
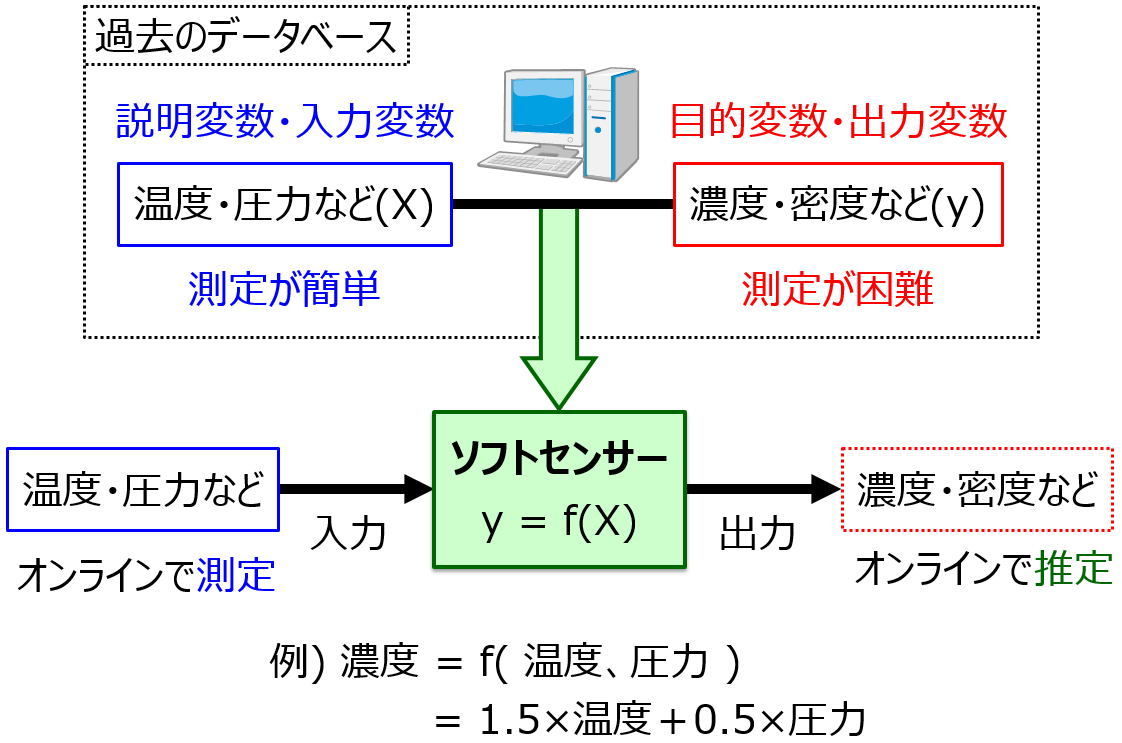
分子設計・材料設計・プロセス設計・プロセス管理において、分子記述子・実験条件・合成条件・製造条件・評価条件・プロセス条件・プロセス変数などの特徴量 x と分子・材料の物性・活性・特性や製品の品質などの目的変数 y との間で数理モデル y = f(x) を構築し、構築したモデルに x の値を入力して y の値を予測したり、y が目標値となる x の値を設計したりします。
プロセス管理において、プロセス状態の正常・異常を判断するため、正常状態から異常状態への推移を事前に予測するため、異常検出 (異常検知) モデルが用いられます。

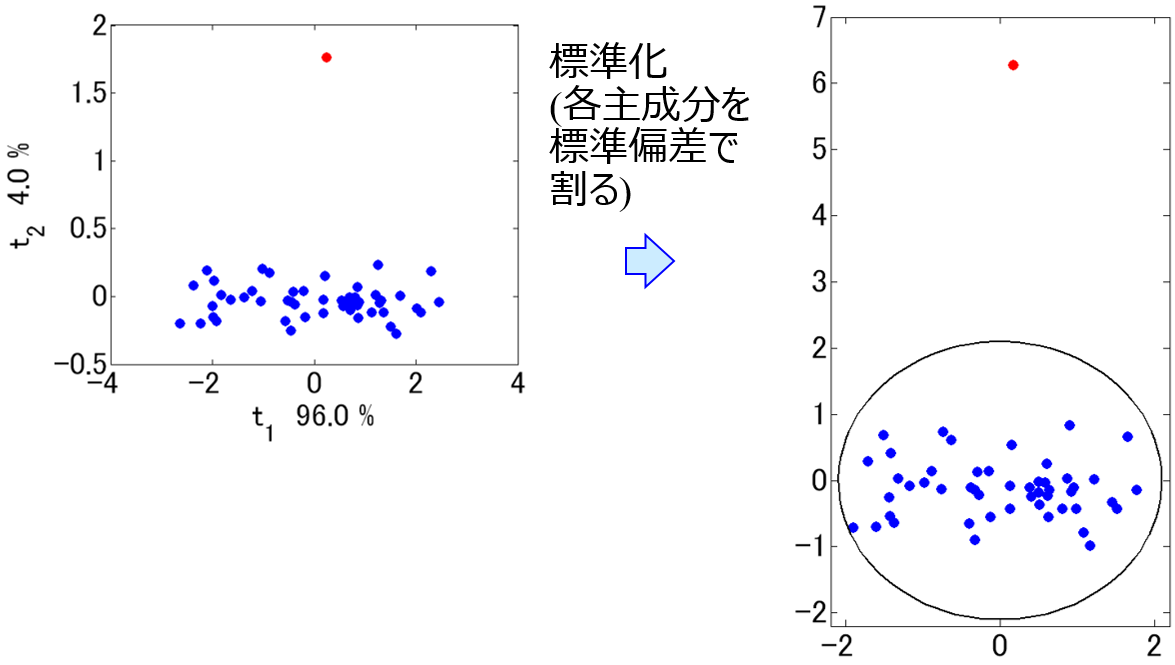
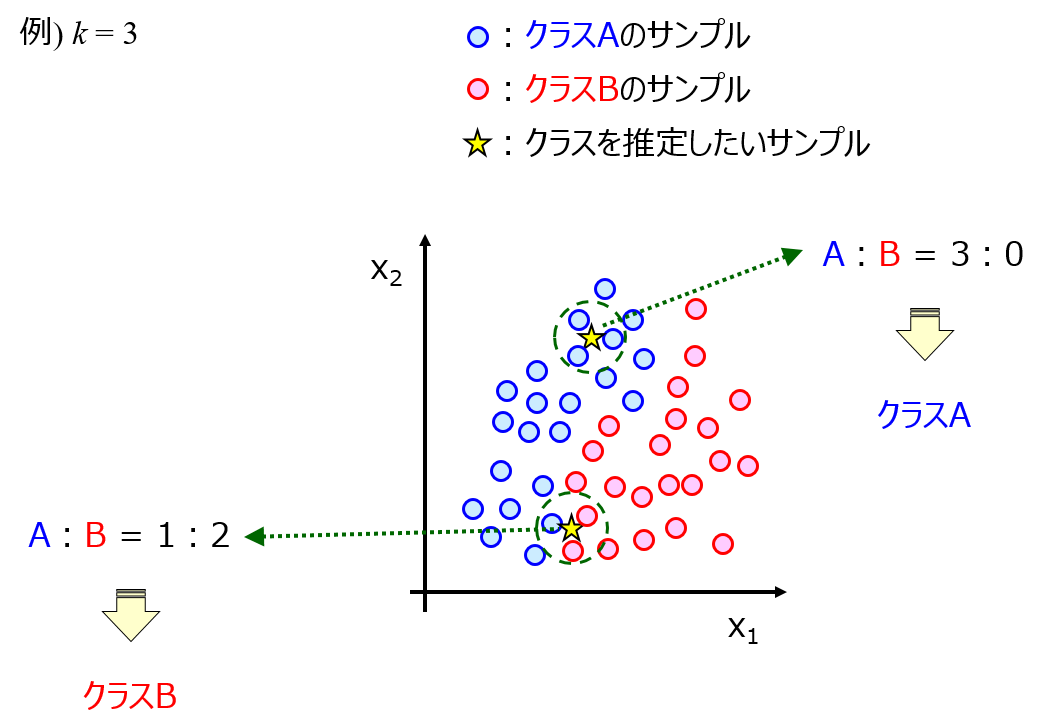
異常検知モデルの構築には、基本的に教師なし学習が用いられます。具体的には、正常状態において測定されたデータを用いて、正常状態データのみが存在する領域を定義するモデルを構築します。例えば、主成分分析 (Principal Component Analysis, PCA) に基づく T2統計量・Q統計量や、k最近傍法 (k-Nearest Neighbor, k-NN) や、Local Outlier Factor (LOF) や、One-Class Support Vector Machine (OCSVM) といった手法が用いられます。
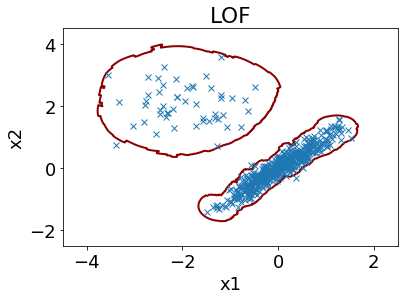
