
分子設計・材料設計・プロセス設計・プロセス管理において、分子記述子・合成条件・製造条件・評価条件・プロセス条件・プロセス変数 x と材料の物性・活性・特性や製品品質 y との間で数理モデル y = f(x) を用いて、x の値から y の値を推定したり、y が目標値になるような x を設計したりします。また、構築されたモデルを解釈することで、次の設計やプロセルの制御や運転管理に活用します。
モデルを解釈するときに用いるものとして、大きく分けて
- 全体的(グローバル)な変数重要度(特徴量重要度)
- 局所的(ローカル)な変数(特徴量)の寄与度
があります。
全体的な変数重要度の指標としては、ランダムフォレストなどをはじめとするアンサンブル学習によって計算される指標や
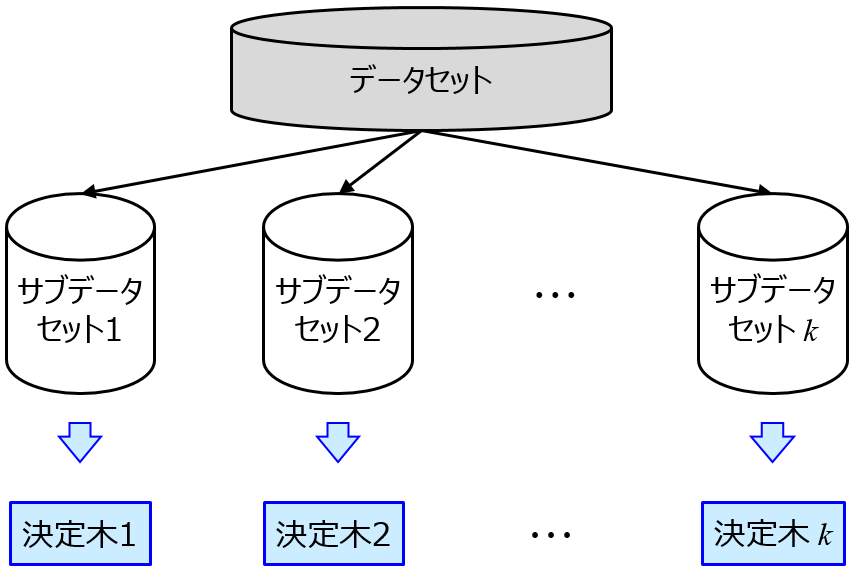

Permutation feature importance や Cross-Validated Permutation Feature Importance (CVPFI) が挙げられます。

一方で、局所的な変数の寄与度としては、LIME (Local Interpretable Model-agnostic Explanations) [Github], SHAP (SHapley Additive exPlanations) [Github], DeepLIFT (Deep Learning Important FeaTures) [Github], Influence Functions [Github] などが有名です。

全体的な変数重要度は、データセットにおける y の値を変化させることに寄与する x を解釈しようとします。例えば、材料合成やプロセスにおいて、y を変化したさせたくないときは、全体的な変数重要度の指標の値が大きい変数を、値が変化しないように重点的に管理することで、y の変化を抑えることができます。逆に、y の値を変化させたいときは、全体的な変数重要度の指標の値が大きい変数の値を変化させることで、効率的に y の値を大きく変えられる可能性があります。
一方で、局所的な変数の寄与度は、あるサンプル周りで y に対して x がどのように寄与しているか解釈しようとします。局所的な変数の寄与度により、ある一つのサンプル (仮想的なサンプルでも OK) から、y の値をさらに大きくさせたい場合や、y の値をさらに小さくさせたい場合に、そのサンプルにおける x の値からどのように変化させればよいかがわかります。
このように、全体的な変数重要度の指標と、局所的な変数の寄与度の指標をうまく使い分けて、モデルを解釈したり、次の設計や次の設計やプロセルの制御や運転管理に活かしたりするとよいでしょう。
以上です。
質問やコメントなどありましたら、twitter, facebook, メールなどでご連絡いただけるとうれしいです。

