いつも Datachemical LAB をご利用いただきありがとうございます。
これまでご紹介させていただいた通り、Datachemical LAB を使用することで、データの前処理・データの可視化・特徴量計算・回帰分析・モデルの逆解析・モデルの適用範囲・化学構造生成・(適応的)実験計画法・能動学習・ベイズ最適化・ソフトセンサー・異常検出・直接的逆解析・クラス分類などの、データ解析・機械学習が、プログラミングなしで可能になります。
そして、Datachemical LAB にスペクトルの変換の機能が加わりました!プレスリリースはこちらです。
実験・製造データ解析のAI・機械学習クラウドサービス「Datachemical LAB」にてスペクトルデータ処理機能をリリース https://t.co/vYtGkHaOR9 @PRTIMES_JPより
— 金子弘昌@改訂2版 化学のためのPythonによるデータ解析・機械学習入門 (@hirokaneko226) November 11, 2023
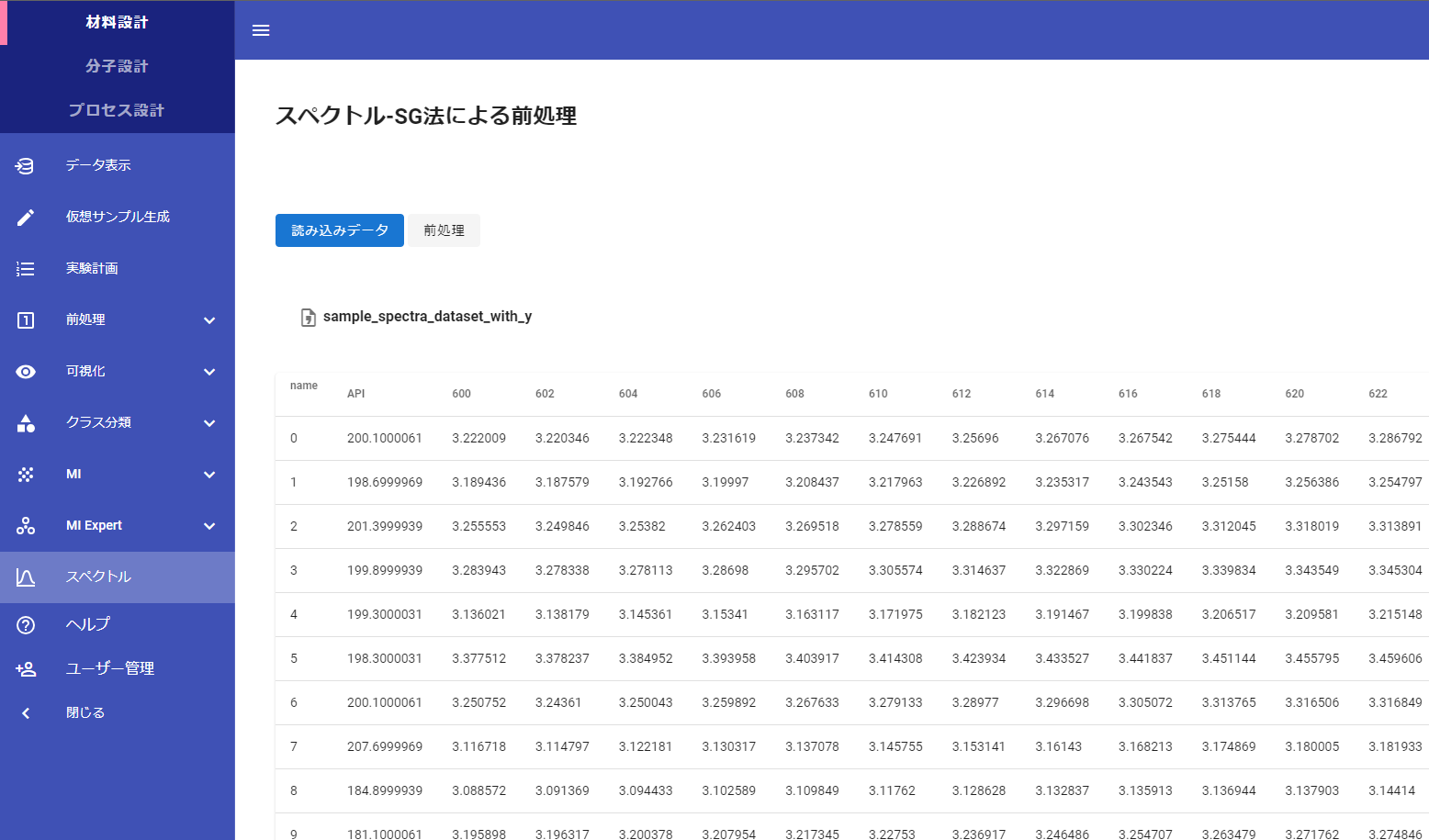
Datachemical LAB のメニューの材料設計に、「スペクトル」があります。
分子設計・材料設計・プロセス設計・プロセス管理において、分子記述子・実験条件・合成条件・製造条件・評価条件・プロセス条件・プロセス変数などの特徴量 x と分子・材料の物性・活性・特性や製品の品質などの目的変数 y との間で数理モデル y = f(x) を構築し、構築したモデルに x の値を入力して y の値を予測したり、y が目標値となる x の値を設計したりします。
x もしくは y として、分光分析・振動分光法等によるスペクトルを用いることがあります。例えば、fed-batch cell culture process を対象として、培養液における Fourier transform near infrared (FT-NIR) multiplex process analyzer spectroscopy のスペクトルを x、グルコース濃度と乳酸濃度を y とし、x と y の間で回帰モデル y=f(x) を構築することで、FT-NIRスペクトルからグルコース濃度と乳酸濃度を推定できます。

また、バイオマテリアルを対象として、合成条件を x、FI-IR スペクトルをはじめとする材料特性を y としてモデル y = f(x) を構築したり、FI-IR スペクトルをはじめとする材料特性と動物実験条件を x、動物実験の結果である骨形成率を y として別のモデル y = g(x) を構築したりもします。

スペクトルにはノイズが含まれていたり、サンプルごとにスペクトルのベースラインが異なったりするため、スペクトルを適切に前処理することで、モデルの予測精度が大きく向上することがあります。今回、Datachemical LAB に、Savitzky-Golay (SG) 法によるスペクトルの変換機能を追加しました。SG 法により、ノイズの低減とベースライン補正を同時に実施できます。SG 法の詳細についてはこちらをご覧ください。

なお、スペクトルごとの標準化 (Standard. Normal Variate, SNV) についても選択できます。
Datachemical LAB でスペクトルを SG 法により変換した後は、他の解析にスムースに移ることができます。例えば、スペクトルを x として使うとき、多くの場合において特徴量の数が多くなるため、SG 法による変換の後に、Boruta で特徴量を選択することもあります。

Datachemical LAB によりスムースに SG法 → Boruta を実現できます。これにより、適切に変換された少数の特徴量のみでモデル構築を検討できます。サンプルが少ないときでも良好な結果が得られやすくなります。
スペクトル解析を含めて、ぜひDatachemical LABを活用していただければと思います。
以上です。
質問やコメントなどありましたら、X, facebook, メールなどでご連絡いただけるとうれしいです。

