
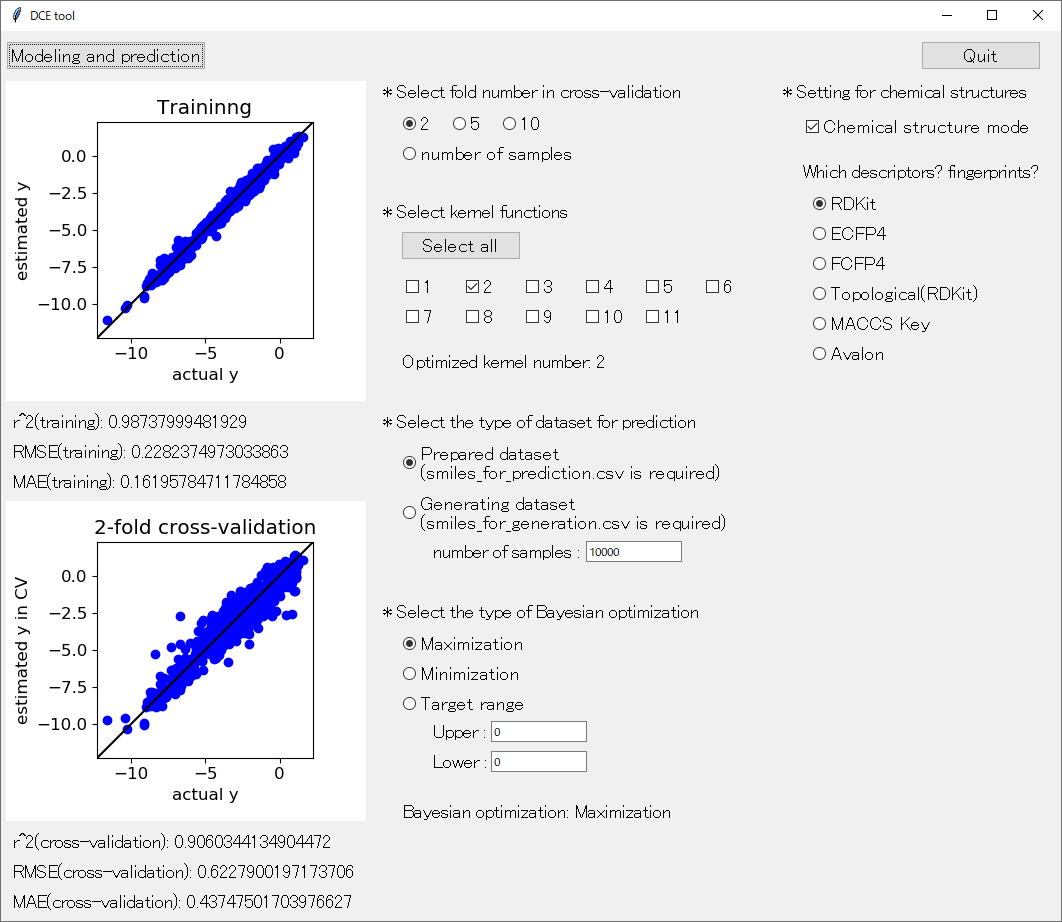
分子設計・材料設計・プロセス設計・プロセス管理において、分子記述子・実験条件・合成条件・製造条件・評価条件・プロセス条件・プロセス変数などの特徴量 x と分子・材料の物性・活性・特性や製品の品質などの目的変数 y との間で数理モデル y = f(x) を構築し、構築したモデルに x の値を入力して y の値を予測したり、y が目標値となる x の値を設計したりします。
化学構造、スペクトルデータ、時系列データなど、そのままでは x として使用できないデータの場合でも、様々な手法があるため、データそのものを直接見なくても、例えば Python コードを作成しておくことで、自動的にモデル構築や予測を実行できます。例えば、化学構造と物性のそろったデータセットを用いて、RDKit により化学構造から分子記述子を計算し、それを x として物性 y との間で回帰モデルを構築することが自動でできます。
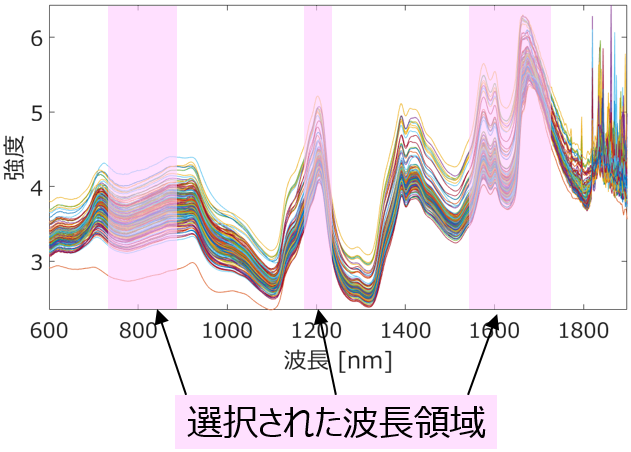
スペクトルデータでも、Savitzky-Golay 法で前処理してから GAWLS による波長選択をしてモデルを構築する一連の流れを自動で行うことができます。

時系列データでも、GAVDS で時間遅れを考慮してモデルを構築したり、
バッチデータを特徴量化してモデルを構築することが可能です。


モデルの予測結果を確認して、予測誤差の大きいサンプルの化学構造、スペクトルデータ、時系列データを確認することもあります。もちろんこれも重要ですが、外れたサンプルだけでなく、外れていないサンプルを含めて、データセット全体の化学構造、スペクトルデータ、時系列データをながめることで、新しく気づくこともあります。
もともと化学構造は図形データであり、スペクトルデータや時系列データは、波長間の相関や自己相関といった特徴的な関係性を持った数値データです。このようなデータを視覚的に確認することで、サンプル間の関係性や x としての表現の仕方を考えることが、次の解析につながることもあります。サンプルが多いと、すべてを見ることは大変かもしれませんが、新しい回帰分析手法やクラス分類手法を考案するよりも、データを視覚的に確認しながら考えることの方が、次の解析結果に対して大きなインパクトが得られることがあります。
化学構造、スペクトルデータ、時系列データなど、単純な数値データではないデータについては、それを実際に見て確認することに時間を使うと、結果的に予測精度の高いモデル構築につながったり、新しい分子・材料・プロセスの設計につながったりします。いわゆる (狭い意味での) データ解析・機械学習だけでなく、データの確認も非常に重要です。
以上です。
質問やコメントなどありましたら、X, facebook, メールなどでご連絡いただけるとうれしいです。

