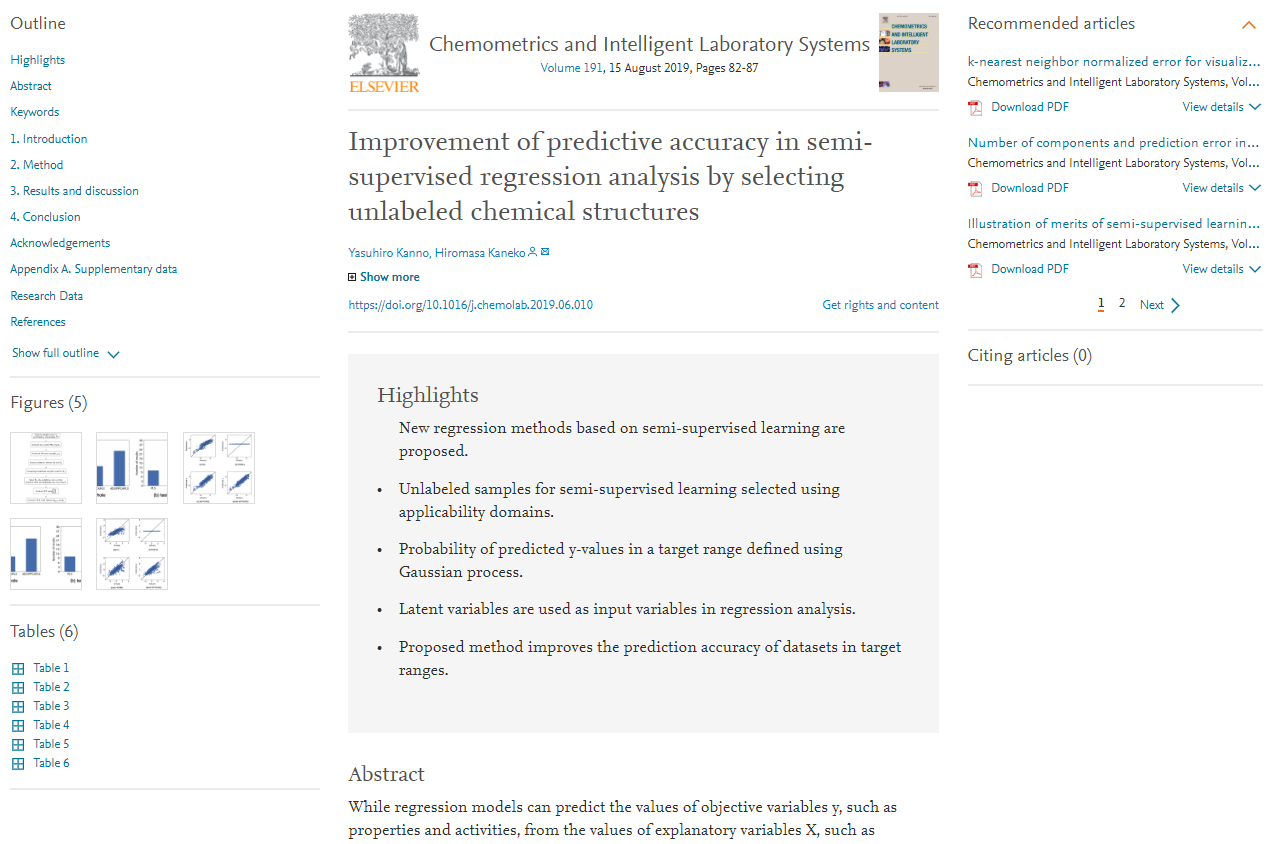
下図のような欠損値 (欠損データ) のあるデータセットがあるとします。穴あきのデータセットですね。
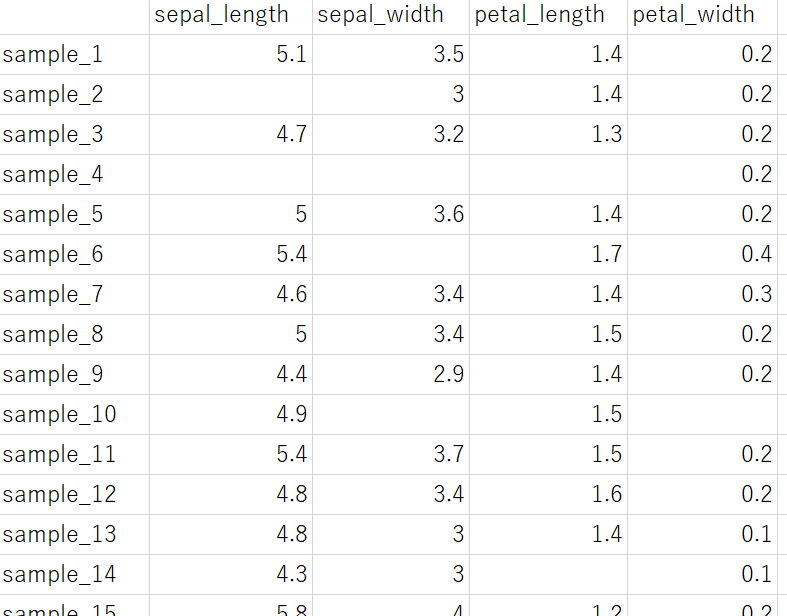
こんなときに、穴の空いたところである欠損値を補完する方法を提案します。上の図のようなデータセットを下図のようにできます。
たとえば、論文や特許からデータを取得したときなど、他のデータ (研究室内や社内のデータなど) と合わせようとしたときに、論文や特許ではいくつかの実験条件が不明、といったこともあります。このような場合において、値が不明なサンプルにおいて、もし他のサンプルと同じ実験をしたと仮定したら、どんな実験条件だったか?、を今回紹介する iterative Gaussian Mixture Regression (iGMR) により計算できます。
欠損値を補完する最も単純な方法は、欠損値を同じ変数 (特徴量) の平均値で補完する方法です。ただ、この方法では1 つの変数の情報しか用いてなく、同じ変数の欠損値はすべて同じ値になってしまい、あまり適切ではありません。他の変数の情報も使って、欠損値を推定して埋めたほうが、適切な値になりそうですよね。
というわけで、ランダムフォレストを用いた方法や、生成モデルを用いた方法1, 2 などがあります。ランダムフォレストの方法にはパッケージもあります。Python はこちら。
今回は、Gaussian Mixture Regression (GMR) を繰り返し用いて欠損値を補完する方法を提案し、Python コードを公開します。繰り返し GMR を用いるので、iterative GMR (iGMR) とでも呼びましょうか。GMR についてはこちらをご覧ください。
