分子設計や材料設計において、これまでの実験データを活用して、よりよい高機能性材料を達成するための化学構造や実験条件 (実験レシピ) を設計することを考えます。このウェブサイトにいろいろと書いてあるように、たとえば化合物のもつ物性や活性 Y と、その化合物の化学構造 X との間でモデル Y = f(X) を作ったり、材料の物性・活性・特性 Y と実験条件 X との間でモデル Y = f(X) を構築したりします。

そのモデルを活用して、物性・活性・特性 Y が良好な値をもつような化学構造 X を提案したり、実験条件 X を提案したりします。
既存のデータセットにおける物性・活性・特性の値を超えるような化学構造や実験条件を提案するためのモデルを構築するとき、もちろん物性・活性・特性が良好な値であった実験結果のデータも大事ですが、物性・活性・特性がよくない値であった実験結果のデータ (ネガティブデータ) も同じくらい重要です。
その理由は二つあります。
一つは、よくない結果となる化学構造や実験条件をモデルが提案することを防ぐためです。よく言われていることとして、オレオレ詐欺の被害にあった人は、もうオレオレ詐欺の被害にはあわない、みたいなことですね。よくない結果となる化学構造や実験条件をモデルが提案することを防ぐため、ある化学構造や実験条件ではよくない結果であったという情報が必要です。よくない結果があれば、その周辺の化学構造や実験条件は探索されなくなりますので、他によい結果になる化学構造や実験条件の領域があるときに、それが提案される可能性が高くなります。モデルの適用範囲を考えても

