化学プラント・産業プラントにおいて、測定することが難しいプロセス変数の値を、コンピュータでリアルタイムに推定するため、ソフトセンサーが活用されています。
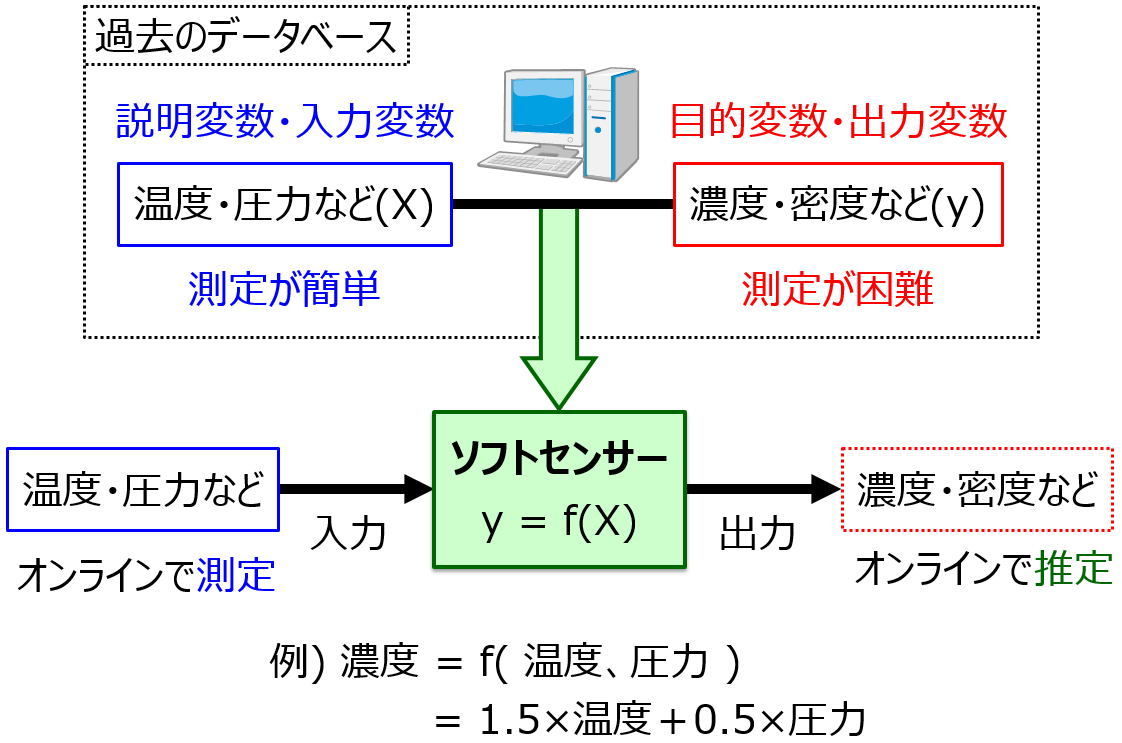
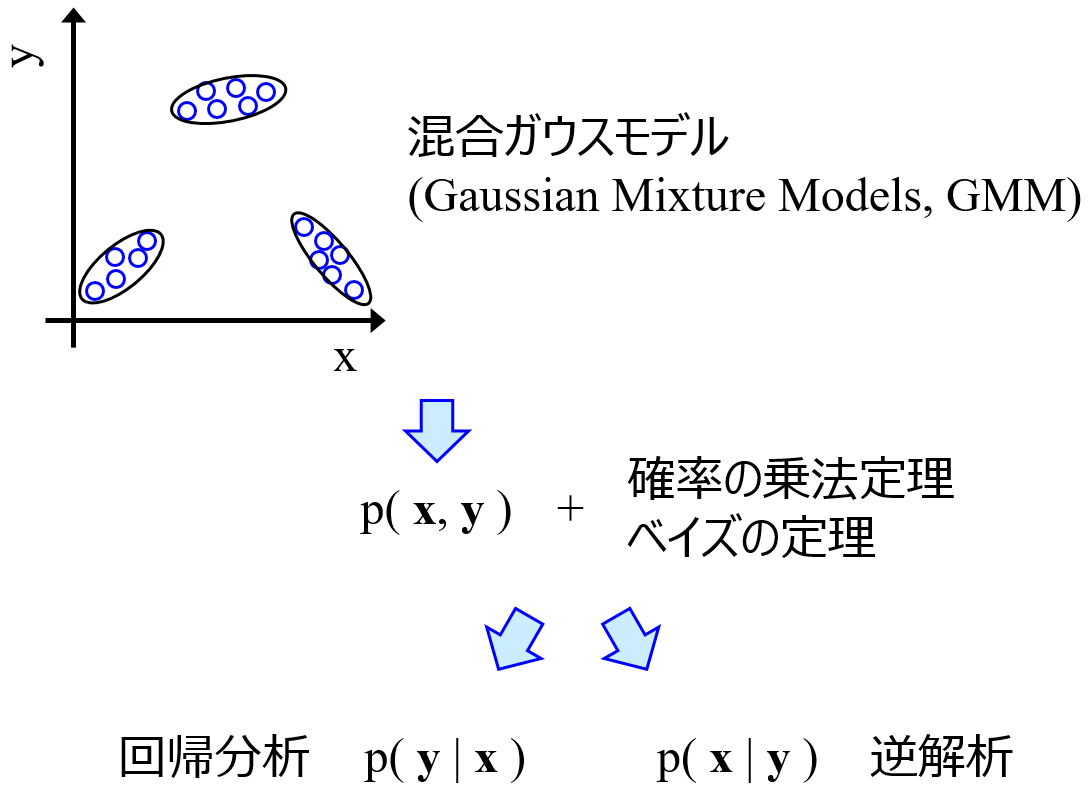
“ソフトセンサー” とかっこいい名前がついていますが、結局はあるいくつかのプロセス変数 X と別のプロセス変数 y との間で構築された回帰モデル y=f(X) のことです。データセットを用いて、PLSやSVRなどで X と y の間の回帰モデルを構築します。このあたりは QSPR・QSAR と同じですね。X をリアルイムに測定できる変数にして、y を測定が難しい変数にすると、X の値を y=f(X) に入力することで y の値をリアルタイムに推定できます。
便利なソフトセンサーですが、問題もあります。最も大きな問題の一つが、モデルの劣化です。モデルの劣化とは読んで字のごとく、回帰モデルの推定性能が劣化 (低下) してしまうことです。測定した y の値と推定した y の値とがあわなくなってしまうわけです。
なぜモデルの劣化が起きてしまうか、つまり推定誤差が大きくなってしまうかというと、原因の一つはプラントにおけるプロセス状態が変化すること、といわれています。たとえば、
- 原料におけるいろいろな化合物の組成が変わる
- 反応器における触媒が劣化する
- 配管などに汚れがつく
- 外気温が変わる
といった具合に、プロセス状態が変化します。これにより、X と y との関係が、モデルを構築したときの関係から変わってしまいます。y=f(X) の関係と、新しい時刻との関係とが異なるため、新しく推定したときの誤差が大きくなってしまうわけです。なお、センサーなどの測定機器がドリフトすることでも、モデルの劣化は起こります。
ソフトセンサーを長期間運用するためには、モデルの劣化を防がなければいけません。ソフトセンサーの性能を高いまま維持するわけですね。
そこで着目するのは、こちらにも書いた
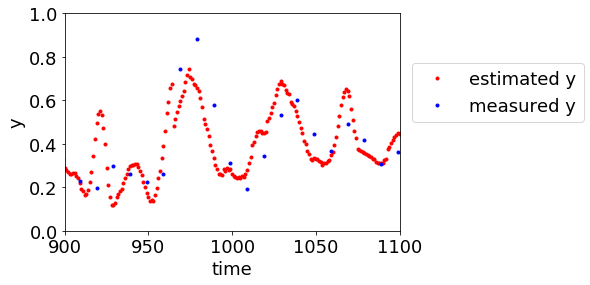
トレーニングデータが更新される
