昨年度も 3 月に金子研の学生たちが卒業していきました。少し遅くなってしまいましたが、2018 年度の学生の研究成果をまとめておきます。
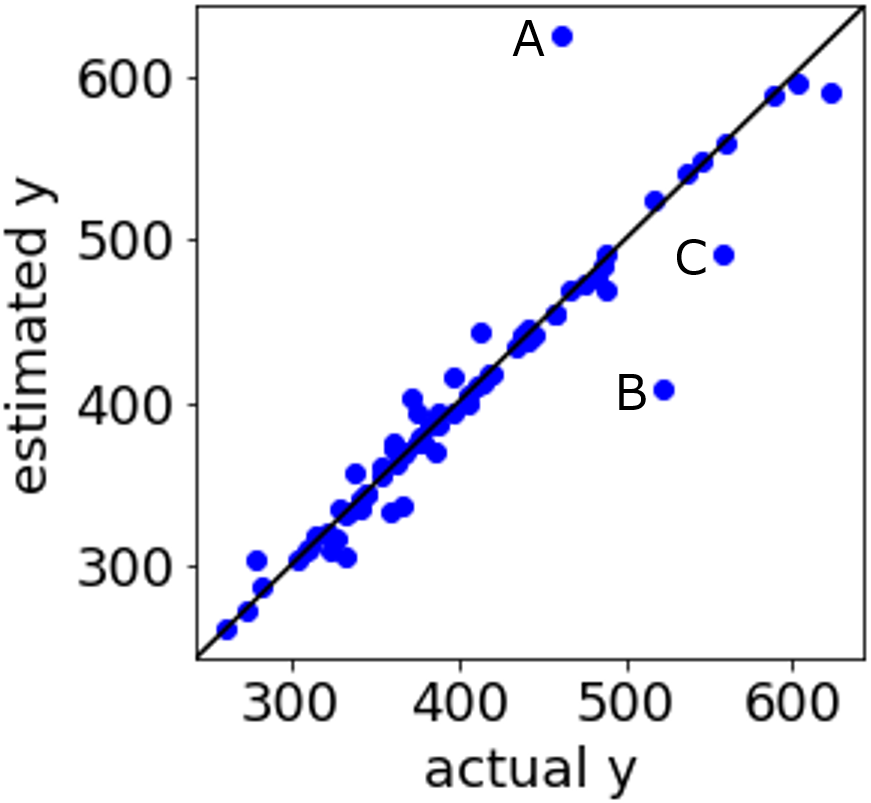
江尾は医薬品設計に関する研究です。活性の測定された化合物を用いて、活性 y と記述子 x との間で機械学習によりモデル y=f(x) を作成します。このとき、モデルの性能を上げるため、記述子にドッキングシミュレーションの結果を追加します。ちなみに、1 つのドッキングシミュレーションソフトではなく、いくつかのソフトの結果を組み合わせます。新しい化学構造に対して、活性の値を推定したい場合は、その化学構造の記述子を計算するとともに、ドッキングシミュレーションを行い、それらの結果をモデルに入力します。ドッキングシミュレーションを併用することで、すべての場合でモデル y=f(x) の性能が向上するわけではありませんでしたが、うまくドッキングシミュレーションの記述子を選択することで、推定精度が向上したり、活性の高い化合物をより精度良く推定できたりすることを確認しました。研究成果を構造活性相関シンポジウムや日本化学会の年会で研究発表しました。
高野はポリマー設計に関する研究です。ポリマーを重合する前のモノマーの化学構造 x から、ポリマーの物性 y を推定しようというものです。物性として、屈折率をガラス転移温度の 2 つを対象にしました。モノマーの化学構造といっても自由結合手がある形で表現されていますので、その前処理方法についても検討もしました。さらに回帰分析手法を検討し、ベストな回帰モデル y=f(x) を構築して屈折率・ガラス転移温度の両方とも高くなるようなポリマーを達成可能な、モノマーの仮想的な化学構造を設計しました。
田中は分子の記述子に関する研究です。化学構造 x から物性や活性 y を推定するモデル y=f(x) を構築するときに重要なことの 1 つとして、物性や活性を推定するために必要十分な情報を、化学構造から獲得することがあげられます。2 次元の記述子だけでも十分かもしれませんが、3 次元の記述子が必要になる物性・活性もあるかもしれません。物性として水溶解度や融点、薬理活性や毒性などを対象にして、量子化学的な 3 次元記述子の検討をしていました。
佐藤はモデル構築、特にアンサンブル学習における研究です。アンサンブル学習では、サンプルや説明変数を変えてたくさんのデータセット (サブデータセット) を準備して、それぞれでモデル (サブモデル) を構築します。新しいサンプルにおける目的変数の値を推定するときは、すべてのサブモデルから得られる推定値を平均したり中央値をとったりして、推定します。ただ、目的変数の値を推定したいサンプルによって、サブモデルごとに AD 内になったり AD 外になったりする可能性があります。そこで、予測したいサンプルごとに AD でサブモデルごとに重みを設定する手法を開発しました。いくつもの化合物群で推定性能が向上することを検証しています。
