロセス管理・ソフトセンサー