データ解析・機械学習において、「データ」 の話をするとき、いろいろな用語が飛びかいます。サンプル、特徴量、記述子、変数、説明変数、目的変数、データ、データセットなどです。データ解析や機械学習の議論をするとき、人によって用語の使い方が違うと、誤解が生じてしまったり、議論が進まなかったりする恐れがありますので、ここではそれらの用語を整理します。
あやめの「データ」を用いて説明します。
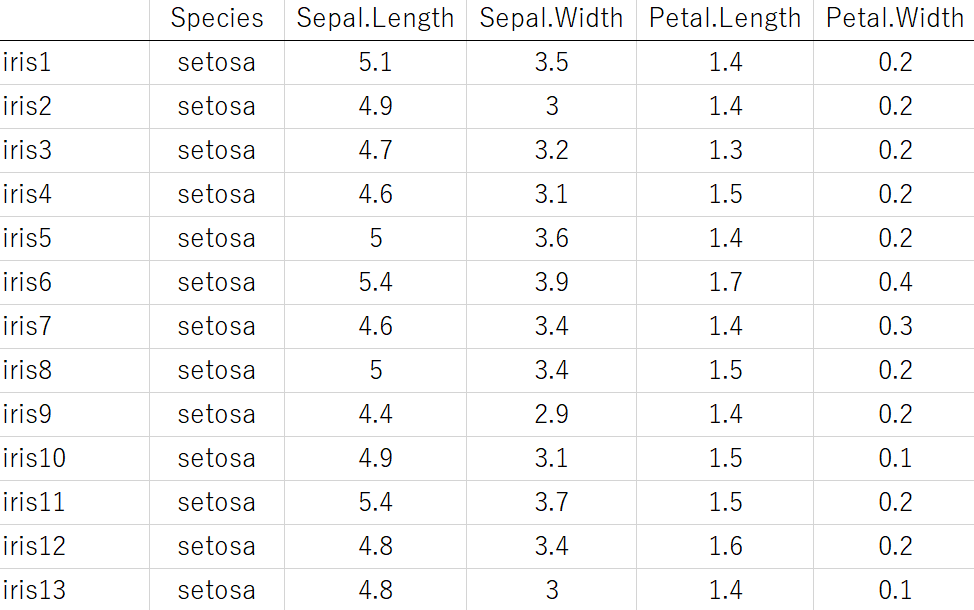
3 種 (setosa, virginica, versicolor) のあやめ (iris) 150 個について、がく片長 (Sepal Length)、がく片幅 (Sepal Width)、花びら長 (Petal Length)、花びら幅 (Petal Width) が計測されています。
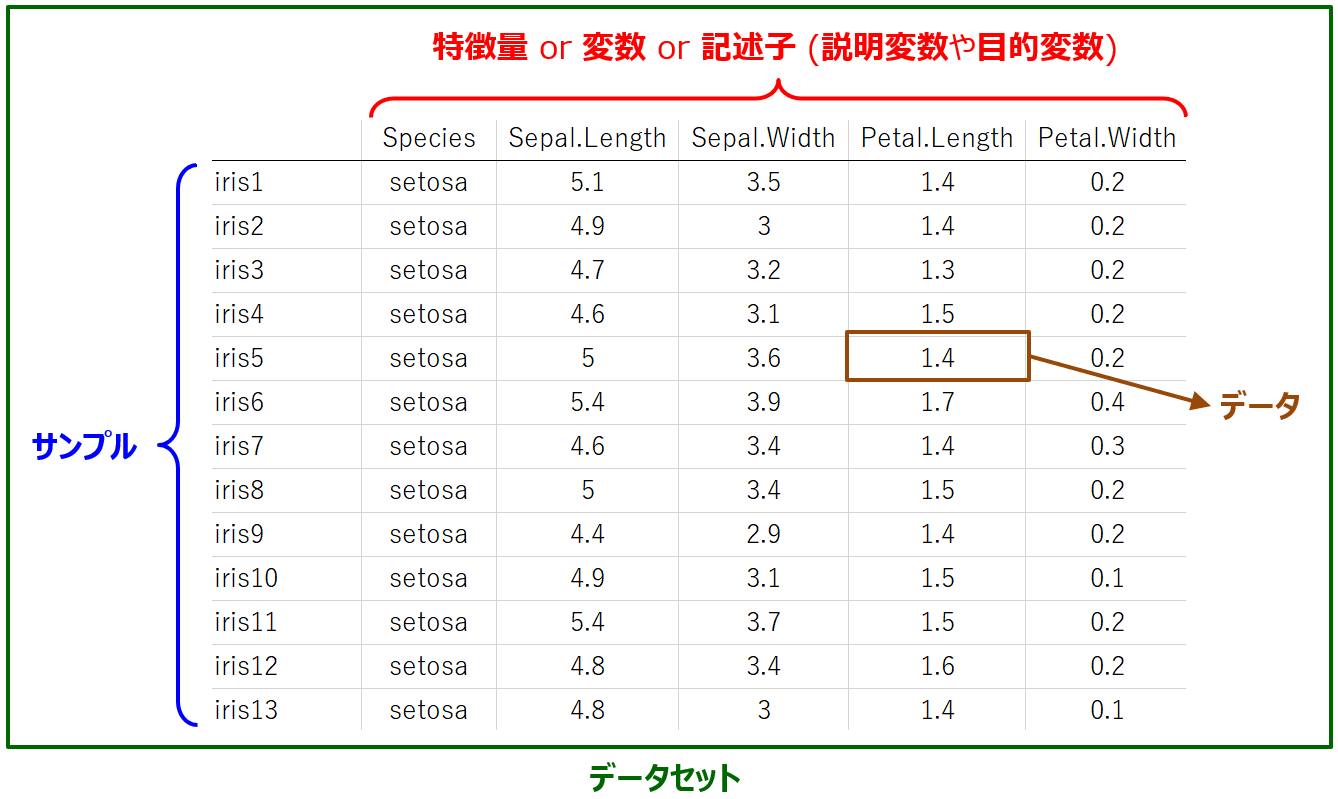
上の図をご覧ください。図における、あやめそれぞれがサンプル (sample) に対応します。ケモインフォマティクスやマテリアルズインフォマティクスにおいては、化合物や分子構造を扱いますので、一つの分子や一つの材料などがサンプルになります。ソフトセンサーなどのプロセスインフォマティクスにおいて時系列データを扱うときは、時刻ごとの温度や圧力などのプロセス変数の測定値を扱いますので、ある時刻における測定値のセットがサンプルになります。