正常なデータ領域を、新たに測定されたサンプルが超えたときに異常と診断されます。これによりリアルタイムに異常を検出でき、異常に対して早期に対処できます。基本的にはモデルの適用範囲 (Applicability Domain, AD) と同じ考え方です。
異常検知の機能は Datachemical LAB に搭載されており、異常検知モデルを構築できるだけでなく、 実際のプロセスでリアルタイムにモニタリングすることもできます。

どんなモデルでも、モデルを構築したら、そのモデルの性能を評価する必要があります。異常検知モデルも例外ではありません。
ただ、異常検知モデルの構築に用いられているのが教師なし学習であるため、適切なクラスター数やクラスタリング手法、可視化手法の決定が難しいこと同様に、モデルの評価は一筋縄にはいきません。異常検知モデルの評価にも工夫が必要です。
異常検知モデルの評価には、基本的に異常状態において測定されたデータが必要です (異常状態のデータはないときの対応については少し下で説明します)。なぜなら、正常状態のデータしかなければ、もちろん正常状態のデータをどの程度正しく「正常」と予測できるかモデルを評価できますが、例えば全てのデータを「正常」と予測してしまい、異常状態のデータでさえも「正常」と予測されてしまうモデルである恐れがあるためです。
異常状態のデータを、適切に「正常でない」(異常) と予測できるモデルかどうかを評価する必要があります。
異常状態のデータがあれば、クラス分類の評価と同様にして正常状態のデータと異常状態のデータをどの程度分類できたかを評価します。

では、異常状態において測定されたデータがないときはどうすればよいでしょうか?
