解像度を上げるといっても、画素の密度を上げるわけではなく、より詳細に検討するということです。
回帰分析をしたら、以下のような目的変数の実測値 vs. 推定値プロットが得られたとしましょう。
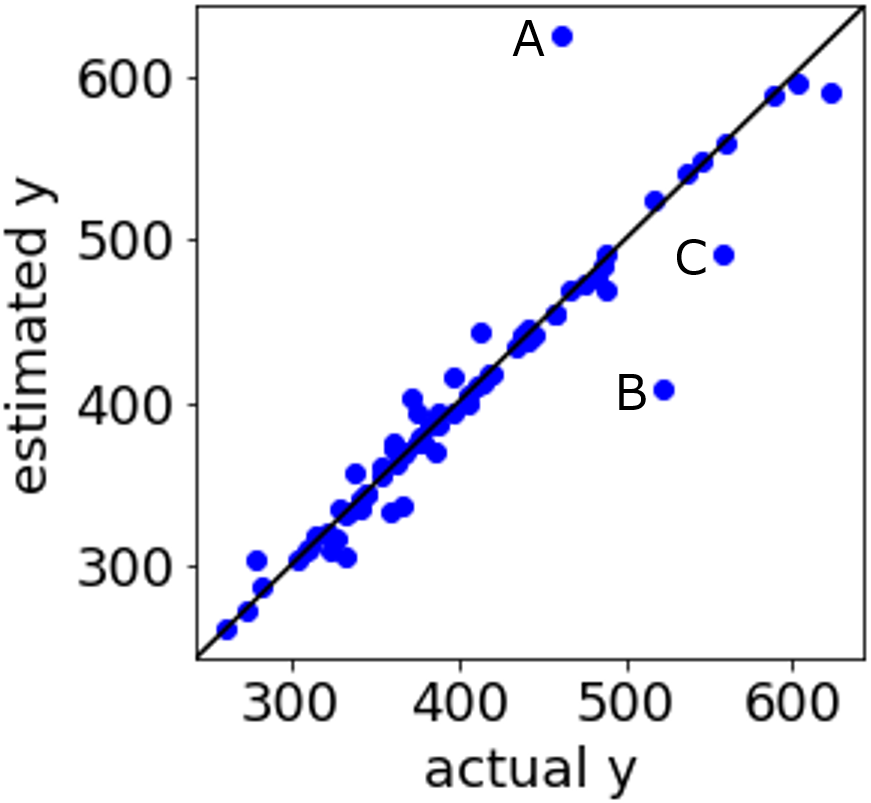
ちなみにこのプロットは、こちらの論文にある沸点のデータセットを用いて、目的変数を沸点、説明変数を RDKit で計算した記述子との間で、トレーニングデータ 220 サンプルを用いて構築されたサポートベクター回帰 (Support Vector Regression, SVR) モデルで、テストデータ 74 サンプルを推定した結果です。SVR の詳細はこちらをご覧ください。

上の実測値 vs. 推定値プロットにおいて、多くのサンプルは対角線付近に固まっています。精度良く推定できていますね。ただ、A, B, C のようにいくつか対角線から外れているサンプル、つまり推定誤差の大きいサンプルもあります。
A, B, C のサンプルの誤差が大きい原因を考えてみましょう。以下のことが考えられます。
- トレーニングデータに類似したサンプル (今回は化合物) がない、つまり A, B, Cがモデルの適用範囲外)
- 回帰モデルが目的変数 (今回は沸点) を説明できるほど学習できていない
- 現状の記述子では目的変数を説明できない
- 沸点の実測値が間違えている
原因 1. を検討するためにはモデルの適用範囲 (Applicability Domain, AD) を考える必要があります。AD の詳細はこちらをご覧ください。