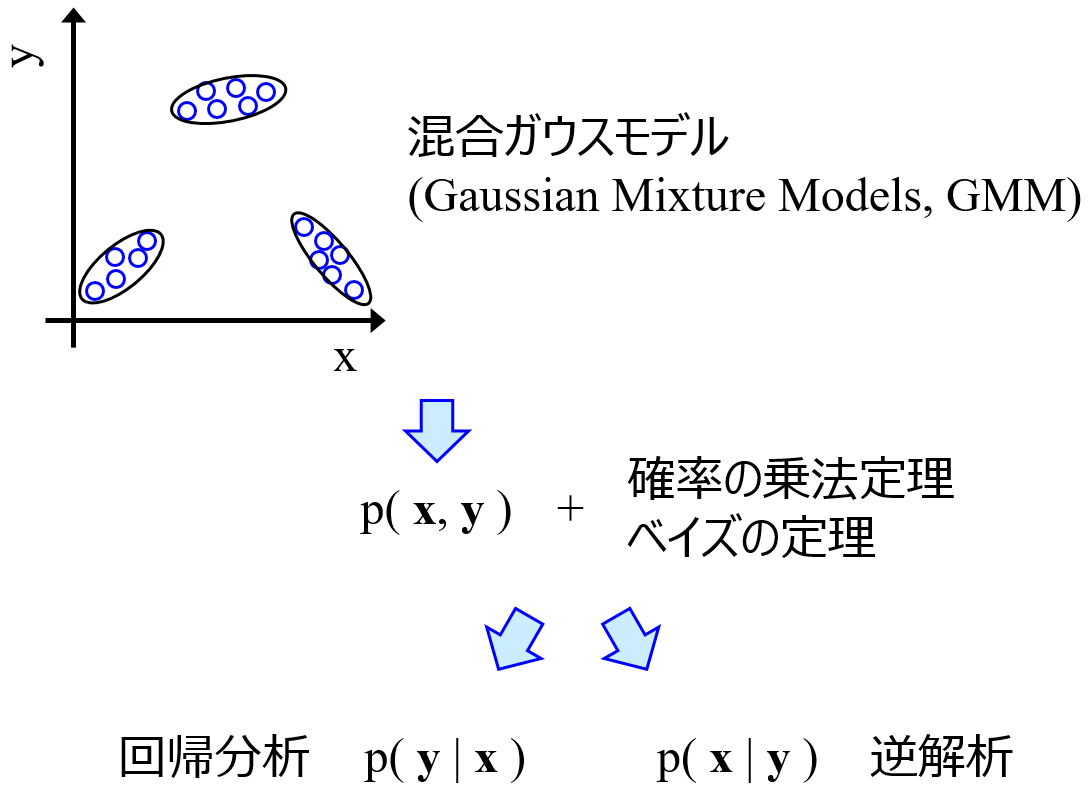
Gaussian Mixture Models (GMM) により、すべての変数の間の同時確率分布が得られますので、欠損値を含むサンプルにおいて、欠損値でない変数の値から GMR で欠損値を推定できます。iGMR の流れは以下のとおりです。
- 元のデータセットを D とする
- D における欠損値の場所を M とする
- D の中で、欠損値のないサンプルのみ選択し、X とする
- X を用いて GMM を構築する
- 構築した GMM により、D の欠損値をふくむ各サンプルにおいて、M 以外の変数の値を用いて GMR で M の値を推定する
- M の推定値で D を更新し、X とする
- 繰り返し回数の上限になるまで、4. から 6. を繰り返す
Python コードはこちらにあります。
[New] こちらの DCEKit で、便利に iGMR をご利用いただけます。

デモンストレーションのプログラムは demo_gmm_with_interpolation.py です。サンプルデータセットとして、あやめのデータセット に欠損値を入れた iris_with_nan.csv があります。実行すると、欠損値が補完されて、interpolated_dataset.csv というファイルに保存されます。
iris_with_nan.csv と同じデータ形式にすれば、他のデータセットでも欠損値を補完できます。ちなみに、データセットは目的変数があってもなくても構いません。目的変数があって、そこに欠損値もあれば、いわゆる回帰分析と同じになります。
必要がありましたらぜひご利用ください。
以上です。
質問やコメントなどありましたら、twitter, facebook, メールなどでご連絡いただけるとうれしいです。