サンプルが増えることで、モデルの適用範囲は大きくなります。ネガティブデータがありますと、そのサンプルの周辺の範囲も適切に予測でき、その範囲ではよい結果にはならないことがわかりますので、他の X の範囲において、化学構造や実験条件が選択されるわけです。
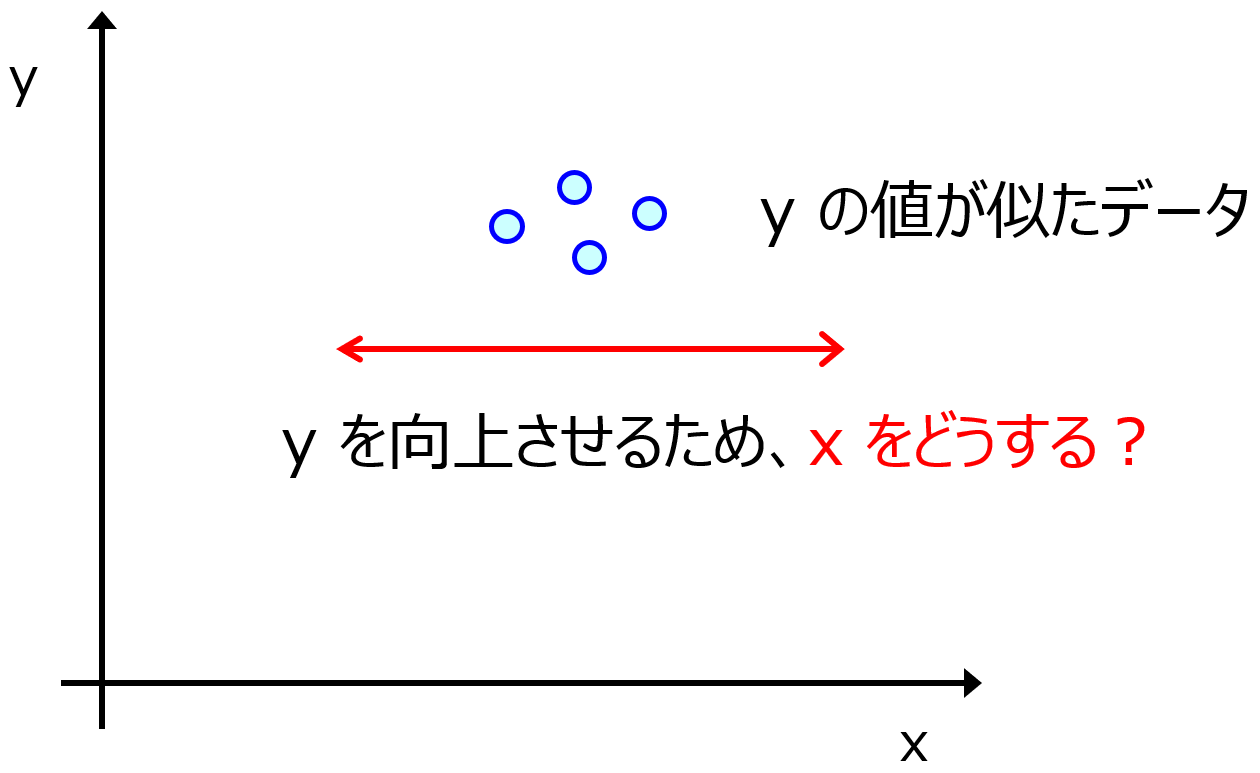
もう一つの理由は、物性・活性・特性 Y をさらによい値にするために X をどの方向に変化させればよいか検討するための情報になるからです。下の図のように、Y の値がよい実験結果しかないと、Y の値がさらによい値になるために、X の値をどちらに変化させればよいかわかりません。
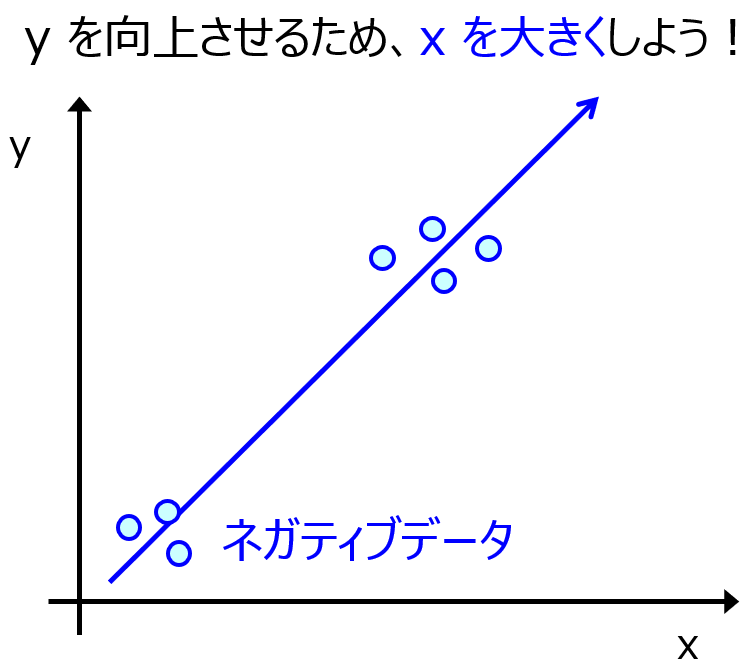
下のようにネガティブデータがあれば、そのデータがある X の方向とは逆の方向に X の値を変化させよう!、と判断するための情報になります。
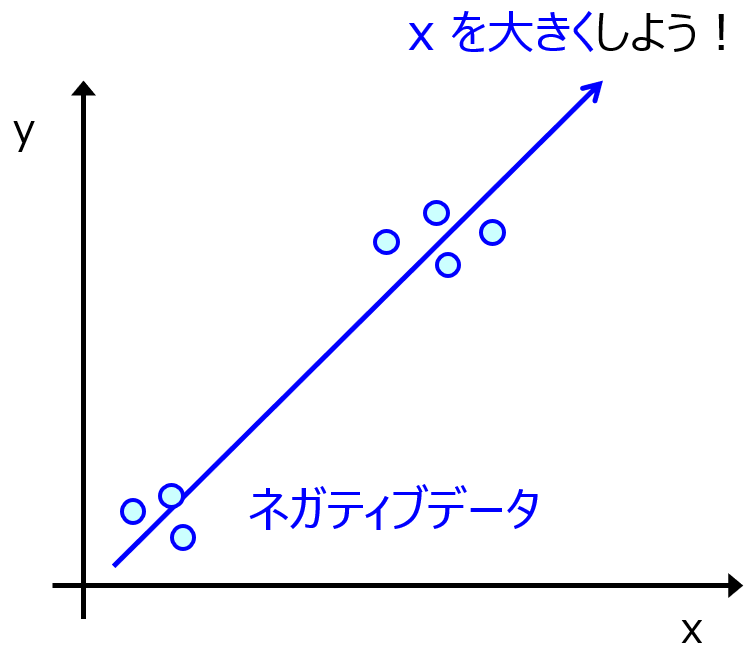
このように、ネガティブデータもよりよい Y の値をもつ分子・材料を設計するために重要です。もし既存の実験データにネガティブデータがあれば、それもデータセットに追加するとよいです。また、新たに実験した結果、Y の値が向上せずにネガティブデータになったとしても、そのデータを活用してモデルを改良して、さらに次の化学構造・実験条件を探索しましょう。
以上です。
質問やコメントなどありましたら、twitter, facebook, メールなどでご連絡いただけるとうれしいです。

