
[注意] こちらの書籍には改訂2版がございます。改訂2版でも無料公開の部分の内容は変わらない一方で、一章分+α を改訂2版では追記しておりますので、以下で興味を持っていただけましたら、改訂2版の購入をオススメいたします。

2019 年 10 月 23 日に、金子弘昌著の「化学のためのPythonによるデータ解析・機械学習入門」が発売になりました。
オーム社: https://www.ohmsha.co.jp/book/9784274224416/
(Amazon で在庫が切れていても、他では在庫があるようです。上のオーム社のウェブサイトにおける「購入はこちら」からお求めいただければと存じます)
Amazon: https://www.amazon.co.jp/dp/4274224414
データ解析・機械学習や Python の初学者向けの本であり、内容については金子研の学生にも確認してもらいながら精査し、いい感じに仕上がったと思います。
ここでは本書の 「はじめに」 の部分を無料公開します (出版社も承諾済み)。購入する際の参考になれば幸いです。それでは、よろしくお願いいたします。
はじめに
化学・化学工学でデータ解析・機械学習を活用するメリット
データ解析・機械学習を用いてこれまで蓄積されたデータを最大限に活用することで、材料開発を加速させたり、プロセス管理を効率化・安定化させたりできます。
化学・化学工学の分野において、様々な高機能性材料に関する研究・開発が行われています。電池・フィルム・樹脂・複合材・塗料・コーティング剤・包装材・接着剤・接合材・潤滑油・冷媒・触媒・超硬合金・形状記憶合金半導体・超電導体・セラミック材料・磁性材料・発光ダイオード・光ファイバー・セラミックス・医薬品・人工骨など、高機能性材料の例をあげるときりがありません。これらの高機能性材料には、熱・電気・磁気・光・溶解性・薬理活性などに関連した、材料ごとに求められる特性・物性・活性があります。よりよい性能の高機能性材料を実現できるように研究したり、特性・物性・活性に関係する複数の項目をすべて満たすような新規材料を開発したりしています。
高機能性材料としての化合物を研究・開発するとき、化合物が望ましい物性や活性を発現するためには、たとえば低分子の有機化合物であれば化学構造が、高分子であれば重合する原料だけでなく重合するときの条件 (重合温度・重合時間・添加剤など) が、無機化合物であれば元素の組成や合成条件が重要となります。これまでの知識・知見・法則や研究者・技術者の経験に基づいて、化学構造や原料・重合条件や元素組成・合成条件を変えて、新たな材料を合成することで、高性能な材料を目指します。しかし、知識・知見・法則が体系化されている分野ばかりではありません。ニッチな材料ほど知識・知見・法則や経験の蓄積は少ないといえます。勘に頼ることもあるかもしれません。さらに、研究者・技術者の経験が明文化されたり共有されたりしておらず、ある人の頭の中もしくはその人の実験ノートにしかないこともあります。もちろん、知識・知見・法則・経験がそろっていたとしても、思い通りの機能を発現する材料を合成することは難しく、高機能性材料の開発の現場においては、早く目的の材料をつくりたいと考えるでしょう。
そこでデータに着目します (図1)。研究者・技術者は、知識・知見・経験・勘に基づいて実験や製造の計画を立て、実際に実験・製造をします。これにより実験データ・製造データが得られます。実験や製造が、研究者・技術者の知識・知見・経験・勘に基づいていることから、データにはそれらが反映されています。目に見えないだけで、データには知識・知見・経験・勘がふんだんに含まれているわけです。データを最大限に活用することで、これらを目に見える形にしようとするのが、データ解析であり機械学習です。データ解析・機械学習により、データの中に潜む、法則・ルール・関係性を式の形に表します。研究者・技術者の暗黙知を形式知化する、ということもできます。
そもそも、物理法則・化学法則として用いられているものの中には、データに基づいた経験的な法則もあります。データ解析・機械学習でも同様にして、データから何らかの法則性を獲得できます。
