
分子設計・材料設計・プロセス設計・プロセス管理において、分子記述子・実験条件・合成条件・製造条件・評価条件・プロセス条件・プロセス変数などの特徴量 x と分子・材料の物性・活性・特性や製品の品質などの目的変数 y との間で数理モデル y = f(x) を構築し、構築したモデルに x の値を入力して y の値を予測したり、y が目標値となる x の値を設計したりします。
例えば、ポジティブデータ(1)とネガティブデータ(−1)を用いてクラス分類モデルを構築する時、基本的にポジティブデータのサンプルもネガティブデータのサンプルも存在します。もちろんサンプルの割合が1:1とは限らないため、比率が大きく異なる時にはうまく調整して対処します。
一方で、ポジティブデータのサンプルもしくはネガティブデータのサンプルが全くない状況も存在します。例えば、活性のない化合物しか存在しないとか、薬物間相互作用をする化合物ペアしか存在しない場合です。普通に考えるとクラス分類モデルを構築できませんが、ポジティブデータもしくはネガティブデータを仮に設定してモデルを構築する方法があります。ここではネガティブデータが全くない状況を想定しますが、ネガティブデータをポジティブデータに置き換えれば、ポジティブデータが全くない状況でも対応可能です。
まず、ポジティブデータのサンプル以外の未ラベルのサンプル (ポジティブデータかネガティブデータか不明なサンプル) を不明サンプルとします。例えば、活性があるか不明な化合物や、薬物間相互作用するかどうかのデータがない化合物ペアなどです。これらのサンプルはポジティブデータでもネガティブデータでもある可能性があり、それを踏まえて活用してクラス分類モデルを構築します。
不明サンプルを活用する1つの方法は、ポジティブデータのサンプルが存在する領域を設定し、その領域以外に存在する不明サンプルをネガティブデータとみなす方法です。ポジティブデータでモデルの適用範囲を設定するイメージです。

例えば、ポジティブデータのみで one-class support vector machine モデルを構築し、サンプルを予測した時にサポートされない(−1と判断された)サンプルをネガティブデータと設定します。得られたネガティブデータと元々のポジティブデータの間でクラス分類モデルを構築します。
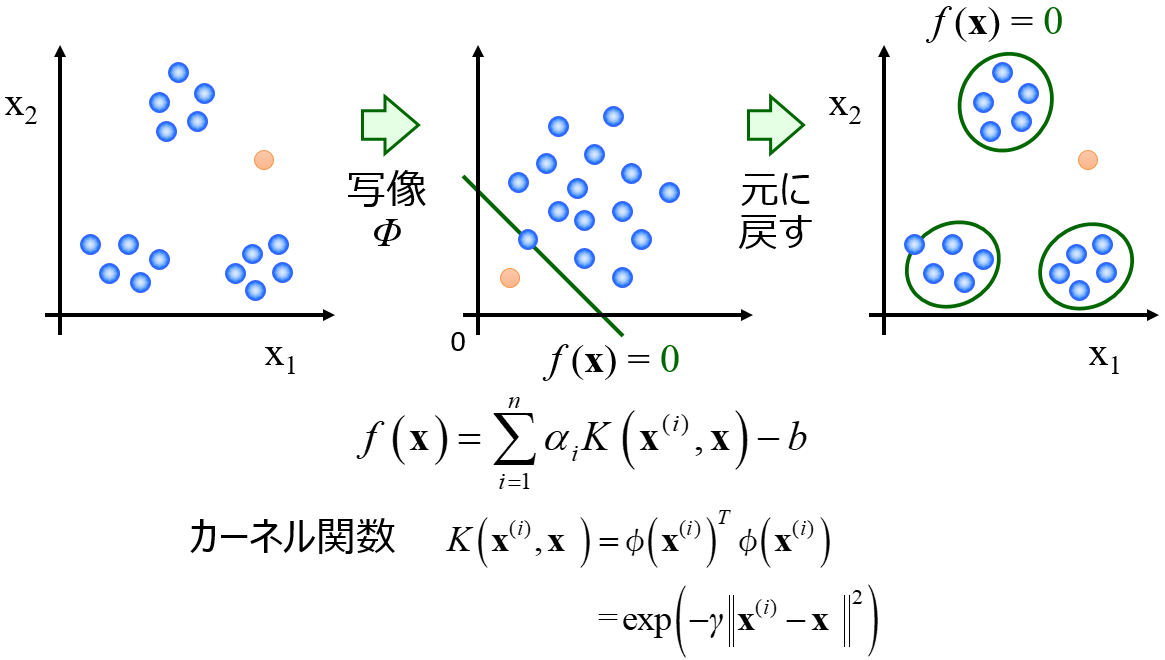
詳細についてこちら↓の論文が参考になるかと思います。
不明サンプルを活用するもう1つの方法は、不明サンプルからランダムにサンプルを選択して (仮の) ネガティブデータと設定し、ポジティブデータのサンプルと共に用いてクラス分類モデルを構築することを、繰り返します。繰り返した数だけクラス分類モデルが構築され、予測したい新しいサンプルはすべてのモデルに入力され、ポジティブかネガティブかを判断します。ポジティブと判断されたモデルの数が多いほど、そのサンプルがポジティブである可能性が高いと考えられます。
詳細についてこちら↓の論文が参考になるかと思います。


不明サンプルを活用するどちらの方法も、ネガティブデータとしたサンプルが必ずしも真のネガティブデータではないため、予測結果については別途検証が必要ですが、ネガティブデータが存在しないような状況で、ポジティブの可能性が高いサンプルを抽出する上で有効な手法です。ポジティブデータしかない、もしくはネガティブデータしかないといった状況では、ぜひ検討すると良いでしょう。
ちなみに、ネガティブデータのサンプルが全く存在しないわけではなく、少数だけ存在する場合は、上記の方法でネガティブデータと設定したサンプルに真のネガティブデータのサンプルも追加してモデルを構築したり、構築されたクラス分類モデルの評価に真のネガティブデータのサンプルを用いたりすると良いでしょう。もちろん、アンダーサンプリングやオーバーサンプリングなどを活用して、真のネガティブデータとポジティブデータのみでモデルを構築することも考えられます。比較検討して、最終的に使用するモデルを決定すると良いでしょう。
以上です。
質問やコメントなどありましたら、X, facebook, メールなどでご連絡いただけるとうれしいです。
