昨年度の金子研の四年生が主に研究していたテーマの成果が、Journal of Computer Chemistry, Japan にて論文公開になりました。タイトルは
モデルの適用範囲の考慮したアンサンブル学習法の開発
です。下の URL から無料でご覧になれますので、もし興味がございましたらよろしくお願いいたします。

回帰分析においてアンサンブル学習は、元のデータセットからサンプルや特徴量をランダムに選択して、たくさんのサブデータセットを作成し、サブデータセットごとに回帰モデル (サブモデル) を構築する方法です。

アンサンブル学習するとき、各サブモデルにおけるモデルの適用範囲 (Applicability Domain, AD) を考慮したほうが、最終的なモデルの推定性能が上がることは確認されていましたが、
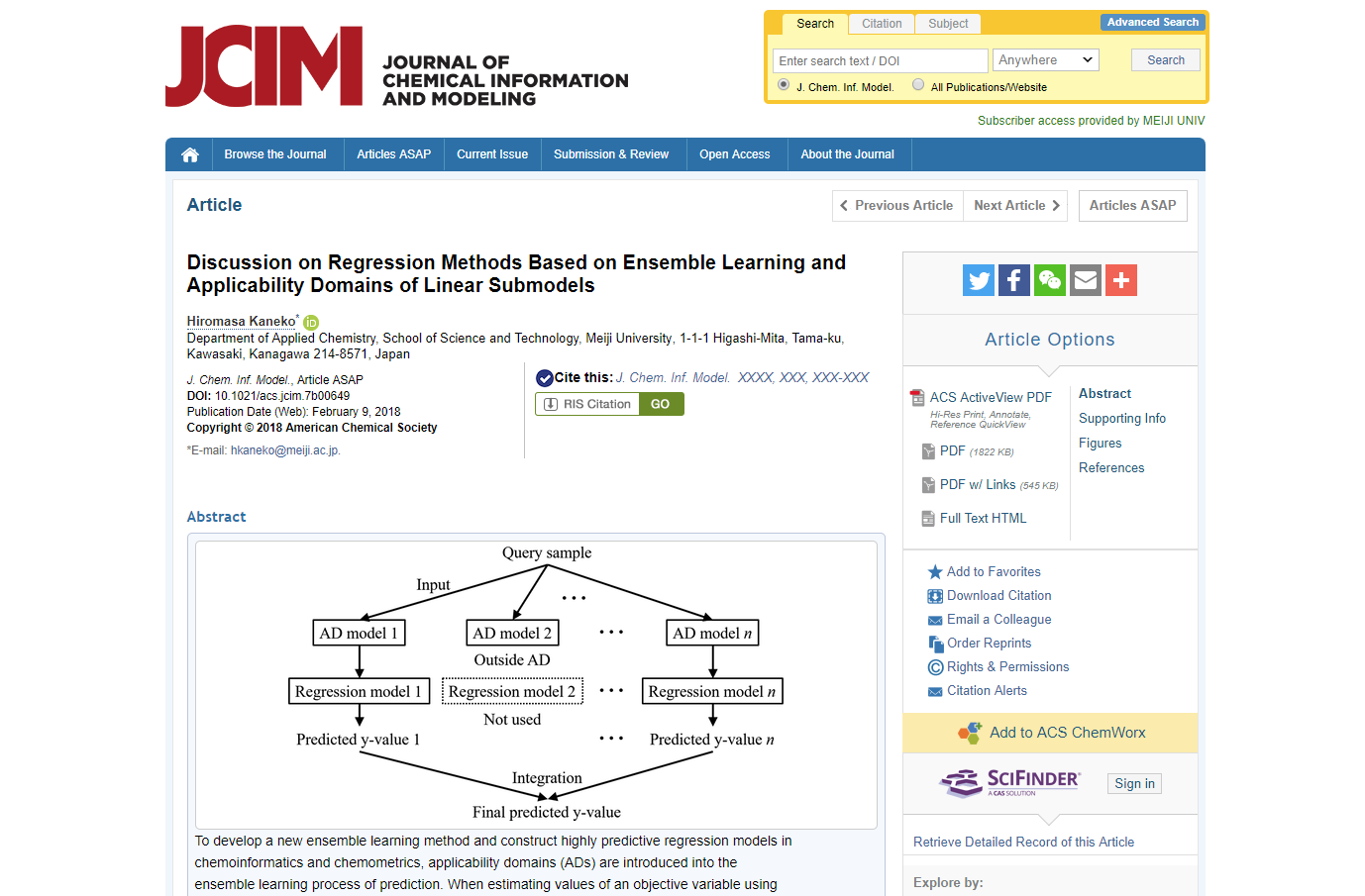
サブモデルごとの AD を定量的に比較することができず、その結果 AD を統合できなかったため、適切に新しいサンプルを予測することができませんでした。定量的に統合できない理由として、データ密度に基づく AD の場合、基本的にサンプル間の距離 (ユークリッド距離) に基づくため、アンサンブル学習で特徴量を (ランダムに) 選択すると、距離のスケールがサブモデルごとに異なり、それに応じてデータ密度のスケールも異なってしまうためです。
そこで、サブモデルごとの AD を統合すべく、特徴量の数と種類に依存しない AD の指標をいろいろと検討したところ、similarity-weighted root-mean-square distance (wRMSD) という指標がよさそうだという結果になりました。これはデータ密度と目的変数の推定誤差の両方を考慮した AD の指標であり、最終的な AD のスケールは目的変数のスケールになるため、サブモデル間で AD のスケールが同じになり、定量的な議論が可能になります。
wRMSD の値をサブモデルごとの重みに変換します。wRMSD は誤差と考えることができるため、wRMSD を逆数にして r 乗したものが重みになります。r の値はクロスバリデーションで最適化します。
この手法を wRMSD-based AD considering Ensemble Learning (WEL) と名付けました。WEL を用いることで、予測したいサンプルごとにそのサブモデルと近いほど (そのサブモデルでうまく予測できそうなほど) 重みが大きくなり、その重みに基づいて最終的な予測値を計算できます。
回帰分析手法として Partial Least Squares (PLS)
を対象にして、PLS, アンサンブルPLS, WEL-PLS で比較検討したところ、水溶解度のデータセット・環境毒性のデータセット・薬理活性のデータセットすべてにおいて、WEL-PLS がベストの推定性能を発揮しました。
回帰モデルの推定性能の向上に興味がございましたら、お読みいただければと思います。
また WEL の Python プログラムは、デモと一緒に https://github.com/hkaneko1985/wel に無料公開しておりますので、ぜひ一度お試しください。
以上です。
質問やコメントなどありましたら、twitter, facebook, メールなどでご連絡いただけるとうれしいです。

