「DCE tool」に機能を追加しましたので報告します!
追加した機能は、
- クロスバリデーションの fold 数の選択
- カーネル関数のクロスバリデーションによる最適化
- ベイズ最適化
です。順に説明します。なお新しい DCE tool はこちら↓からダウンロードをお願いします。
まず DCE tool の基本的な使い方に関してはこちらをご覧ください。
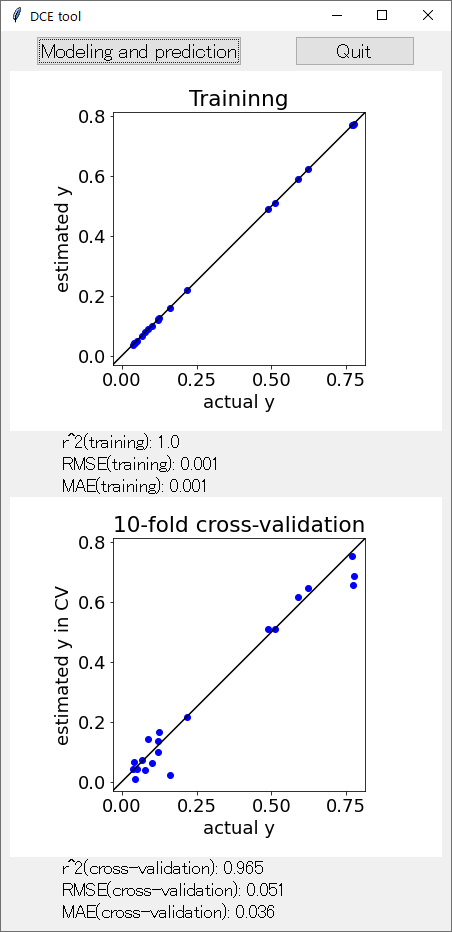
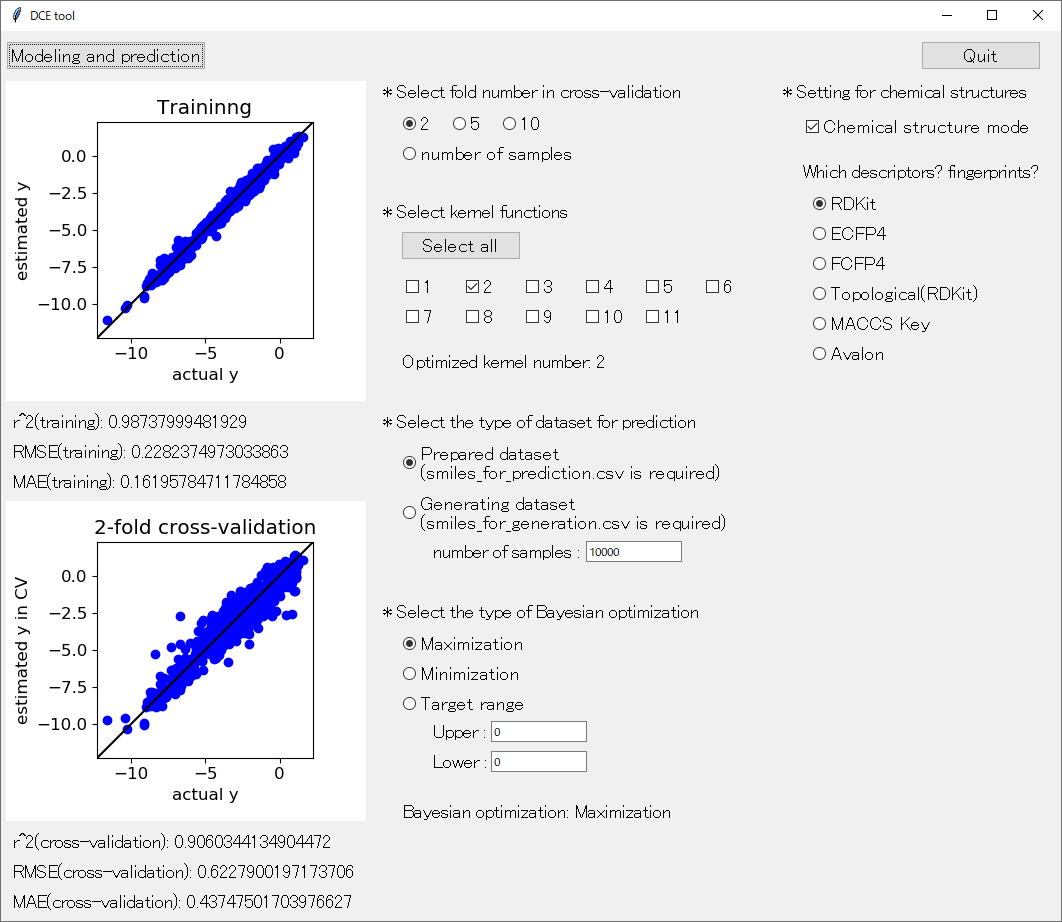
アップデートした DCE tool の起動画面はこんな感じです。
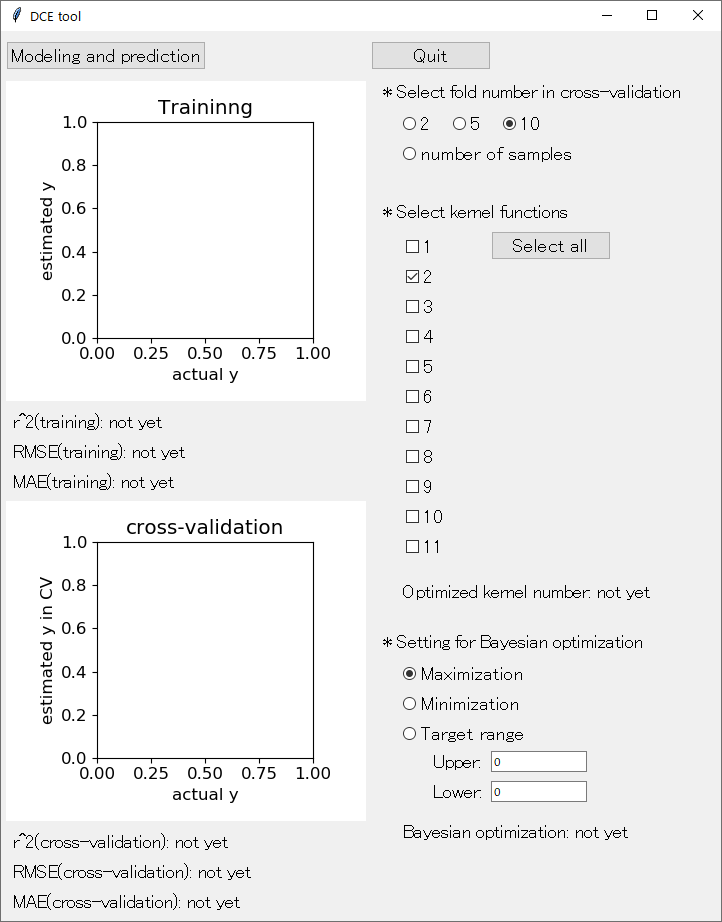
最初のクロスバリデーションについて 「* Select fold number in cross-validation」 です。初期設定では、10-fold クロスバリデーションになっています。それを 2-fold クロスバリデーション、5-fold クロスバリデーション、leave-one-out クロスバリデーションに変更可能になりました。「number of samples」 が leave-one-out クロスバリデーションに対応しています。クロスバリデーションについてはこちらをご覧ください。