井上は石炭の物性推定に関する研究です。公共のデータベースを用いて、元素組成・酸化物含有割合・水分含有割合・灰分含有割合・揮発性物質含有割合・固定炭素割合を説明変数として、ハードグローブ粉砕性指数 (Hardgrove Grindability Index, HGI) を目的変数として、回帰モデルを作成しました。さらに、LASSO や EN といった変数選択手法を検討して、HGI を推定できるモデルの解釈も試みました。LASSO や EN の詳細についてはこちらをご覧ください。
山田はプロセス設計に関する研究です。プロパン製造プラントを対象にして、プロセスシミュレータと機械学習で効率的にプロセス設計をしました。シミュレーションを回して、得られたデータを使ってモデルを構築し、モデルに基づいて次にシミュレーションする候補を探索して、、、を繰り返すことで、だんだんプラントの性能がよくなるシステムを作りました。化学工学会の年会で研究発表しました。
正木はプラントの異常に関係するプロセス変数の診断に関する研究です。異常が検出されたら、異常な状態で測定されたサンプルと、正常な状態で測定されたサンプルとを用いて、決定木を作ります。構築された決定木を見ることで、異常に関係するプロセス変数やそのルールを確認できるわけです。
M1 の清水はモデルの解釈に関する研究です。決定木でサブデータセットを作成してから、サブデータセットごとに回帰モデルを作ります。サブデータセットごとの回帰モデルを解釈することで、すべてのサンプルで構築された回帰モデルより詳細な解釈の結果を得ることができます。さらに、モデルの適用範囲を考慮して発生させた仮想サンプルを分類することで、解釈の結果を確認したりもしました。有機化合物のデータセットだけでなく、無機化合物のデータセットでも有効性を検証しています。日本化学会の年会で研究発表しました。
M1 の菅野はソフトセンサーに関する研究です。プロセスにおける動特性を考慮しつつ、モデルの劣化の低減をさせるため、非線形の低次元化手法に着目しました。多くの説明変数から低次元化したパラメータと目的変数の間で、適応型ソフトセンサーの 1 つである Just-In-Time (JIT) モデリングにより目的変数の値を推定します。アンサンブル学習を活用したり、サブモデルへの重み付けを工夫したりもして、ソフトセンサーの推定性能向上を達成しました。化学工学会の年会で研究発表しました。
M1 の小島はディープニューラルネットワークのソフトセンサーに関する研究です。プラントで用いるソフトセンサーとして、ディープニューラルネットワークを採用するかどうか検討したり、実際に採用したりするときには、ディープニューラルネットワークの構成を決める必要があります。そこで層の数、層ごとのニューロンの数、活性化関数などを、自動的に最適化する手法を開発しました。バリデーションデータを使うとトレーニングデータのサンプル数が減ってしまうため、クロスバリデーションを含めてバリデーションデータは用いない方針で進めています。
以上です。
質問やコメントなどありましたら、twitter, facebook, メールなどでご連絡いただけるとうれしいです。