ということです。y は測定が困難なプロセス変数とはいっても、ある程度定期的に測定されています。もちろん X についても測定されていますので、回帰モデルを構築するためのトレーニングデータが増えていきます。データベースが更新されるわけですね。このあたりは QSPR・QSAR とは異なることかもしれません。
新たに測定されたサンプルには、新たなプロセス状態の情報が含まれていると考えて、このサンプルも活用して新たなソフトセンサー (回帰モデル) を構築しなおします。このようなソフトセンサーのことを、適応型ソフトセンサーといいます。新たに測定されたサンプルを活用して、新しいプロセス状態にソフトセンサーを適応させていくわけですね。
ただ、トレーニングデータが更新されるごとに、人がソフトセンサーを構築しなおさなければならないとすると、とても大変です。時間的にコストがかかってしまいます。そこで、自動的に推定性能を維持する適応型ソフトセンサーの仕組みが開発されてきました。
そのような適応型ソフトセンサーは大きく3種類に分けることができます。それは
- Moving Window (MW) モデル
- Just-In-Time (JIT) モデル
- 時間差分 (Time Difference, TD) モデル
です。順に説明します。
1. Moving Window (MW) モデル
直感的にはこれが一番理解しやすいかもしれません。新しいサンプルをトレーニングデータに追加して、最も古いサンプルを削除して、再度回帰モデルを構築します。トレーニングデータの数が 100 のとき、新しいサンプルを追加すると 101 になり、最も古いサンプルを削除すると 100 に戻ります。つまりトレーニングデータの数は固定なわけです。新しいサンプルの測定時刻と最も古いサンプルの測定時刻との間の幅 (窓、window) を移動 (moving) しながら、モデルの再構築を繰り返すことから、Moving Window (MW) モデルといわれています。
MWモデルにより、新しいプロセス状態に追随するように、回帰モデルを再構築することができます。
注意点として、トレーニングデータの数 (窓枠の幅) を決めなければいけません。トレーニングデータの数を小さくすると、新しいプロセス状態に追随しやすい一方で、多様性のない同じようなプロセス状態におけるサンプルしかトレーニングデータに含まれない傾向があります。トレーニングデータの数を大きくすると、様々なプロセス状態で測定されたサンプルがトレーニングデータに含まれることでデータの多様性がある一方で、新しいプロセス状態に追随しにくくなってしまいます。このあたりは試行錯誤が必要です。
