Datachemical LAB をご利用いただいている方が引き続き増えており、嬉しい限りでございます。これまでご紹介させていただいた通り、Datachemical LAB を使用することで、データの前処理・データの可視化・回帰分析・モデルの逆解析・モデルの適用範囲・化学構造生成・(適応的)実験計画法・能動学習・ベイズ最適化・ソフトセンサー・異常検出などの、データ解析・機械学習が可能になります。
そして、ついに直接的逆解析が加わりました!プレスリリースはこちらです。
化学の研究開発AIクラウドサービス「Datachemical LAB」にて目標性能に対する材料作製条件予測のエキスパート機能をリリース https://t.co/756DE8ck5I @PRTIMES_JPより
— 金子弘昌@「化学・化学工学のための実践データサイエンス―Pythonによるデータ解析・機械学習―」 (@hirokaneko226) December 27, 2022
Datachemical LAB のメニューにおける MI Expert に、MI予測-直接的逆解析があります。
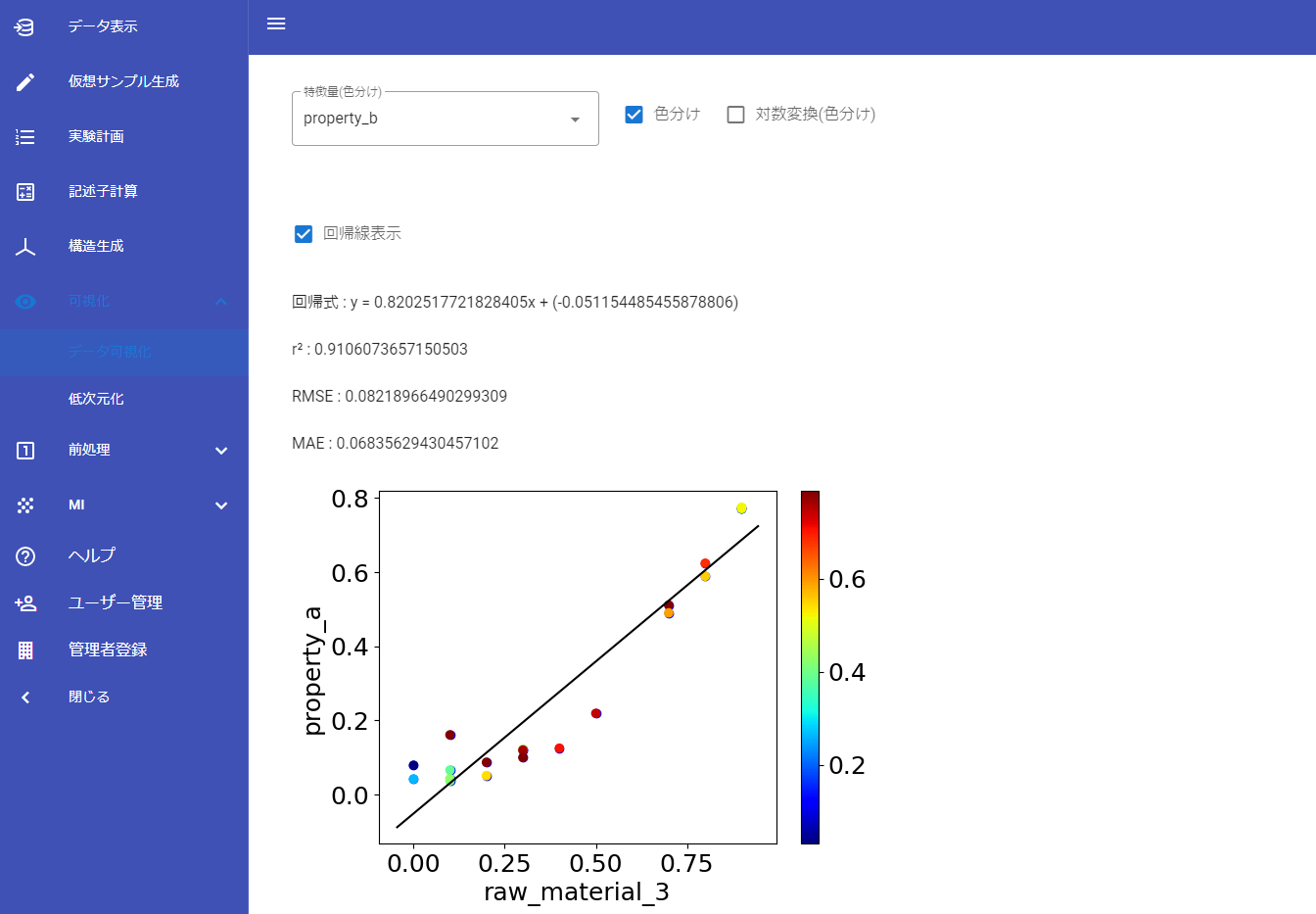
分子設計・材料設計・プロセス設計・プロセス管理において、分子記述子・実験条件・合成条件・評価条件・プロセス条件・プロセス変数などの特徴量 x と材料の物性・活性・特性や製品品質 y との間で数理モデル y = f(x) を構築します。Datachemical LAB を用いることで、いろいろな種類のモデル構築手法がある中で、対象のデータセットに合う最適な手法を自動的に選択したり、選択された手法で実際にモデルを構築したりすることができます。
モデルを構築したら、x の値から y の値を予測したり y の目標値を達成するための x の値を設計したりします。分子設計・材料設計・プロセス設計に必要なことは y の目標値からそれを実現するための x を導くことです。これをモデルの逆解析と呼びます。ただ、一般的なモデルの逆解析で行われていることは、x の仮想サンプルをコンピュータで大量に生成し、それらをモデルに入力して y の値を予測し、予測値が良好な仮想サンプルを選択する、すなわち順解析を網羅的に繰り返す擬似的な逆解析にすぎません。これでは人が事前に想定した x の探索範囲における y を予測することにすぎず、当初想定しない条件でこそ発現する新機能の探索には全く対応できません。
金子研究室では、y の値から x の値を直接的に予測する、すなわち数理モデルを直接的に逆解析する手法「直接的逆解析法」を開発しています。
ベイズ最適化を凌ぐ実験条件探索の効率化や
バッチプロセスにおける初期運転条件およびバッチ中の時系列データ(バッチプロファイル)の設計に成功しました。

Datachemical LAB を用いることで、直接的逆解析法により y の目標値から直接 x の値を自由自在に予測できます。さらに y が複数存在する場合でも全ての y の目標値を満たす x の値を提案できます。
Datachemical LAB では、y それぞれの目標値を設定します。複数の目標値を設定することも可能です。

そして Datachemical LAB を実行すると、それぞれの目標値に対応する x の値を計算します。

直接的逆解析の手法として、
- Gaussian Mixture Regression (GMR)
- Variational Bayesian Gaussian Mixture Regression (VBGMR)
が搭載されています。
モデル最適化-複数Y同時セクションで最適化しましょう。
Datachemical LAB では、GMR, VBGMR に限らず、複数の y を同時に考慮してモデル最適化ができます。これにより、例えばランダムフォレスト (Random Forests, RF) を用いることで、複数の y を考慮した変数重要度を計算できます。
それぞれ金子研究室でも実績がある方法であり、安心してご利用ください。ぜひ直接的逆解析を含めたDatachemical LAB のご検討のほどよろしくお願いいたします。
興味がありましたら、以下のウェブサイトからお問い合わせいただけますと幸いです。

以上です。
質問やコメントなどありましたら、twitter, facebook, メールなどでご連絡いただけるとうれしいです。