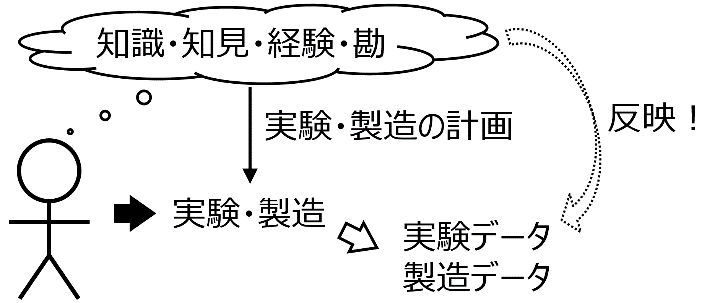
図1. 実験データ・製造データは研究者・技術者の知識・知見・経験・勘の宝庫
特性・物性・活性を y、化合物の特徴量を x としたときに、データ解析・機械学習により x と y の関係を表すモデル y=f(x) が構築できたとします。このモデルを用いることで、たとえば低分子の有機化合物であれば化学構造 x から、高分子であれば原料・重合条件 x から、無機化合物であれば元素組成・合成条件 x から、y の値を推定できます。化合物を合成したり合成後に特性・物性・活性の値を測定したりする前に、x からそれらの値を推定可能です。モデルを用いるというのは、仮想的な実験室で実験するようなものです。この実験室では実験に費用や時間はほとんどかかりません。実際に合成しようと思っても費用や時間の観点から現実的ではない何千・何万という数の候補でも特性・物性・活性の値を推定できるため、特性・物性・活性が良好な高機能性材料を効率的に設計可能になります。
高機能性材料を開発するときには、材料そのものだけでなく製造条件を改善することで、材料特性等の製品品質を向上できます。製造条件 x とその製造の結果としての製品品質 y のデータを用いて、モデル y=f(x) を構築します。このモデルを利用することで、望ましい品質を達成するための製造条件を探索可能です。
高機能性材料を製造するときには、化学プラントを適切に制御して管理することが、高い品質の製品を製造し続けるのに必要不可欠です。プラントにおけるプロセス制御およびプロセス管理を困難にしている要因の一つに、製品品質を代表する濃度・密度等のプロセス変数の測定に時間がかかったり頻繁には測定されなかったりすることが挙げられます。熟練した技術者であれば、自身の知識・知見・法則・経験により、そのような場合でも適切にプロセスを管理できるかもしれません。しかし誰でもできるわけではありません。熟練した技術者の暗黙知を、データ解析・機械学習により形式知化できます。
製品品質を迅速に制御したり効率的にプロセスを管理したりするため、プラント運転時のセンサー等の測定データや製品品質の測定データを活用します。データを用いて、センサー等で容易に測定可能なプロセス変数 x と測定が困難なプロセス変数 y との間でモデル y=f(x) を構築します。プラント運転時にこのモデルを用いることで、センサー等による測定結果から製品品質の値をリアルタイムに推定できます。実測値のように推定値を用いることで、迅速かつ安定に製品品質を制御できるようになります。
以上のように、データが蓄積されている状況においてデータ解析・機械学習をすることで、分子設計・材料設計を加速させたり、プロセス管理を効率的かつ安定的に行ったりできます。
この本の使い方
データ解析・機械学習の理論を勉強・学習したい方は、第 2 部をご覧ください。データの前処理・データの可視化・クラスタリング・回帰分析・クラス分類・モデルの適用範囲に関する、各手法の説明があります。高校卒業程度の数学の知識があることを前提としていますが、数学的な用語にはその都度補足説明を入れたり、参考文献を紹介したりしています。
さらに、データ解析・機械学習に関して理解を深めるため、解説した手法を実際に実行するための、Python のサンプルプログラムもあります。サンプルプログラムを実行しながら内容を確認したい方は、Python の基礎を勉強するため、事前に第 1 部をお読みください。説明するすべての手法にサンプルプログラムが付いています。サンプルプログラムはすべて以下の Github のウェブサイトからダウンロードできます。
本書で使用するサンプルデータセットはすべて、sample_data フォルダ (ディレクトリ) にあります。使用するサンプルデータセットを、サンプルプログラムと同じフォルダ (ディレクトリ) に置いてください。
