一般的なデータ解析において、回帰モデルやクラス分類モデルをつくることを考えます。トレーニングデータとテストデータに分けて、トレーニングデータで回帰モデルやクラス分類モデルを構築して、そのモデルがどのくらいの推定性能をもつか、テストデータで検証します。

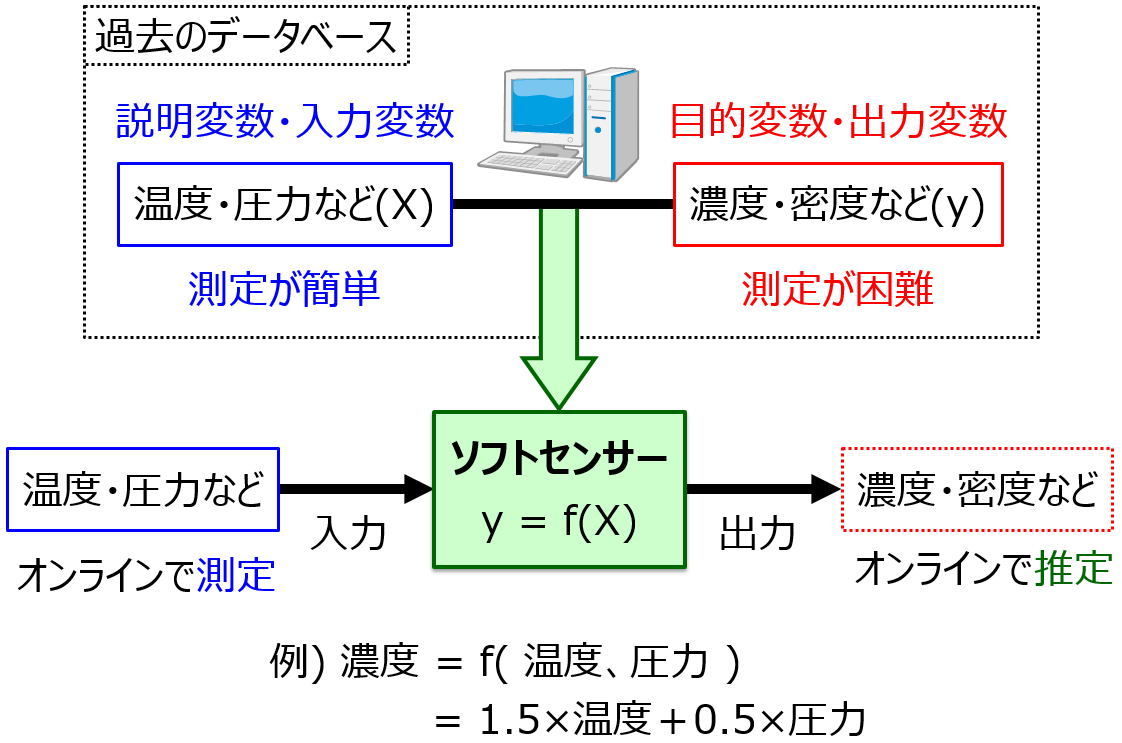
しかし、時系列データを解析するときには、モデルの構築や検証のやり方が少し異なります。たとえば、化学プラント・産業プラントにおいて、測定が困難なプロセス変数 (濃度・密度といった製品品質など) y の値を推定するソフトセンサーを開発するときには、データ解析のやり方に工夫が必要です。”時間の経過” を考えなければいません。今回は、時系列データを扱うときの注意点を説明します。ソフトセンサーについてはこちらをご覧ください。
注意点は全部で3つあり、以下のとおりです。
- トレーニングデータが更新される
- 目的変数 y の測定には時間がかかり、トレーニングデータ更新のときにその時間を考慮しなければならない
- 説明変数 X について、時間的に遅れて y と関係していることがある
順に説明します。
1. トレーニングデータが更新される
一般的なデータ解析において回帰モデルをつくるとき、トレーニングデータとテストデータとを分けて、トレーニグデータはモデルを構築するために、テストデータは構築されたモデルを検証するために使われます。テストデータがモデル構築に用いられることはありません。
しかし、時系列データ解析においては、テストデータがモデル構築に用いられることがあります。なぜなら、y は測定が困難なプロセス変数といっても、頻度は少ないかもしれませんが、測定されることがあるためです。新しい y の値が測定されたら、y の推定値と実測値がどれくらい合っているか検証するだけでなく、次の時刻において回帰モデル (ソフトセンサー) で y の値を推定するために、そのサンプルも使用して新たな回帰モデル (ソフトセンサー) を構築してよいわけです。
このように、最新のサンプルも活用してモデルを構築して y の値を推定するソフトセンサーを、適応型ソフトセンサーとよびます。化学プラント・産業プラントでは、原料の変化・触媒の劣化・外気温の変化・配管の汚れなどによって、X と y との関係が変化します。新しく測定されたサンプルを使って、X と y との関係の変化に “適応” するソフトセンサーということです。
2. 目的変数 y の測定には時間がかかり、トレーニングデータ更新のときにその時間を考慮しなければならない
上で、y が測定されたらそのサンプルをトレーニングデータに入れて、再び回帰モデル (ソフトセンサー) を構築してよい、という話をしました。次はサンプルをトレーニングデータに入れるタイミングです。
基本的に、y を測定するのには時間がかかります。数十分か数時間か、対象の y によって異なりますが、測定が終わり y の値が得られるまでは、トレーニングデータにサンプルを入れられません。
たとえば2年分のデータとして 2000 サンプルあるとしましょう。時系列データを扱うとき、基本的に古いデータを最初のトレーニングデータ、新しいデータをテストデータとします。実際にソフトセンサーを開発するときには、今までの測定データを使ってソフトセンサー (回帰モデル) を構築して、明日から y の値をソフトセンサーで推定しよう、となるためです。
最初の一年のデータである 1000 サンプルを最初のトレーニングデータ、次の一年のデータである 1000 サンプルをテストデータにする、といった具合です。1000サンプルのトレーニングデータで回帰モデルを構築し、テストデータの1サンプル目を推定したとします。このあとすぐに、そのサンプルをトレーニングデータに入れることはできません。たとえば、y の測定時間として 3 サンプル分の時間かかるとすると、テストデータの4サンプル目を推定する前に、トレーニングデータが 1001 サンプルになります。このとき、新たに回帰モデルを構築し直してもよいわけです。