アンサンブル学習により AD を設定します。アンサンブル学習による AD についてはこちらをご覧ください。

サブモデルの数を 50、選択される記述子の数の割合を 0.8 にしたときに、SVR でアンサンブル学習をしたところ、テストデータにおける沸点の推定値の標準偏差と誤差の絶対値の関係は下図のようになりました。
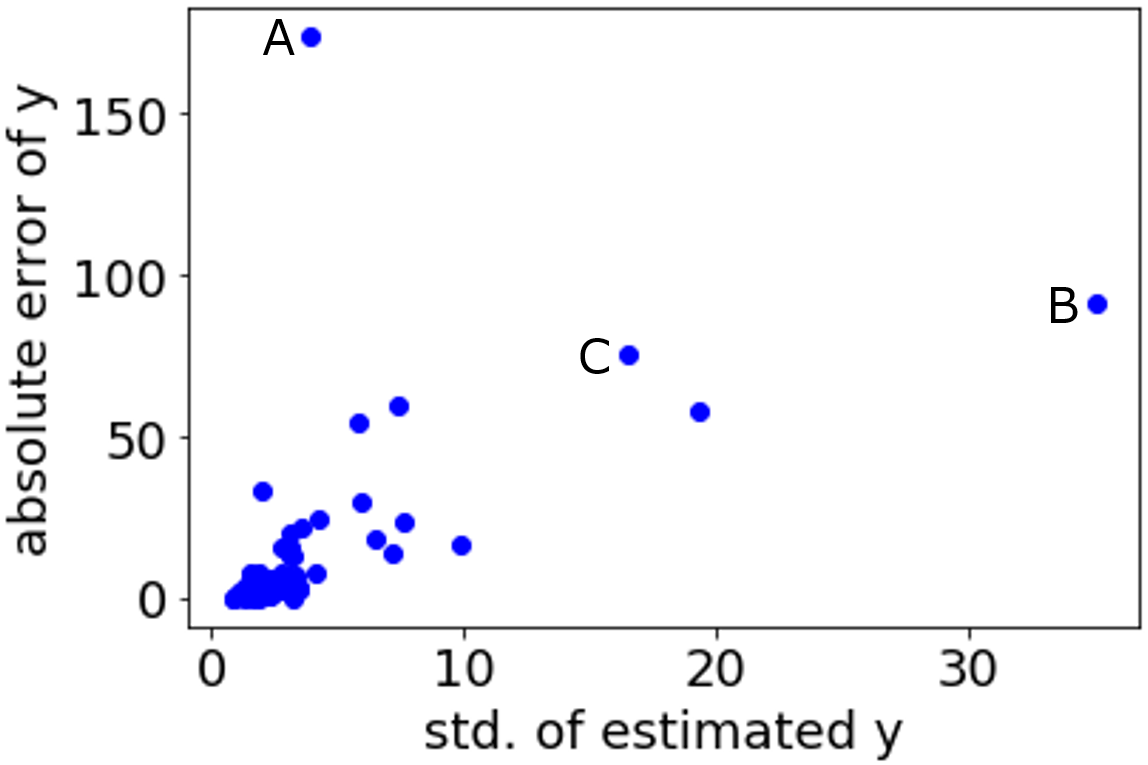
沸点の推定値の標準偏差が大きいときに、誤差の絶対値のばらつきも大きい傾向があることが確認できます。しかし、A のサンプルにおいては、推定値の標準偏差が小さいにもかかわらず、誤差の絶対値が大きいことがわかります。トレーニングデータに類似した化合物がないとは考えにくいです。誤差が大きい原因として、2. 3. 4 のどれかであることがわかります。もちろん B, C のサンプルにおいても、2. 3. 4. が原因の可能性もあります。
原因 2. を検討するためには、SVR 以外の回帰分析手法も検討する必要があります。原因 3. を検討するためには、誤差の大きなサンプル (今回は化合物) と記述子の値が類似したサンプルや、化学構造的に類似したサンプルや、沸点の値が近いサンプルを調べてみましょう。原因 4. を検討するためには、沸点の実測値データを確認する必要があります。
回帰モデルを用いて、新たなサンプルを推定するときにも注意が必要です。誤差が大きいサンプルにおいて対処できず、記述子やサンプルを変更せずに SVR モデルで沸点を推定する場合は、これらのサンプルと類似したサンプルも同様にして大きな誤差をもつ可能性があります。注意しましょう。
以上です。
質問やコメントなどありましたら、twitter, facebook, メールなどでご連絡いただけるとうれしいです。