材料の結晶構造を考慮して熱電変換材料を設計しました![金子研論文] 金子研の論文が Analytical Science Advances に掲載されましたので、ご紹介します。タイトルはDesign of thermoelectric materials with high electrical condu... 2020.12.06 ケモインフォマティクスケモメトリックスデータ解析研究室論文
「エンジニアのための実践データ解析」 データ解析をすぐに実践したい方が読む本 藤井宏行, 「エンジニアのための実践データ解析」, 東京化学同人, 2005東京化学同人: Amazon: もともとは化学工学会の学会誌に連載されていた “ケミカルエンジニアのための統計的品質管理入門” の内容を加筆修正された本です。学生の... 2020.11.29 ケモインフォマティクスケモメトリックスデータ解析プロセス制御・プロセス管理・ソフトセンサー研究室
ベイズ最適化で複数の目的変数がある場合の対応[Probability of Improvement(PI)以外] 適応的実験計画法により、高機能性材料を達成するための実験条件・製造条件を探索したり、高性能プロセスを開発するためのプロセス条件を探索したりするとき、ベイズ最適化を用いることで効率的に外挿を探索しながら目標達成を目指すことができます。設計問題... 2020.11.29 ケモインフォマティクスケモメトリックスデータ解析プロセス制御・プロセス管理・ソフトセンサー研究室
「統計でウソをつく法―数式を使わない統計学入門」 データ解析において自分で自分にウソをつかないために ダレル・ハフ 著, 高木秀玄 訳, 「統計でウソをつく法―数式を使わない統計学入門」, 講談社, 1968講談社: Amazon: 統計学の基礎を学べるブルーバックスの本です。1968 年に発行され、長年の間読まれています。以下は、講談社の... 2020.11.22 データ解析研究室
回帰係数=寄与度とすることは危険、どうしても寄与度を求めたいときはPCRやPLSの1成分モデルで、ただ基本的には寄与度ではなく重要度で議論 タイトルで言いたいことはほとんど言っていますが、丁寧に説明します。たとえば最小二乗法による線形重回帰分析や部分的最小二乗回帰 (Partial Least Squares Regression, PLS) や Least Absolute ... 2020.11.22 ケモインフォマティクスケモメトリックスデータ解析プロセス制御・プロセス管理・ソフトセンサー
「実験計画と分散分析のはなし改訂版-効率よい計画とデータ解析のコツ」 実験計画法の考え方や分散分析の基礎を学びたい方へ 大村平, 「実験計画と分散分析のはなし改訂版-効率よい計画とデータ解析のコツ」, 日科技連出版社, 2013日科技連出版社: Amazon: 実験計画法の考え方や分散分析の基礎を学べる本です。初版が 1984 年に発行され、2013 年に改... 2020.11.15 データ解析研究室
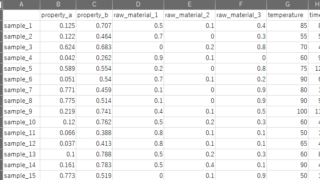
データセット作成のときに注意する6つのこと データ解析・機械学習を行うためには、データセットが必須です。エクセルファイルや実験ノートなどからデータを集めて、整理してまとめると思います。そのようにしてデータセットを作成するとき、注意することがあります。6つそれぞれ説明します。1. xl... 2020.11.15 ケモインフォマティクスケモメトリックスデータ解析プロセス制御・プロセス管理・ソフトセンサー研究室
「マンガでわかる統計学[因子分析編]」 主成分分析・因子分析の基礎を学びたい方へ 高橋信, 「マンガでわかる統計学」, オーム社, 2006オーム社: Amazon: 「マンガでわかる統計学」、「マンガでわかる統計学」に続く第三弾です。今回は主成分分析や因子分析についてです。ケモインフォマティクス・マテリアルズインフォマ... 2020.11.08 研究室
論文の緒言・手法・結果と考察・結言に何を書けばよいのか? 金子研ではこの季節になり、学生たちが研究要旨を作成したり、私が内容を添削したりしています。金子研のように分子設計・材料設計・プロセス設計・プロセス管理や制御関係の研究をしていると、研究成果には、基本的にそれらの設計・管理を行うための手法にな... 2020.11.08 研究室論文
「マンガでわかる統計学[回帰分析編]」 回帰分析の基礎を学びたい方へ 高橋信, 「マンガでわかる統計学」, オーム社, 2005オーム社: Amazon: 「マンガでわかる統計学」の続編です。今回は回帰分析についてです。最後に目的変数が 0, 1 の判別分析 (クラス分類) も取り上げられています。データの種... 2020.11.01 データ解析研究室