分子設計・材料設計・プロセス設計・プロセス管理において、分子記述子・合成条件・製造条件・評価条件・プロセス条件・プロセス変数などの特徴量 x と材料や製品の物性・活性・特性などの目的変数 y との間で、データセットを用いて数理モデル y = f(x) を構築し、モデルを用いて x の値から y の値を推定したり、y が目標値を持つ x を設計したりします。モデルを構築する目的としては、x から y を予測したり y が目標値となる x を設計したりすることの他に、x と y の間を関係性を理解することで、実験系やプロセスにおける現象を把握したり、物性や活性を発現するメカニズムを解明したりすることもあります。そのため構築されたモデルを解釈することが試みられています。XAI (eXplainable AI), LIME, SHAP, x の重要度, 決定木などです。

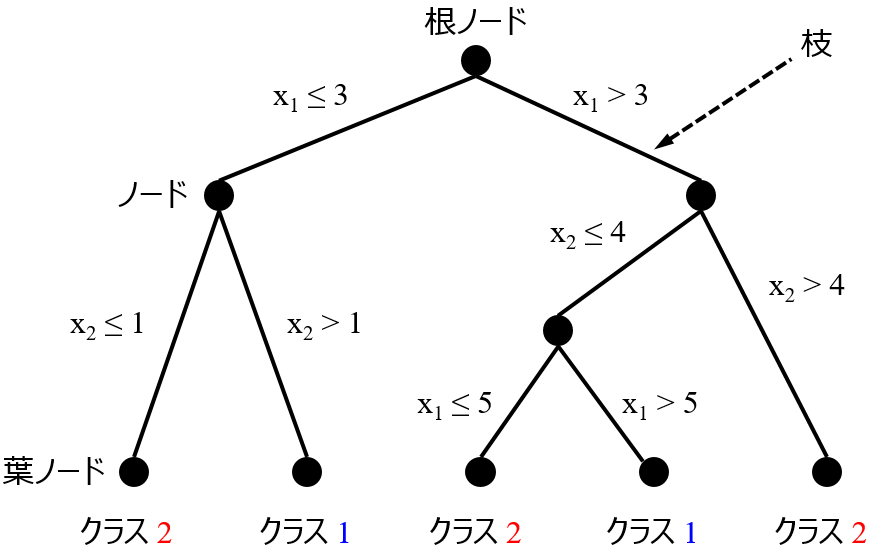
ここで注意することは、「解釈」というのは、データセットの解釈ではなく、あくまでモデルの解釈、ということです。例えば、決定木で x と y の間の関係を解釈するということは、構築された決定木モデルを解釈することになります。解釈した内容が本当かどうかは、モデルの予測精度にも、決定木のアルゴリズムにもよります。
解釈に用いられる他のすべての方法においても、あくまで構築されたモデルを解釈することになりますので、そもそも良好なモデルが構築できていなかったら、解釈できないことになります。もちろん解釈した結果自体を得ることはできますが、それはただの当てずっぽうです。例えば回帰分析において、テストデータやダブルクロスバリデーションの r2 が 0 のモデルを解釈しても何も得るものはありません。
起きている現象を理解したい、物性や活性を発現するメカニズムを解明したい、といったときに、必要条件となるのは解釈に足るくらい予測精度の高いモデルを構築することです。良好なモデルが構築されて初めて、そのモデルを解釈しようとなります。
解釈した結果は、構築されたモデルに依存します。線形のモデルでは線形の解釈しかできませんし、非線形のモデルでも、構築されたモデルの非線形性しか解釈できません。線形モデル・非線形モデルのどちらでも、モデルがオーバーフィッティングしていたらオーバーフィッティングしたモデルが解釈されることになります。XAI, LIME, SHAP, x の重要度、決定木などの解釈するための情報が得られたら、それをすべて正として解釈しようとする人もいるかと思いますが、上記の点について考慮して解釈の結果を活用するとよいと思います
以上です。
質問やコメントなどありましたら、twitter, facebook, メールなどでご連絡いただけるとうれしいです。