上の例において厳密に言うと、テストデータの1サンプル目を推定するときには、998 サンプルしか得られていませんが、今回の説明では無視しています。1. 2. の注意点はどちらも、実際にソフトセンサーを現場で使用することと同じ状況で、データ解析するためのものです。ソフトセンサー開発のためのデータ解析をするときには、実際の状況を想定して解析するようにしましょう。
3. 説明変数 X について、時間的に遅れて y と関係していることがある
3つ目は、ソフトセンサー (回帰モデル) の推定性能を上げるための注意点です。
ソフトセンサーで推定する対象として、製品の品質に関わるものが多いです。測定が困難なプロセス変数の値を、ソフトセンサーで推定しよう、というわけです。製品ですので、プラントの出口で y の値が測定されます。一方で、Xとして、プラントの入口付近で測定されている温度や圧力などのプロセス変数もあります。大きなプラントになればなるほど、入口から出口までモノが移動するのに時間がかかります。途中に反応器があり、そこでも時間をかけているとしたら、その分、出口までに時間がかかります。つまり、ある時刻における X の値と y の値とが関係しているのではなく、ある時刻における y の値と関係しているのは、時間的に過去の X の値ということです。そのため、X としてある時間を遅らせたプロセス変数を用いることが一般的です。たとえば X としてのプロセス変数が 10 変数あるとき、それらのプロセス変数全てにおいて、y に対して時間を遅らせないものと、5 分ずつ 60 分まで遅らせたもの (時間遅れ変数) を用いるとします。そのとき、時間遅れは 0, 5, 10, …, 55, 60 分の 13 種類ですので、すべての X の変数の数は 10 × 13 = 130 になるわけです。y と 130 の X との間で、回帰モデルを構築します。
時間遅れ変数を用いるもう一つのメリットとして、やり方を工夫すれば将来の y の値を予測できる、ということが挙げられます。たとえば、X として y に対して 5 分遅れのプロセス変数のみ用いてソフトセンサーを構築したとすると、ある時刻における X の値をソフトセンサーに入力したら、5分後の y の値が出力されます。5分先の y の値を予測しているわけです。
時系列データ解析の例
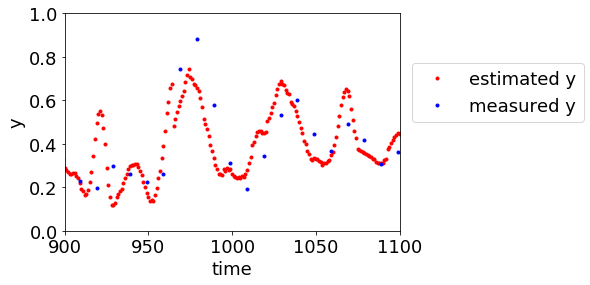
今回は、こちらの本 (L. Fortuna, S. Graziani, A. Rizzo, M. G. Xibilia, Soft sensors for monitoring and control of industrial processes. London: Springer-Verlag; 2007) に説明のあるデブタナイザーのデータセットを用いた時系列データを解析したPythonプログラムを示します。こちらのGitHubの demo_time_series_data_analysis_lwpls.py をご利用ください。モデリング手法は、Just-In-Time (JIT) モデリング手法の一つである Locally-Weighted Partial Least Squares (LWPLS) です。
解析例では、y の測定時間を 5、X の時間遅れ変数として 2 ずつ 10 まで遅らせたものを用いています。最初の 1000 個のサンプルをトレーニングデータとして、その後のサンプルを予測しています。なお、今回はオリジナルのデータセット debutanizer.csv と、y が10サンプルに一回しか測定されていないと仮定したデータセット debutanizer_y_measurement_span_10.csv を用意しました。測定されていないサンプルの y の値には 999 が入っており、これらのサンプルはモデルの構築や検証には用いられないようになっています。このデータセットを用いることで、yが測定されていないサンプルでも、X のみから y の値を推定できる様子を確認できます。
ご参考になれば幸いです。
以上です。
質問やコメントなどありましたら、twitter, facebook, メールなどでご連絡いただけるとうれしいです。