サンプルが多いときには 2 や 5 がよく、逆にサンプルが少ないときには number of samples (leave-one-out クロスバリデーション) がよいと思います。目安としては、
- 1000 サンプル以上 : 2-fold クロスバリデーション
- 1000 から 100 くらいまで : 5-fold クロスバリデーション
- 100 から 30 くらいまで : 10-fold クロスバリデーション
- 30 以下 : leave-one-out クロスバリデーション (number of samples)
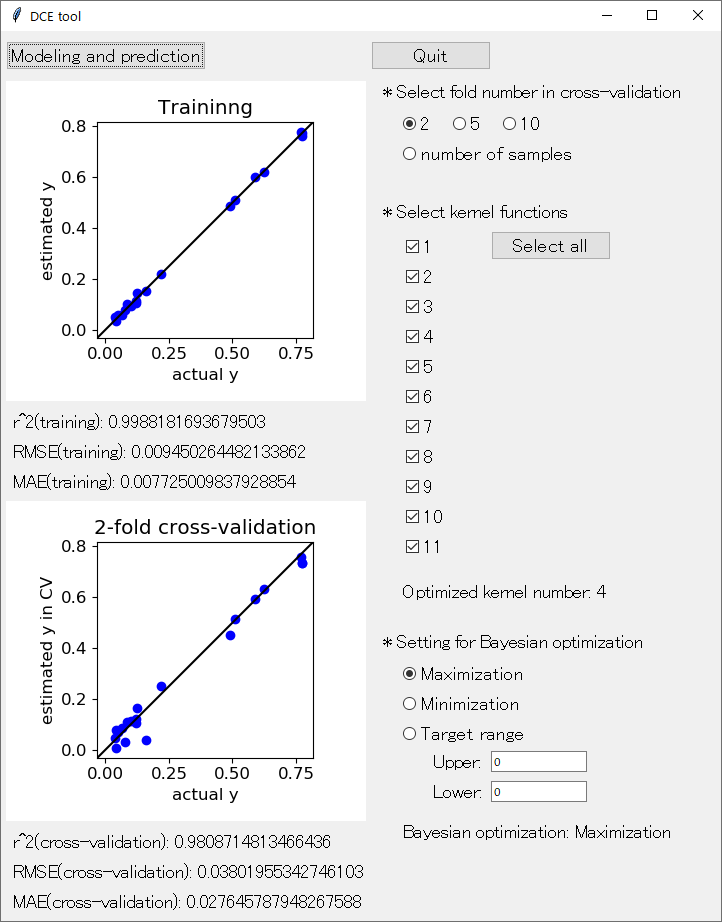
といった感じでしょうか。実際に行われた *-fold クロスバリデーションが、目的変数 y の実測値 vs. クロスバリデーション後の推定値のプロットのタイトルに表示されます。たとえば 2-hold クロスバリデーションを選択して 「Modeling and prediction」 をクリックして回帰分析したときは、下図のような感じです。
続いてカーネル関数の選択およびその中でのクロスバリデーションによる最適化 「* Select kernel functions」 です。11 個のカーネル関数から、用いるもののみを選択できます。11 個のカーネル関数はこちらに記載したもので、順番も同じです。