サンプルプログラムに関する本文中での説明は必要最小限にとどめています。ただしサンプルプログラムを実行するだけで結果が得られ、さらにデータセットを変えるだけで同様の解析ができます。Python のプログラムについて詳細に調べたり検討したい場合は、本書の該当箇所を読んだり、サンプルプログラムのコメントを確認したり、「関数の名前 + python」 でウェブ検索したりしてください。さらに解析を進めたい方は、「行いたい内容 + python」でウェブ検索するとよいでしょう。
第 3 部には、具体的な材料設計・分子設計・プロセス管理 (ソフトセンサー・異常検出・異常診断) の方法・手順の説明や、その方法・手順を実行できるサンプルプログラムがあります。本書の説明を読みながら、サンプルプログラムを実行して、実際に材料設計・分子設計・プロセス管理をしてみましょう。
たとえば材料設計では、仮想的な樹脂材料のデータセットを用いて目的の物性が 2 つあるときに、両方とも高い材料を製造できるような条件を探索します。超伝導体材料のデータセットを用いた例では、高温超電導体の材料となるような元素組成を探索します。本書の説明を読みながら、一緒にサンプルプログラムを実行していくと、同様の材料設計ができるようになります。
分子設計では、分子の化学構造を物性・活性などと一緒に扱ったり、化学構造を数値化したり、新たな化学構造をコンピュータ上で設計したりします。これらにもサンプルプログラムがあります。物性・活性として、沸点・融点・水溶解度・薬理活性・環境毒性を対象にして、物性・活性が未知の分子の物性値・活性値を推定したり、物性・活性が良好な値になるように新たな化学構造を生成したりします。サンプルプログラムを実行しながら、一緒に分子設計をしましょう。
プロセス管理では、時系列データを扱います。ソフトセンサーというプラントにおいて測定することが難しいプロセス変数を推定するモデルを検討したり、プラントの異常を検出したり、異常が検出された後に異常に関係するプロセス変数を探したりします。ソフトセンサーにおいては、プラントで新たに測定されるデータを用いてモデルの推定性能を試みる適応型ソフトセンサーも扱います。(適応型)ソフトセンサー・異常検出・異常診断それぞれにサンプルプログラムがあります。サンプルプログラムを実行しながら、一緒にプロセス管理の検討をしましょう。
本書で扱う材料設計・分子設計・プロセス管理には、すべてサンプルプログラム・サンプルデータセットがあります。材料設計・分子設計・プロセス管理の実習としても利用できます。そして、サンプルデータセットの同じ形式のデータセットをご自身で準備して、サンプルプログラムと同じフォルダ (ディレクトリ) に置けば、本書と同じ解析をそのまま実行できます。
一つ注意点として、基本的に本書で扱うデータセットの中身はすべて半角英数字で準備し、ひらがな・カタカナ・漢字などは使用しないことを前提としています。サンプルの名前や変数の名前などにひらがな・カタカナ・漢字を用いないよう注意してください。どうしてもひらがな・カタカナ・漢字を用いたい場合は、1.2 節におけるデータセットの読み込みに関する参考として対処法がありますのでご覧ください。
本書の原稿の確認やサンプルプログラムの検証について、明治大学データ化学工学研究室 (金子研究室) の菅野 泰弘さん・小島 巧さん・清水 直斗さん・江尾 知也さん・山田 信仁さん・岩間 稜さん・柴田 海那さん・鈴木 達也さん・新田 楓美香さん・谷脇 寛明さん・御園 裕美さん・山影 柊斗さん・山本 統久さん・吉浜 弘樹さん・後藤 慶さんにご助力をいただきました。ここに記し、感謝の意を表します。ありがとうございました。
化学、化学工学分野でデータ解析・機械学習の手法を活用することを目指す皆様にとって、本書が少しでもその一助となれば幸いです。
2019 年 9 月
金子弘昌
「はじめに」は以上です。ちなみに、詳細な目次は以下のとおりです。
目次
第1部 Pythonと統計の基礎知識
1章 Pythonの基礎
1.1 Python の使い方
1.2 データセットの読み込み・保存
2章 データの図示
2.1 ヒストグラム
2.2 箱ひげ図
2.3 散布図
2.4 相関行列
第2部 データ解析・機械学習の基礎
3章 多変量データとデータの可視化
