回帰モデルを構築するとき、過学習 (オーバーフィッティング) が問題になります。ここではリッジ回帰・LASSO・Elastic Net といった正則化項を用いる手法を例にして、
最小二乗法による線形重回帰分析との関係や、オーバーフィッティングを防ぐメカニズムを説明します。
最小二乗法による線形重回帰分析では、線形のモデル y = a1x1 + a2x2 + ・・・ を仮定して、目的変数 y の誤差の二乗和が最小になるように、回帰係数 a1, a2, … を決めます。
(y の誤差の二乗和)
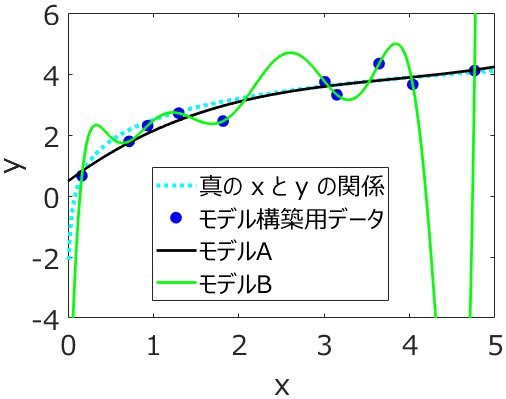
この方法によって、y の誤差が小さくなる回帰係数を求めることはできますが、オーバーフィッティングが生じてしまうこともあります。つまり、トレーニングデータのサンプルに対しては y の誤差が小さくなりますが、それら以外のサンプルに対して誤差が大きくなってしまう、ということです。
このオーバーフィッティングと関係することとして、回帰係数の絶対値が大きくなることが挙げられます。こちらに具体例があります。
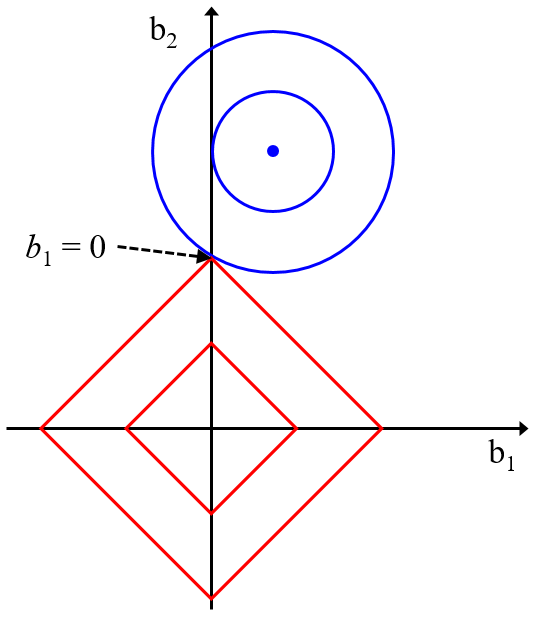
そのため、回帰係数の絶対値を小さくすることでオーバーフィッティングを防げるだろうということで、正則化項が出てきました。この正則化項は、回帰係数の大きさに関する項です。y の誤差の二乗和だけでなく、回帰係数の大きさも小さくすることで、オーバーフィッティングを防げるだろう、ということです。そのためリッジ回帰・LASSO・Elastic Net では以下の式を最小化する回帰係数を計算します。
(y の誤差の二乗和) + (重み) × (回帰係数の大きさ)
リッジ回帰・LASSO・Elastic Net それぞれ、(回帰係数の大きさ) の項が異なります。そしてうまく (重み) を調整することで、(y の誤差の二乗和) と (回帰係数の大きさ) の両方がいい塩梅で小さくなるように、回帰モデルを構築することが目的になります。
もちろん、トレーニングデータにおける y の誤差が小さくなるように (重み) を決めてしまうと、(重み) = 0、すなわち最小二乗法による線形重回帰分析とまったく同じになってしまいます。そのため、y の誤差の二乗和を計算したデータ以外のデータを用いて、(重み) を決める必要があります。よく使われるのがクロスバリデーションです。

クロスバリデーション後の y の予測誤差が最小になる (重み) の値にすることで、予測精度を考慮して (重み) を決めることができます (もちろん結果的に (重み) = 0 になることもあります)。このようにして、回帰係数を決めるときのデータ以外のデータを予測できるような、正則化項の重みを決め、オーバーフィッティングを防ごうというわけです。
ちなみに、サポートベクター回帰 (Support Vector Regression, SVR) もリッジ回帰・LASSO・Elastic Net の仲間といえます。

特にリッジ回帰とは (回帰係数の大きさ) の項がまったく同じです。ただ SVR では、(y の誤差の二乗和) の代わりに y の誤差関数があります。またカーネル関数によって非線形モデルを構築することもできます。
リッジ回帰・LASSO・Elastic Net・SVR のどれが、解析しているデータセットに適しているかは、データセットに依存しますし、解析してみないとわかりません。いろいろと比較検討しながら、オーバーフィッティングを防げる手法を選択するとよいでしょう。
以上です。
質問やコメントなどありましたら、twitter, facebook, メールなどでご連絡いただけるとうれしいです。