機械学習の手法、統計的・情報学的手法の中には、教師なし学習や教師あり学習があります。教師なし学習では、変数を使ってサンプル群を可視化(見える化)したり、クラスター解析(クラスタリング)したりします。教師あり学習では、物性・活性などの目的変数(教師データ)と、構造記述子などの説明変数があり、目的変数と説明変数との関係を解析します。目的変数が連続値のときが回帰分析であり、クラスラベルのときはクラス分類です。
まとめると下のようになります。
- 教師なし学習
- データの可視化(見える化)・低次元化 (主成分分析PCA・自己組織化マップSOMなど)
- クラスタリング (階層的クラスタリング・k-means法など)
- 教師あり学習
- 回帰分析 (部分的最小二乗法PLS・サポートベクター回帰SVRなど)
- クラス分類 (線形判別分析LDA・サポートベクターマシンSVMなど)
そして、教師なし学習と教師あり学習との中間的な位置づけとして、半教師あり学習(半教師つき学習)があります。今回は、教師あり学習寄りの半教師あり学習を考えます。つまり、教師なしのサンプル (目的変数の値のないサンプル) を使って、回帰分析・クラス分類の精度を向上させよう!という方法です。
クラス分類の半教師あり学習の概要
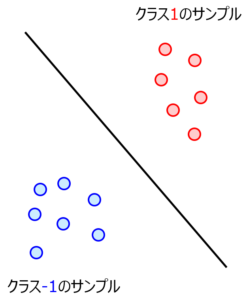
クラス分類の半教師あり学習について説明します。クラス分類においてクラス1のサンプルとクラス-1のサンプルがあるとき、下図のように判別式が作られます。ちょうどクラス1のサンプル群とクラス-1のサンプル群との間くらいに直線が通っていますね。
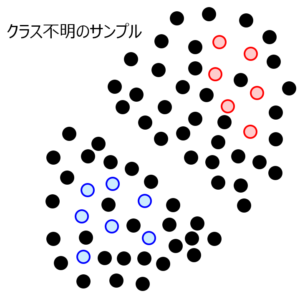
ここで、教師なしのサンプル、つまりクラス1かクラス-1かわからないサンプルが、下のようにあったとします。
このとき、半教師あり学習によって、次の図にあるような直線になります。
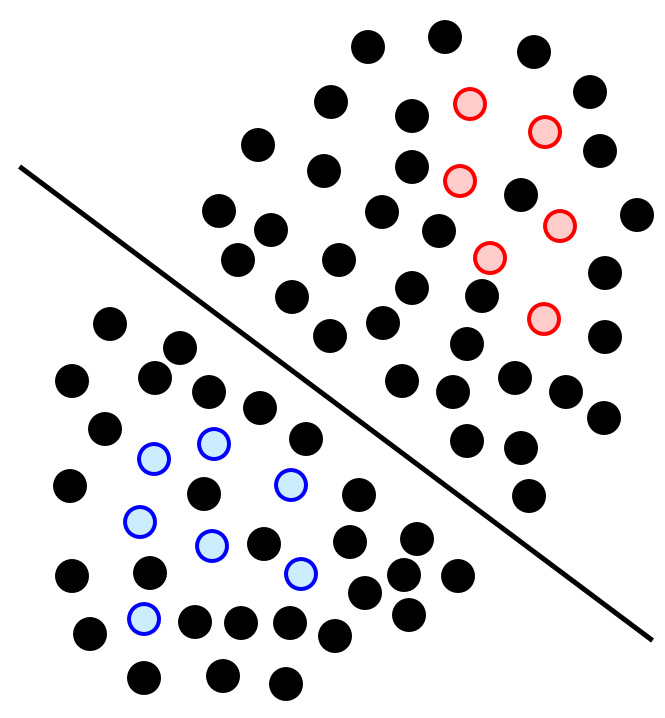
クラス1のサンプルに近い教師なしサンプルはクラス1とみなされ、クラス-1のサンプルに近い教師なしサンプルはクラス-1とみなされ、その結果、それらのサンプル群の間くらいに直線が引かれることになります。
このように、特にクラスのわかっているサンプルがすくないときに、クラスのわからない多数のサンプルを活用することで、より妥当な判別式をつくれるだろう、というのがクラス分類の半教師あり学習です。
回帰分析の半教師あり学習で同じようなメリットを得るのは難しい
回帰分析の半教師あり学習でも、クラス分類と同じようなメリットが得られるのでしょうか。わたしは難しいと考えています。その理由を説明するため、たとえば下図のように教師ありサンプル2つに教師なしサンプルがある場合を考えます。
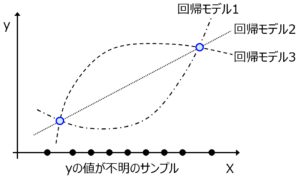
このとき、回帰モデル1, 2, 3のように、教師ありサンプル2つを通る回帰モデルの候補はたくさんありますが、教師なしサンプルが与えられたからといって、どの回帰モデルがより正しいかについての情報になるわけではありません。そのため、回帰分析の半教師あり学習はクラス分類と同じようなメリットは得られないと考えられます。
しかし、回帰分析の教師あり学習にも、他にちゃんとメリットがあります。
半教師あり学習のメリット