2. Just-In-Time (JIT) モデル
Just-In-Time (JIT) モデルは、推定したい X の値と近いトレーニングデータにおけるサンプルのみ用いたり、推定したい X の値と近いほどトレーニングデータの重みを大きくしたりして、回帰モデルが構築されます。” 推定したい X の値と近い” とは、たとえば X の距離が近いということです。距離として、ユークリッド距離やマハラノビス距離などいろいろ用いることができますし、距離でなくてもいろいろな類似度の指標を “近さ” として使用できます。
MW モデルでは、新しく y の値が測定されたら回帰モデルが再構築されますが、JIT モデルでは、y の値を推定するごとに回帰モデルが再構築されます。まさに、ジャストインタイム方式です。
こちらで説明した LWPLS も JIT モデルの一つです。
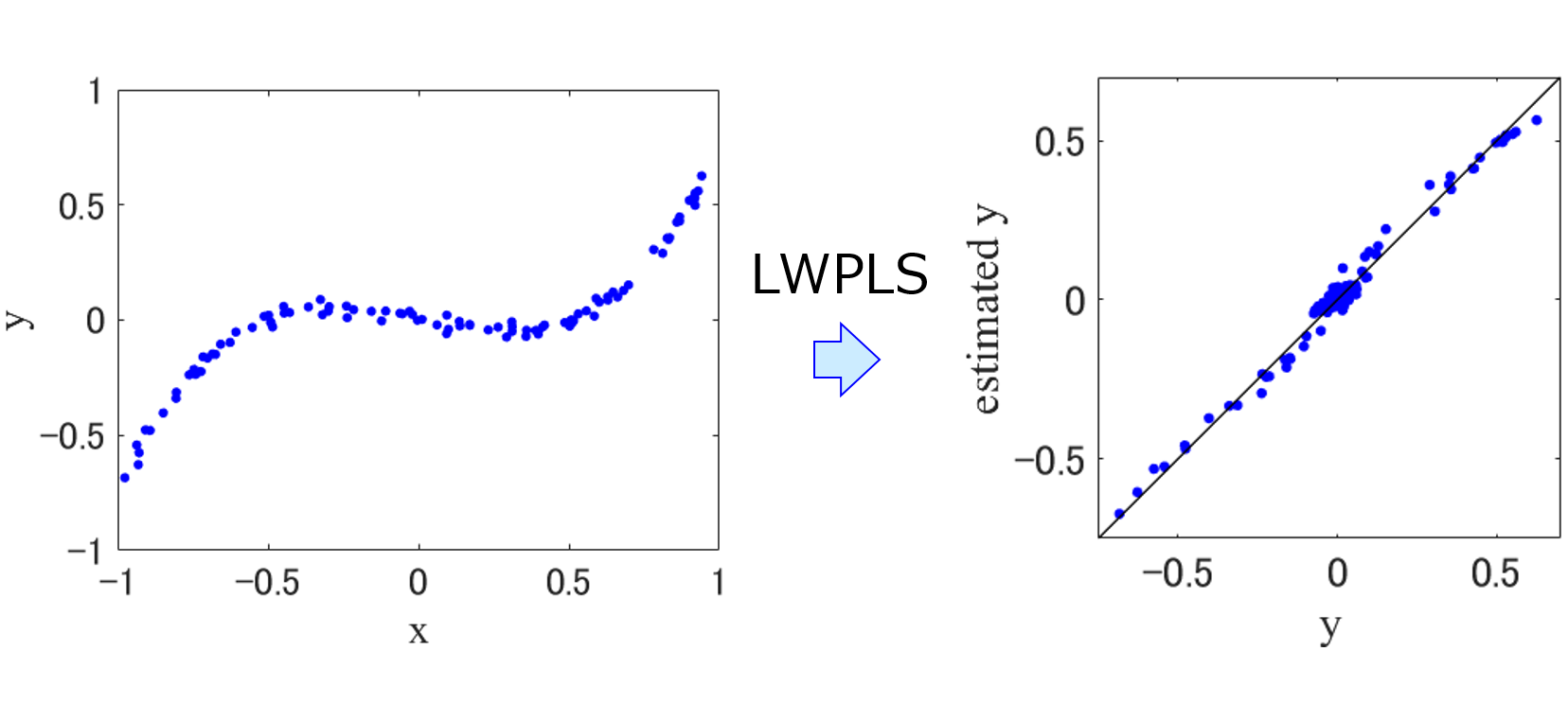
JIT モデルでも、トレーニングデータの数 (データベースに含まれるサンプルの最大数) を事前に決めなければなりません。ここでも、MW モデルでの議論と同様の議論があります。さらに、JIT モデルは y の値を推定するごとに、たとえば毎分、モデリングしなければいけませんので、リアルタイムに推定するためにはモデリング時間を短くしなければいけません。トレーニングデータの数が大きくなると、モデリングにかかる時間も大きくなってしまいますので、この y の値の推定にかかる時間であるモデリング時間も考慮してトレーニングデータの数を決定する必要があります。
またトレーニングデータからモデル構築に用いるサンプルを選択するタイプの JIT モデルのとき、いくつのサンプルを選択するかも決めなければいけません。ここでも試行錯誤が必要です。ちなみに、LWPLS ではこのような決定は必要ありません。
3. 時間差分 (Time Difference, TD) モデル
