分子設計・材料設計・プロセス設計・プロセス管理において、分子記述子・実験条件・合成条件・製造条件・評価条件・プロセス条件・プロセス変数などの特徴量 x と分子・材料の物性・活性・特性や製品の品質などの目的変数 y との間で数理モデル y = f(x) を構築し、構築したモデルに x の値を入力して y の値を予測したり、y が目標値となる x の値を設計したりします。
変数選択、特徴量選択、モデルの逆解析などにメタヒューリスティクス (最適化アルゴリズム) を使用することがあります。ここでは遺伝的アルゴリズム(Genetic Algorithm, GA)を例にして説明しますが、他の最適化アルゴリズムでも同じことが言えます。例えば、GA を用いて変数選択をしたり、

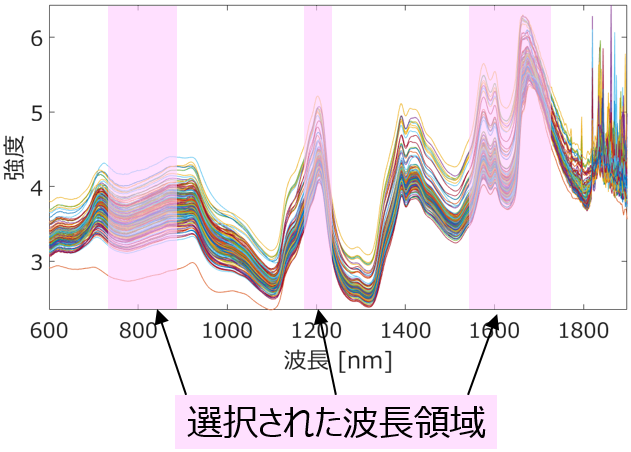
変数がスペクトルの時には範囲で選択したり時系列データの時には時間遅れを考慮して変数を選択したり、
モデルにおける最適な予測値を求めたり、
ベイズ最適化において獲得関数が大きくなるXの範囲を探索したりします。

GA を用いたことのある方はご存知かと思いますが、GA の初期個体や乱数の種によって、たとえそれぞれ計算が収束していたとしても、計算ごとに最終的な結果が異なることが多々あります。また、GA と言っても局所最適解に陥る可能性はゼロではありません。そのため、何回か GA の計算を実施することになります。
例えば 10 回計算したら 10 個の結果が出てきます。その際、10 個全体を合計したり平均したりして見る人もいますが、GA で最適化された結果については、染色体の中の組み合わせが大事なので、どれが何回選択されたかではなく、結果それぞれにおける選択された内容の組み合わせが重要です。
そのため、10個の結果が得られたら、一つ一つ個別に見る必要があり、10個の中から結果を選択することになります。
選択の1つの指針として、GA の適合度が高いものを選びます。GA では染色体の適合度が大きくなるよう最適化されるため、適合度が最も高い結果が良好な結果と考えられるためです。例えばベイズ最適化と GA を組み合わせて x の候補を探索する時には、獲得関数を適合度として複数回 GA 計算を行い、その中で適合度の値が最も大きくなる x の候補を選択すると良いでしょう。
注意点としては、適合度が高い時に必ずしも結果が良好とは言えない場合があることです。例えば、変数選択においてクロスバリデーション後の r2 を適合度にする時がありますが、もちろんクロスバリデーション後の r2 が高い方が外部データに対する予測性が大きくなる傾向はある一方で、クロスバリデーション後の r2 が高いとクロスバリデーションの結果にオーバーフィッティングしている可能性も高まります。手放してクロスバリデーション後の r2 を大きくすれば良いというわけではないわけです。
選択のもう1つの指針として、結果がドメイン知識と合っているか、結果を解釈できるかといった、データ解析・機械学習以外の考えで選択します。選択された内容をドメイン知識と照らし合わせたり、解釈したりする時に、もちろん全てではないかもしれませんが、部分的にドメイン知識と合っていたり、解釈できたりすると良いでしょう。例えば、クロスバリデーション後の r2 が他と比べて多少小さくても、ドメイン知識と合っていたり、解釈できたりする方を選択することがあります。
GA では計算ごとに結果が変わるため、繰り返し計算した方が良いです。その結果得られる複数の GA の結果について、上のような指針で選択すると良いでしょう。
以上です。
質問やコメントなどありましたら、X, facebook, メールなどでご連絡いただけるとうれしいです。

