データセットにおいて、空欄があるときがあります。
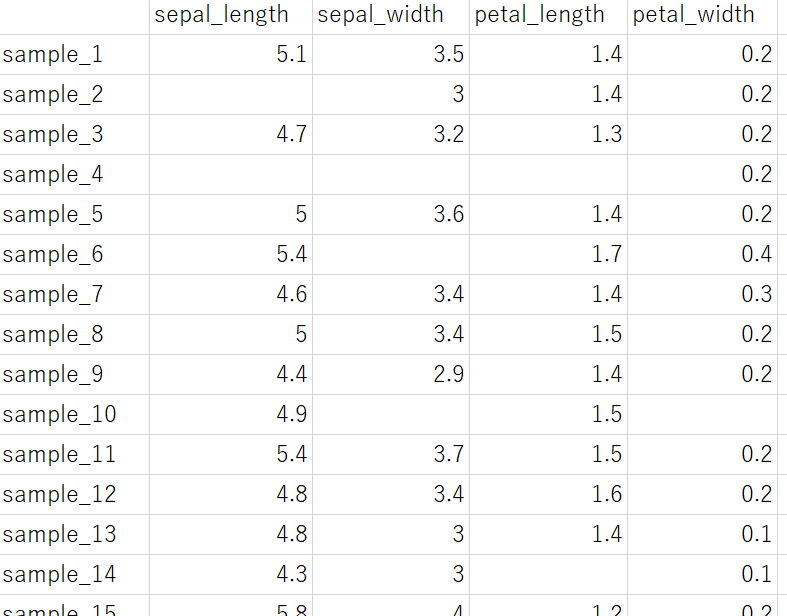
すべてのサンプル、そしてすべての特徴量に値が準備されているわけではなく、穴あきのデータセットということです。データ解析や機械学習をするためには、まずこの空欄を埋める必要があります。もちろん場合によっては、空欄のあるサンプルや空欄のある特徴量を削除する、といった選択肢もありますが、ここでは空欄を埋める方向で説明します。
最初に考えることは、その空欄の意味合いです。同じ空欄でも、意味合いが異なるのであれば、それを埋める方法も異なります。
例えば組成比や何らかの量を表す特徴量における空欄において、空欄は対象の物質を入れていないことを意味するのであれば、空欄には 0 を入れることになります。そうではなく、入れていないわけではありませんが、値が不明、ということであれば、欠損値として扱う必要があります。欠損値の扱いについては後ほど説明します。
例えば実験操作を表すカテゴリー変数のとき、操作していないこと (加熱していない、冷却していない、など) を表すときには、そのような “何もしていない” といった意味のカテゴリーを入れることになります。単に操作の内容が不明であれば、欠損値として扱う必要があります。
装置の条件において、何かデフォルトの値を使用している場合であれば、そのデフォルトの値を入力することになります。デフォルトの値かどうかも不明であれば、欠損値として扱う必要があります。
それぞれ、もちろんなるべく妥当な値やカテゴリーを入れようとしますが、ある程度仮定をおいて空欄を埋める必要があったり、最適でなくてもベターな値やカテゴリーを入れる必要があったりもします。
過去にさかのぼって測定できない場合や、文献からデータを収集したときなどに文献に対象の特徴量に関する記載がない場合など、何らかの値が入るにもかかわらずその値がわからない場合は、欠損値として扱う必要があります。欠損値は iGMR で補完するとよいです。

以上です。
質問やコメントなどありましたら、twitter, facebook, メールなどでご連絡いただけるとうれしいです。

