
Boruta という、ランダムフォレスト (Random Forest, RF) の変数重要度に基づいた変数選択手法について、パワーポイントの資料とその pdf ファイルを作成しました。いろいろなデータセットを解析しましたが、モデルの推定性能を落とさないように説明変数を選択できています。
pdfファイルはこちらから、パワーポイント(pptx)ファイルはこちらからダウンロードできます。
興味のある方はぜひ参考にしていただき、どこかで使いたい方は遠慮なくご利用ください。
Boruta とは?
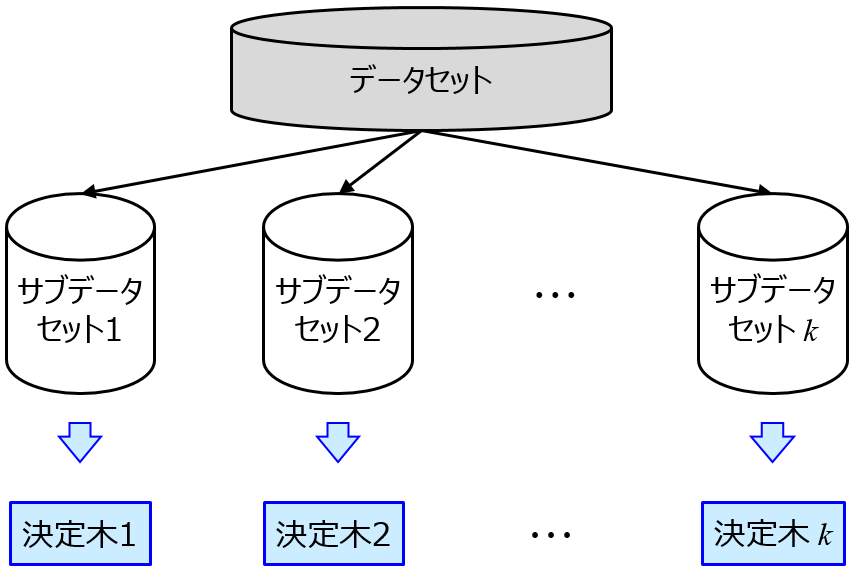
- ランダムフォレスト (Random Forest, RF) の変数重要度に基づく変数選択手法
- あえて目的変数と関係のない説明変数を追加して RF を行い、その変数重要度と、オリジナルの説明変数における変数重要度とを比較することで、選択する説明変数を検討
スライドのタイトル
- Boruta とは?
- Boruta に着目した理由
- Boruta のアルゴリズム 1/3
- Boruta のアルゴリズム 2/3
- Boruta のアルゴリズム 3/3
- Python で Boruta を実行するには?
- Boruta のパラメータ
- 解析してみました 比較手法
- 解析してみました 記述子
- 解析してみました 沸点のデータセット
- 解析してみました 沸点のデータセット 推定結果
- 解析してみました 環境毒性のデータセット
- 解析してみました 環境毒性のデータセット 推定結果
- 解析してみました 薬理活性のデータセット
- 解析してみました 薬理活性のデータセット 推定結果
- 解析してみました 融点のデータセット
- 解析してみました 融点のデータセット 推定結果
- 解析してみました 水溶解度のデータセット
- 解析してみました 水溶解度のデータセット 推定結果
- 参考文献
参考文献
Kursa, M. B., & Rudnicki, W. R. (2010). Feature Selection with the Boruta Package. Journal of Statistical Software, 36(11), 1–13. https://doi.org/10.18637/jss.v036.i11

Page Not Found
Page not found. Your pixels are in another canvas.
danielhomola.com
以上です。
質問やコメントなどありましたら、twitter, facebook, メールなどでご連絡いただけるとうれしいです。