図において上に横に並んでいるのが特徴量 (feature) もしくは変数 (variable) もしくは記述子 (descriptor) です。特徴量 = 変数 = 記述子 とお考えください。特徴量の中には、回帰分析やクラス分類における目的変数や説明変数が含まれます。ケモインフォマティクスやマテリアルズインフォマティクスにおいては、分子の化学構造を数値化したもの(分子記述子や構造記述子、たとえば分子量など) や、実験条件・合成条件・製造条件などが特徴量です。プロセスインフォマティクスにおいては、温度や圧力、各種の物性や活性、製品品質などのプロセス変数が特徴量となります。
あやめにおけるがく片長 (Sepal Length) のように連続値の特徴量もあれば、あやめの種類 (Species) のようにカテゴリーの特徴量もあります。
あるサンプルにおける、ある特徴量の値がデータ (data) です。データは、ある値であったり、あやめの種類のようにカテゴリーであったりします。
最後に、図の全体をまとめてデータセット (dataset) と呼びます。この意味では、今回例にしたのはあやめのデータセットということになります。
これらの用語を整理して使用することで、データ解析や機械学習に関する議論がスムーズに進むようになれば嬉しいです。
以上です。
質問やコメントなどありましたら、twitter, facebook, メールなどでご連絡いただけるとうれしいです。

