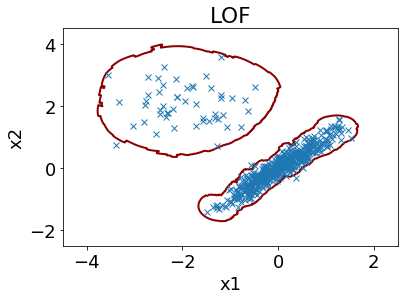
Local Outlier Factor (LOF) について、パワーポイントの資料とその pdf ファイルを作成しました。LOF は k-nearest neighbor algorithm (k-NN) の発展版のようなもので、データ密度を推定したり、そのデータ密度により外れサンプル (外れ値) を検出したり、装置やプラントなどの異常を検出したりできます。似た手法である kNN, One-Class Support Vector Machine (OCSVM) との比較も資料に載せました。
pdfファイルはこちらから、パワーポイント(pptx)ファイルはこちらからダウンロードできます。
興味のある方はぜひ参考にしていただき、どこかで使いたい方は遠慮なくご利用ください。
また、scikit-learn を用いた LOF のデモンストレーションのプログラムも準備しました。こちらの Github https://github.com/hkaneko1985/dcekit にある demo_lof.py です。ぜひご利用ください。
Local Outlier Factor (LOF) とは?
- データ密度を推定する手法
- k 最近傍法 (k-Nearest Neighbor, k-NN) による密度推定と比べて、データ分布における局所的なデータ密度の違いを考慮可能
- LOF の結果から外れサンプル検出や (装置やプロセスなどの) 異常検出が可能
スライドのタイトル
- Local Outlier Factor (LOF) とは?
- 復習) k-NN によるデータ密度の指標
- k-NN で何が問題か?
- LOF ではどうするか?
- あるサンプルの LOF をどう計算するか?
- あるサンプルの LOF をどう計算するか? 1/4
- あるサンプルの LOF をどう計算するか? 2/4
- あるサンプルの LOF をどう計算するか? 3/4
- あるサンプルの LOF をどう計算するか? 4/4
- 実行例
- Python コード例
- scikit-learn を使うときの注意点
- k-NN, OCSVM との比較・注意点
- 参考文献
参考文献
- M. Breunig, H. P. Kriegel, R. T. Ng, J. Sander, LOF: identifying density-based
local outliers, Proceedings of the 2000 ACM SIGMOD international conference on
Management of data, 93-104, 2000. DOI: 10.1145/342009.335388
https://dl.acm.org/citation.cfm?id=335388 - https://en.wikipedia.org/wiki/Local_outlier_factor
- Lee, B. Kang, S. H. Kang, Integrating independent component analysis and local
outlier factor for plant-wide process monitoring, Journal of Process Control,
21, 1011-1021, 2011. DOI: 10.1016/j.jprocont.2011.06.004
ScienceDirectwww.sciencedirect.com - https://scikit-learn.org/stable/modules/generated/sklearn.neighbors.LocalOutlierFactor.html

以上です。
質問やコメントなどありましたら、twitter, facebook, メールなどでご連絡いただけるとうれしいです。