分子設計・材料設計・プロセス設計・プロセス管理において、分子記述子・実験条件・合成条件・製造条件・評価条件・プロセス条件・プロセス変数などの特徴量 x と分子・材料の物性・活性・特性や製品の品質などの目的変数 y との間で数理モデル y = f(x) を構築し、構築したモデルに x の値を入力して y の値を予測したり、y が目標値となる x の値を設計したりします。
モデルを逆解析して x の値を設計するとき、x のサンプルを大量に生成して、それらをモデルに入力して y の値を予測して予測値が目標値に近いサンプルもしくは目標範囲に入るサンプルを選択したり、ベイズ最適化では獲得関数の値が大きいサンプルを選択したりします。この予測結果において、y の予測値が目標範囲に入る場合ばかりではなく、特に目標範囲が遠いときには、予測値が目標範囲に届かない場合もあります。
もちろん、y の予測値が目標値に達しないというだけで、何か解析的な問題があるわけではありません。そもそも、y の予測値が目標値に達していたとしても、実測値が予測値とピッタリ同じに確実になるわけでもありませんし、予測値が目標値に達しない場合でも、ベイズ最適化によって y の予測値が目標値に届かない中でも目標に到達する確率が高いサンプルを選択して実験もしくはシミュレーションを行い、その結果に基づいて再度モデル構築およびモデルの逆解析を行い、といった検討を繰り返すことが重要になります。
一方で、モデル構築用のデータセットのサンプルに、y が目標範囲に入っているサンプルがあるにもかかわらず、逆解析で大量のサンプルを生成して y を予測させてみたら、y の予測値の中に目標範囲に入るサンプルがなかった、という場合もあります。このとき、2つのことを確認してみるとよいです。
1つ目は、最終的に構築されたモデルの振る舞いです。具体的には、最終的に構築されたモデルに、モデル構築のときに使用したサンプルを入力して、y の値を計算します。すなわち、フィッティングの結果を確認します。この、y の実測値 vs. 計算値プロットの、特に目標値に近い値付近を見たときに、例えば実測値よりも計算値のほうが小さい場合、そもそもモデルが y の大きい値を計算できない状態にあります。そのため、大量の x の値を入力しても y の値が大きくならないというのは、構築されたモデルの状態からすると、妥当な結果であり、解析の内容自体に問題はないことになります。もちろん特徴量 x の検討やモデリング手法の検討によって y が大きい値も予測できるモデルにするよう検討する選択肢もありますが、すでに検討済みであり、これ以上モデル改善の余地がないときには、このモデルを用いて、例えばベイズ最適化で獲得関数の値の大きいサンプルを選択することになります。
ここで注意点としては、上でフィッティングの結果を確認しているのは、単に逆解析で y の値が目標範囲に入らない、すなわち y の予測値が思ったより大きい (小さい) 値を取らないことを確認するのみであり、モデルの検証やモデルの選択とはまったく関係ありません。このフィッティングの結果を見て、モデル選択などをしないようお願いします。
もう一つ確認することは、生成した仮想サンプルの x の分布です。元々のデータセットの中で、x の間に相関関係があるにもかかわらず、その関係性を考慮せず仮想サンプルの生成をしたときに、大量のサンプルを生成しているとはいえ x の空間が広大な場合には効果的にサンプル生成ができていない可能性もあります。この心配があるときには、既存の x の分布を考慮して仮想サンプルを生成するとよいです。例えば、Gaussian Mixture Model (GMM) に基づく仮想サンプル生成の方法があります。
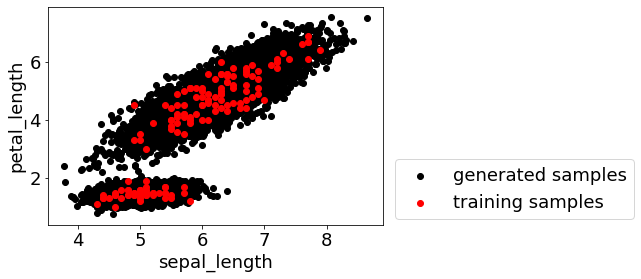
もちろん、このような仮想サンプル生成の方法では、モデルの適用範囲 (Applicability Domain, AD) 内に多くのサンプルを生成することになりますので、もし AD 外を探索したい、例えばベイズ最適化で獲得関数の値がより大きいサンプルを選択したいときには、x 間の相関関係のことは考えず乱数に基づいて生成する場合と、両方検討してみるとよいでしょう。
以上のように、逆解析の結果として y の予測値が期待した値にならないとき、モデルの性質上仕方がないこともあります。ただ、基本的にデータ解析・機械学習 (ベイズ最適化含む) は、実験と繰り返して用いることを前提のもと、検討するとよいと思います。ご参考になれば幸いです。
以上です。
質問やコメントなどありましたら、twitter, facebook, メールなどでご連絡いただけるとうれしいです。

