
分子設計・材料設計・プロセス設計・プロセス管理において、分子記述子・実験条件・合成条件・製造条件・評価条件・プロセス条件・プロセス変数などの特徴量 x と分子・材料の物性・活性・特性や製品の品質などの目的変数 y との間で数理モデル y = f(x) を構築し、構築したモデルに x の値を入力して y の値を予測したり、y が目標値となる x の値を設計したりします。
モデルを構築するとき過学習 (オーバーフィッティング) が問題になります。
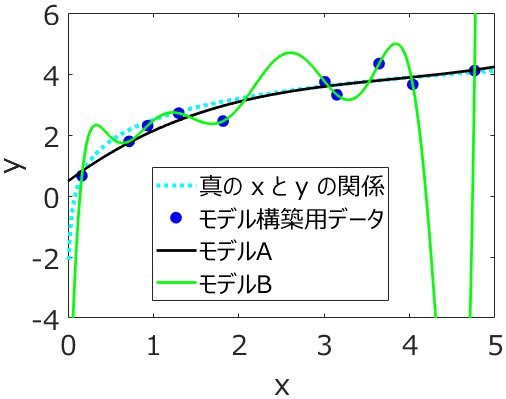
オーバーフィッティングとは、トレーニングデータの本質的な変動だけでなく、データに含まれるノイズにも合うようにモデルが構築されてしまう現象です。もちろん、オーバーフィッティングが問題であることは間違いないのですが、オーバーフィッティングを必ず防がないといけないかというと、そうではありません。オーバーフィッティングしていても予測性能の高いモデルはありますし、オーバーフィッティングしていなくても予測性能の低いモデルはあります。ざっくりと図で表すと下のようなイメージです。
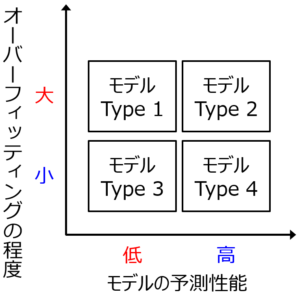
Type 1, 2, 3, 4 といった色々なモデルがあります。データ解析・機械学習の目的に応じて、適切なモデルを選択する必要があります。
多くの場合において、予測精度の高いモデルが求められます。もちろん、細かくいえば y の値が大きいサンプルを精度よく予測できるモデルがよい、y の値が小さいサンプルを精度よく予測できるモデルがよい、ということはあります。ただ、いずれにせよ、新しいサンプルに対してより正しく y を予測できるモデルがよいでしょう。
あくまでも、オーバーフィッティングをしていないモデルを構築することが目的ではありません。オーバーフィッティングしていても、新しいサンプルに対してより正しく y を予測できるモデルがあれば、その方がよいわけです。
そのため、オーバーフィッティングをしているかどうかにかかわらず、トレーニングデータとテストデータに分割してトレーニングデータで構築したモデルにテストデータを入力して予測したり、ダブルクロスバリデーションをしたりしてモデルの予測性能を評価します。そして、評価結果が良好なモデルを使用します。
もちろんオーバーフィッティングは問題ですが、これを解決すればすべてが上手くいくわけではありません。オーバーティングとうまく付き合いながら、モデルを運用する方が結果的に上手くいくこともあります。重要なことは、今あるデータセットや研究・開発したい分子・材料・プロセス、そしてデータセットを用いたデータ解析・機械学習による研究・開発・製造の目的に応じて、適切にモデルを検討することです。オーバーフィッティングにとらわれすぎず、データ解析・機械学習をしていきましょう。
以上です。
質問やコメントなどありましたら、twitter, facebook, メールなどでご連絡いただけるとうれしいです。