3.1 多変量データ
3.2 データの前処理
3.3 主成分分析 (Principal Component Analysis, PCA)
3.4 階層的クラスタリング
3.5 非線形の可視化手法: t-distributed Stochastic Neighbor Embedding (t-SNE)
4章 化学データを用いたモデリング
4.1 回帰分析
4.1.1 最小二乗法による線形単回帰分析
4.1.2 最小二乗法による線形重回帰分析
4.1.3 回帰モデルの推定性能の評価
4.1.4 オーバーフィッティング(overfitting)・多重共線性(multicollinearity)
4.1.5 主成分回帰 (Principal Component Regression, PCR)
4.1.6 クロスバリデーション (Cross Validation, CV)・ハイパーパラメータ (hyperparameter)
4.1.7 部分的最小二乗法 (Partial Least Squares, PLS)
4.1.8 非線形の回帰分析
4.1.9 サポートベクター回帰 (Support Vector Regression, SVR)
4.2 クラス分類
4.2.1 k 近傍法 (k-Nearst Neighbor algorithm, k-NN)
4.2.2 サポートベクターマシン (Support Vector Machine, SVM)
4.2.3 決定木 (Decision Tree, DT)
4.2.4 ランダムフォレスト (Random Forest, RF)
5章 回帰モデル・クラス分類モデルの適用範囲
5.1 モデルの適用範囲とは?
5.2 データ密度
5.2.1 k 近傍法 (k-Nearest Neighbors algorithm, k-NN)
5.2.2 One-Class Support Vector Machine (OCSVM)
5.3 アンサンブル学習法
第3部 化学・化学工学データでの実践のしかた
6章 材料設計・分子設計・医薬品設計
6.1 材料設計
6.1.1 樹脂材料 (高分子材料)
6.1.2 超伝導体材料
6.1.3 ベイズ最適化 (Bayesian Optimization)
6.2 分子設計・医薬品設計
6.3 化学構造の表現方法
6.3.1 Simplified Molecular Input Line Entry System (SMILES)
6.3.2 MOL file
6.4 化合物群の扱い
6.5 化学構造の数値化
6.6 化学構造の生成
6.7 化合物のデータセットを扱うときの注意点
6.8 具体的なデータセットを用いた解析
6.8.1 沸点
6.8.2 環境毒性 (クラス分類)
6.8.3 薬理活性 (回帰分析)
6.8.4 薬理活性 (クラス分類)
6.8.5 融点
6.8.6. 水溶解度
7章 時系列データの解析
7.1 化学プラントにおける推定制御・ソフトセンサー
7.2 時系列データ解析の特徴
7.3 モデルの劣化と適応型ソフトセンサー
7.3.1 蒸留塔における適応型ソフトセンサーの検討
7.3.2 排煙脱硝装置における適応型ソフトセンサーの検討
7.4 データ解析・機械学習による化学プラントのプロセス管理(異常検出・異常診断)
7.4.1 異常検出モデルの構築および検証
7.4.2 異常に関係するプロセス変数の診断
サンプルプログラムのダウンロードの仕方
以下のURLのサイトにおける、右の方にある「Code」の四角をクリックして、そこで開かれたところの右下の「Download ZIP」をクリックすると、zipファイルがダウンロードされます。
難しい場合は、以下のURLをクリックするのでもダウロードできます。

ダウンロードが完了したら、zipファイルを解凍(展開)すると、そのフォルダに sample_program_1_1.py をはじめとしてすべてのサンプルプログラムがあります。
以上です。
質問やコメントなどありましたら、twitter, facebook, メールなどでご連絡いただけるとうれしいです。