これまで回帰モデルは、X の値と y の値との間で構築されてきました。時間差分 (Time Difference, TD) モデルでは、X の時間差分の値と y の時間差分の値との間で回帰モデルが構築されます。時間差分は、ある時刻の X・y のサンプルから、その前の時刻の X・y のサンプルを単純に引くことで計算されます。なので、時間差分のサンプルの数は、元のサンプルの数と比べて、一つ少ないです。
y の値を推定するときは、まず推定したい時刻の X の値から、直近に y が測定された時刻の X の値を引くことで、X の時間差分を計算します。それを TD モデルに入力することで、y の時間差分の値を推定できます。それを、直近の y の測定値に足し合わせることで、y の値を推定します。
実は、TD モデルでは回帰モデルは再構築されません。更新されるのは、推定された y の時間差分の値に足し合わされる、直近の y の実測値です。TD モデルは、y のバイアス補正を包含するモデルです。つまり、y のバイアス補正の効果が得られるだけでなく、回帰モデル構築のときにもバイアス効果を無視することができ、バイアスフリーなモデルとなるわけです。ただ、TD モデルにおいては、基本的に回帰分析手法は線形手法に限られてしまいます。
ではどの適応型ソフトセンサーがよいのか?というと、経験的にはプラントごとに良し悪しは変わります。それぞれ適応型ソフトセンサーごとに、モデルを構築するための手法 (PLSやSVRなど) はいろいろなあり、適応型ソフトセンサーごと、手法ごとに得意不得意はあります。このあたりは、プラントごとに試行錯誤が必要なところです (ただ、ある程度 試行錯誤を自動化することはできます)。
参考文献
- P. Kadlec, B. Gabrys, S. Strandt, Data-driven soft sensors in the process industry, Comput Chem Eng., 33, 795–814, 2009
- P. Kadlec, R. Grbic, B. Gabrys, Review of adaptation mechanisms for data-driven soft sensors, Comput. Chem. Eng., 1–24, 35, 2011.
- ソフトセンサー入門―基礎から実用的研究例まで, コロナ社, 2014
以上です。
質問やコメントなどありましたら、twitter, facebook, メールなどでご連絡いただけるとうれしいです。