1つは、正常状態のデータの中でも、異常状態に推移しつつあると考えられるデータを、異常状態のデータとして用います。運転日誌から、これまでのプロセス状態と異なるような状態であった時間帯や、プロセスデータを概観して、いつもの正常状態と異なる挙動を示す時間帯などを異常状態のデータとみなして、それらを異常検知モデルがどのように予測するかを検証します。もちろん、あくまで正常状態のデータであるため、異常検知モデルが正常と判断することが悪いわけではありません。ただ、異常検知モデルの出力値 (T2統計量、Q統計量、データ密度などの値) が他の正常状態のデータと同様のばらつきを示すよりは、例えば徐々に出力値が上昇する傾向にあるなど、他の正常状態のデータとは異なるような挙動を再現できているかは 1 つの評価として参考になります。
もう1つは、仮想的な異常状態のデータを作成することです。プロセスが異常状態となるシナリオを想定し、そのシナリオのときにプロセス変数の値はどのような値を取るのか、仮想的にデータを作成します。例えば、正常状態のデータをベースにして、対象のプロセス変数の値を意図的に変更する方法がよいかと思います。
異常状態のデータが少なかったり、そもそもなかったりする状況で異常検出モデルを構築しなければならず、また教師なし学習のモデルの評価が難しい状況において、異常検知モデルの評価をするには、一工夫する必要があります。ぜひ上の方法を参考にしていただき、プロセス管理で用いる異常検知モデルを検討していただければと思います。
以上です。
質問やコメントなどありましたら、X, facebook, メールなどでご連絡いただけるとうれしいです。

