
金子研の論文が Computers & Chemical Engineering に掲載されましたので、ご紹介します。タイトルは
です。
この研究の目的は、バッチプロセスにおけるバッチ時間の異なるデータセットを用いた機械学習により、バッチプロセスで合成する材料の物性や製造する製品の品質が目標値になるように、バッチ時間およびプロセス変数ごとのプロファイル (温度プロファイルなど) を、プロファイルに一切の制限をかけずに設計することです。
バッチプロセスの終点における物性や製品品質を目的変数 y、バッチ時間とプロセス変数の時系列データを説明変数 x として数理モデル y = f(x) を Gaussian Mixture Regression (GMR) によって構築します。
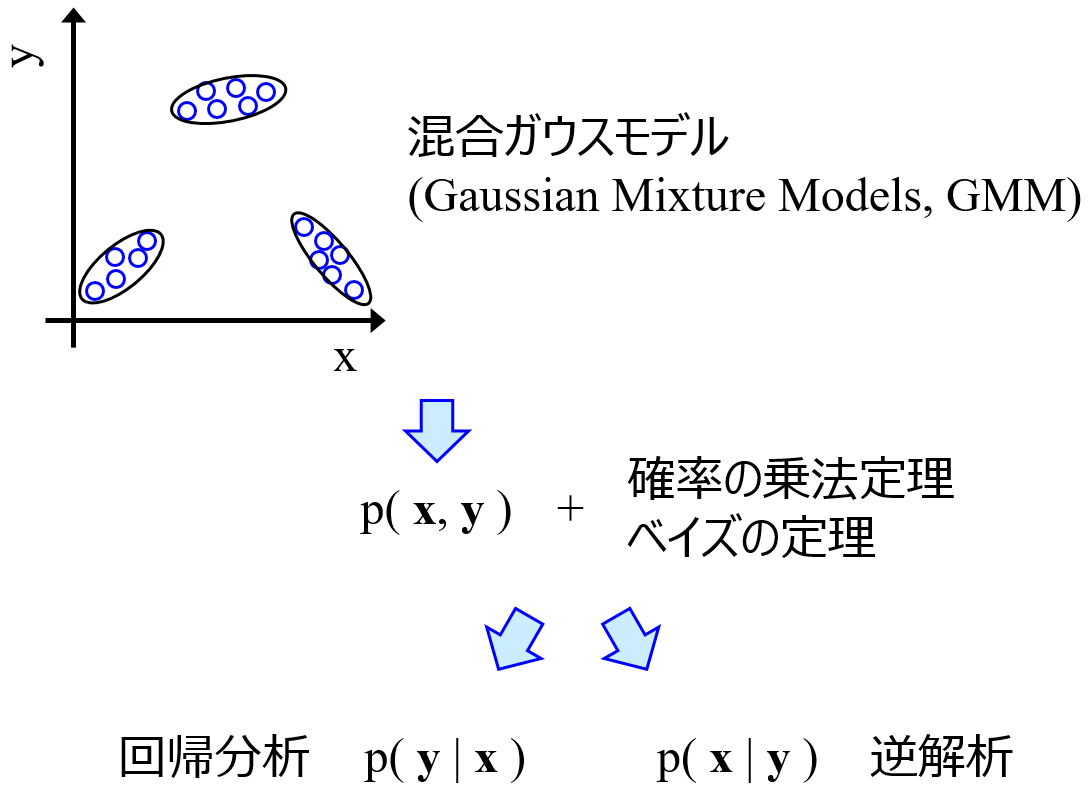

GMR は直接的逆解析ができるため、y の値 (目標値) を GMR モデルに入力して、直接的に x の値を予測できます。
ここで考えなければならないことは、バッチプロセスの x をどうするかです。一般的には、プロセス変数ごとに時系列データを横に並べたものを x とします。例えば 5 つのプロセス変数 (温度・圧力・流量など) で 60 分の時系列データ (毎分のデータ) があるとき、x の変数の数は 5 × 60 = 300 になります。この方法では、バッチ時間を 60 分などに揃える必要があり、55分だったり 65 分だったり、異なる時間のバッチがあると同じデータセットして扱えません。
そこで今回は、バッチ時間が異なるバッチを含むデータセットを扱うため、x を補完した後に GMR モデルを構築する方法と、フーリエ変換によって時系列データを変換した後に GMR モデルを構築する方法を提案しました。フーリエ変換では、y の値から直接的逆解析によって求められた x の値を逆フーリエ変換することで、プロセス変数の時系列データに戻すことも可能です。
数値シミュレーションのバッチプロセスと fed-batch bioreactor プロセスにおける検証より、提案手法により的確にバッチプロセスの終点における物性や製品品質を予測できることと、y の目標値を実現するためのバッチ時間とプロセス変数のプロファイルを最適化できることを確認した。さらに、シミュレーションデータではトレーニングデータにおける y のレンジが 400 から 1900 までのときに、y の値を 0 にするプロセス変数のプロファイルを設計でき、fed-batch reactor ではトレーニングデータにおける製品濃度を 50% 増加させるプロセス変数のプロファイルを設計することに成功しました。
興味のある方は、ぜひ論文をご覧いただければと思います。
以上です。
質問やコメントなどありましたら、twitter, facebook, メールなどでご連絡いただけるとうれしいです。

