データ解析・機械学習のためのツールキット DCEKit にバギングによるアンサンブル学習の機能を追加しました。

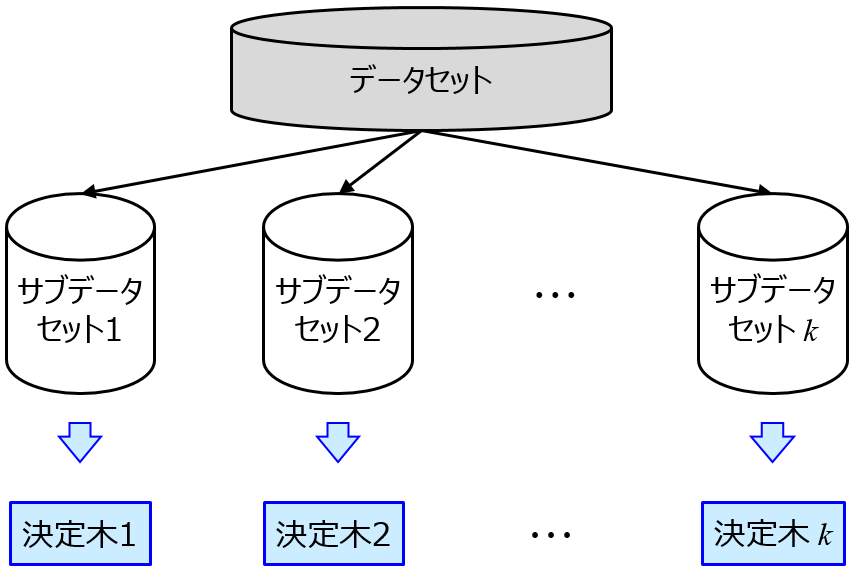
アンサンブル学習というのは、回帰モデルだったりクラス分類モデルだったり、モデルをたくさん作って推定性能を上げよう!、といった手法です。バギングというのは、アンサンブル学習の一つであり、元のデータセットにおけるサンプルをランダムに選んだり、説明変数をランダムに選んだり、その両方行ったりして、サブのデータセットをたくさん作り、サブデータセットごとにモデル (サブモデル) を構築することで、モデルをたくさん作ります。新しいサンプルにおける推定値は、回帰分析のときはすべてのサブモデルの推定値の平均値、クラス分類のときはサブモデルの推定結果の多数決とします。
ランダムフォレストを一般化した感じで、決定木にかぎらず、 (PLS とか SVM とか) 任意の手法でサブモデルを構築できます。
バギングのメリットの一つとして、推定値の信頼性を議論できます。回帰分析のとき、すべてのサブモデルの推定値の標準偏差を確認することで、推定値がどれくらいばらつくかを見積もれます。クラス分類のときは、あるクラスと推定したサブモデルの割合を信頼性の指標とします。
scikit-learn にもバギングの機能はありまして、BaggingRegressor や BaggingClassifier が準備されています。基本的にはこれらで問題ないのですが、少しかゆいところに手が届かない印象がありました (2019 年 9 月 2 日現在)。たとえば、BaggingRegressor でサブモデルの推定値の標準偏差を計算できないとかです。
なので、DCEKit に DCEBaggingRegressor や DCEBaggingClassifier を追加しました。scikit-learn の BaggingRegressor や BaggingClassifier と比べた特徴は以下のとおりです。
- 回帰分析において、predict でサブモデルの推定値の標準偏差も同時に出力できる
- サブモデルごとにクロスバリデーションでハイパーパラメータを最適化できる (手法によっては時間がかかります)
- サブデータセットごとに変数の標準化 (オートスケーリング) ができる
それぞれ使い方は、BaggingRegressor や BaggingClassifier に寄せています。なお、DCEBaggingRegressor や DCEBaggingClassifier も scikit-learn に準拠していますので、scikit-learn の cross_val_predict や GridSearchCV を使えます。
こちらに詳しい使い方の説明を追記しましたので、

もし興味があればお試しいただければと思います。
以上です。
質問やコメントなどありましたら、twitter, facebook, メールなどでご連絡いただけるとうれしいです。