説明変数 x と目的変数 y の間で回帰モデルやクラス分類モデルを構築するとき、モデルの予測精度やモデルの解釈性を向上させるため、特徴量選択 (変数選択) をすることがあります。例えば 1000 個の x があるとき、特徴量選択をして 50 個の x が選択されたら、その後、50 個の x のみでモデルを構築したり、重要な特徴量として 50 個の x を詳細に検討したりします。
ただ、選択されなかった 950 個の x の中に、選択された 50 個の x のどれかと高い相関を持つ特徴量があるとき、互いに高い相関がある特徴量のうちどちらでも結果がほとんど同じ、ということもあります。ある特徴量が選択されなかったからといって、その特徴量は重要な特徴量ではない、と必ずしもいえません。また、ある特徴量が選択されたからといって、それがない上手くいかないほど重要だ、とは必ずしもいえません。
そこで、選択された特徴量・選択されなかった特徴量の結果を、以下のように整理してはいかがでしょうか。
まず、選択された特徴量と選択されなかった特徴量の、すべての組み合わせの間で、特徴量間の類似度を計算します。線形で問題なければ、類似度として相関係数の絶対値が使えますし、非線形性を考慮したいのであれば、Maximal Information Coefficient (MIC) や (サンプル間ではなく特徴量間の) ガウシアンカーネルも利用できます。なおガウシアンカーネルを使うときは、特徴量はオートスケーリングした方がよいです。
そして、計算された類似度を表にまとめます。この表は、縦に選択された特徴量を並べ、横に選択されなかった特徴量を並べ、表の各セルに特徴量間の類似度の値を入れたものになります。
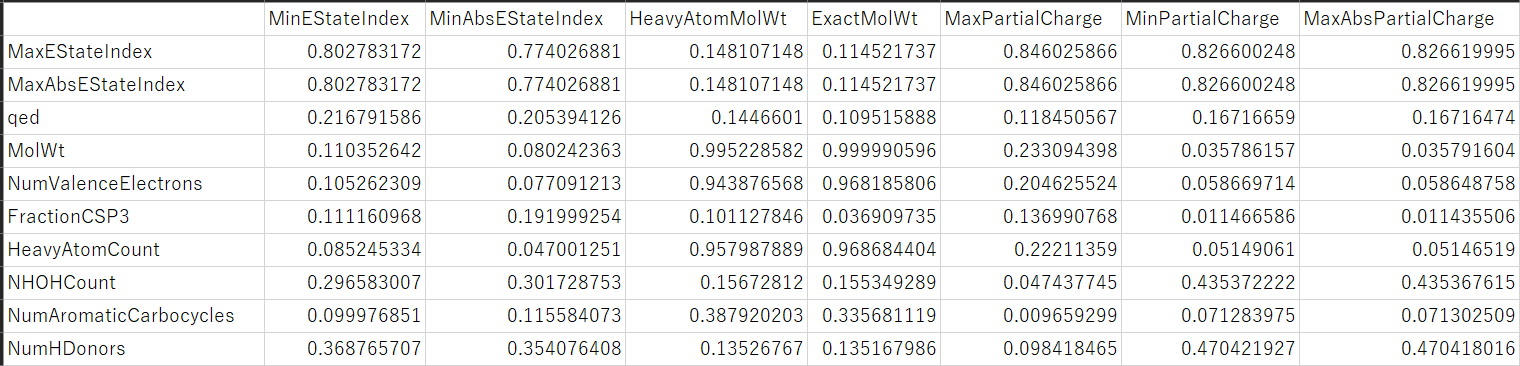
特徴量が多いとき、0 から 1 の数値ではなく、表を色付けして、例えば 0 に近いほど青く、1 に近いほど赤くすると見やすいかもしれません。
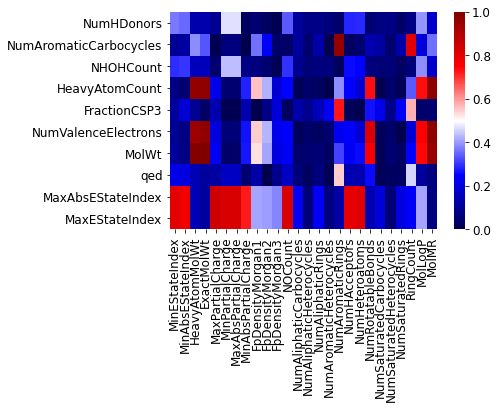
この表を見ることで、縦にある選択された特徴量と類似している選択されなかった特徴量を眺めることができます。選択された特徴量と類似度が高い、つまり選択された特徴量と似ている特徴量は、選択されなかったとしても重要である可能性があります。
以上のように選択された特徴量と選択されなかった特徴量を整理して確認すると、特徴量の重要性の議論がしやすいと思います。Python コードがこちらにありますので、ぜひご利用ください。
注意点として、この方法では一対一の類似度しか見ていません。例えば複数の特徴量の組み合わせで別の特徴量を表すような関係は確認できませんのでご注意ください。
以上です。
質問やコメントなどありましたら、twitter, facebook, メールなどでご連絡いただけるとうれしいです。