そもそも、半教師あり学習のメリットとして以下の4つがあると考えています。
- クラス間の境界が明確になる (クラス分類のみ)
- モデルの安定性が向上する
- モデルの適用範囲が広がる
- 説明変数の事前分布が明確になる
1. は最初に説明したメリットであり、クラス分類のみです。そのほかの3つを説明します。
モデルの安定性が向上する
教師なしデータによって、回帰モデル・クラス分類モデルが安定化します。たとえば、PLSでは目的変数との共分散が大きくなるように説明変数を主成分に低次元化してから回帰分析を行います。そして、とくに教師ありサンプルが少ないと、主成分が不安定になってしまいます。つまり、仮にサンプルを1つ増やしたり1つ減らしたりしたときに、主成分が大きく変わってしまうわけです。
このようなときに、はじめに教師なしサンプルを含めたサンプルを用いて、たとえば主成分分析などにより低次元化します。教師なしサンプルはたくさんありますので、安定した低次元化が達成されます。この低次元空間において回帰モデル・クラス分類モデルをつくることで、安定したモデルが作成されると考えられます。
モデルの適用範囲が広がる
モデルの適用範囲が広がることも、教師なしサンプルを使用した適切な低次元化に関係します。モデルの適用範囲の決定は、モデル構築用サンプル(トレーニングサンプル)が存在する領域を決めることに対応します。たくさんの説明変数があったとしても、実際にはそれより低次元空間においてサンプルが存在することが多いです。とくに教師ありサンプルが少ないときは、より低い次元で表現できる傾向が強くなります。そのため、適切に低次元化することで、トレーニングサンプルが存在する領域をうまく決めることができると考えられます。
説明変数の事前分布が明確になる
説明変数の事前分布がはっきりすることは、モデルの逆解析のときに重要になってきます。回帰モデル・クラス分類モデルがつくられたあとに、説明変数の値をモデルに入力して目的変数の値を得るのが、モデルの順解析であり、逆に目的変数の値からモデルを用いて説明変数の値を獲得するのが、モデルの逆解析です。
モデルの逆解析の方法の1つに、ベイズの定理を用いたやり方があります。そもそも、回帰モデル・クラス分類モデルをつくることは、説明変数Xが与えられたときの目的変数yの確率 p(y|X) を求めることに対応します。モデルの逆解析は、yが与えられたときのXの確率 p(X|y) を得ることですので、p(y|X) から p(X|y) を計算したいわけです。
これらを関連付けるやり方がベイズの定理を用いた方法であり、具体的には、
p(X|y) = p(y|X)p(X) / p(y)
で与えられます。ここで出てきた p(X) がXの事前分布であり、教師ありサンプルだけでなく教師なしサンプルも含めて計算することができます。より多くのサンプルを用いることでXの分布が明確になることで、
p(X|y) = p(y|X)p(X) / p(y)
で与えられる p(X|y) も明確になり、逆解析に貢献するわけです。
最後に
これまで半教師あり学習のメリットを述べてきましたが、使用する教師なしデータはなんでもよいわけではない、と考えています。今後は、半教師あり学習に用いる教師なしデータを適切に選ぶことが重要になると思います。
以上です。
質問・コメントがありましたら、twitter・facebook・メールなどを通して教えていただけるとうれしいです。