「Select all」 をクリックすると、すべてのカーネル関数が選択されます。選択されたカーネル関数が複数の場合は、その中で 「* Select fold number in cross-validation」 で選択したクロスバリデーション後の r2 が最大となるカーネル関数が選ばれます。たとえば、すべてのカーネル関数を選択して 2-fold クロスバリデーションをした上の図では、「Optimized kernel number: 4」 とありますので、2-fold クロスバリデーション後に r2 が最大となったカーネル関数は 4 番目のカーネル関数であることがわかります。
最適化されたカーネル関数を用いて、ガウス過程回帰によりその後の解析、つまりモデル構築や予測が行われます。
最後に、ベイズ最適化 「* Setting for Bayesian optimization」 です。Probability of Improvement (PI) もしくは y のある目標範囲に入る確率を計算できます。ベイズ最適化についてはこちらをご覧ください。
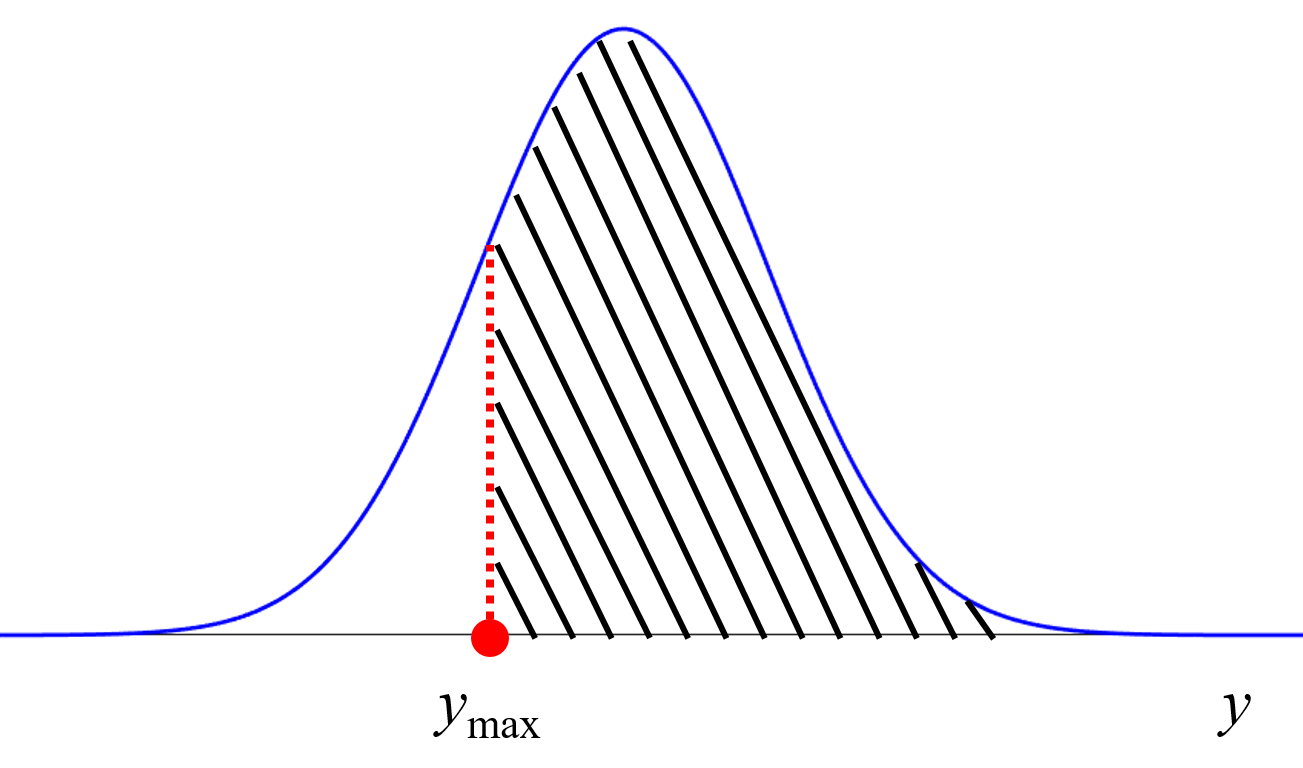
y の値をより大きくしたいのか (Maximization)、より小さくしたいのか (Minimization)、ある目標範囲内にしたいのか (Target range) を設定します。「Target range」 を選択したら、その上限値 (Upper) と下限値 (Lower) を設定してください。ちなみに Upper ≦ Lower の場合は、自動的に Maximization になります。「Modeling and prediction」 をクリックして解析が進むと、”x_for_prediction.csv” に対する予測結果として、ベイズ最適化の獲得関数の値が追記されます。つまり x_for_prediction.csv に対する y の予測結果である predicted_y_in_x_for_prediction.csv の内容は以下になります。
- 予測値(predicted y)
- 予測値の標準偏差(std of predicted y)
- ベイズ最適化の獲得関数 (probabilities)
たとえば次の実験条件の候補として、probabilities が最大となる候補を選択するとよいでしょう。
ぜひ新しい機能が追加された DCE tool をご活用ください。
また「DCE tool」には機能が追加されました。こちらもご覧ください。
以上です。
質問やコメントなどありましたら、twitter, facebook, メールなどでご連絡いただけるとうれしいです。