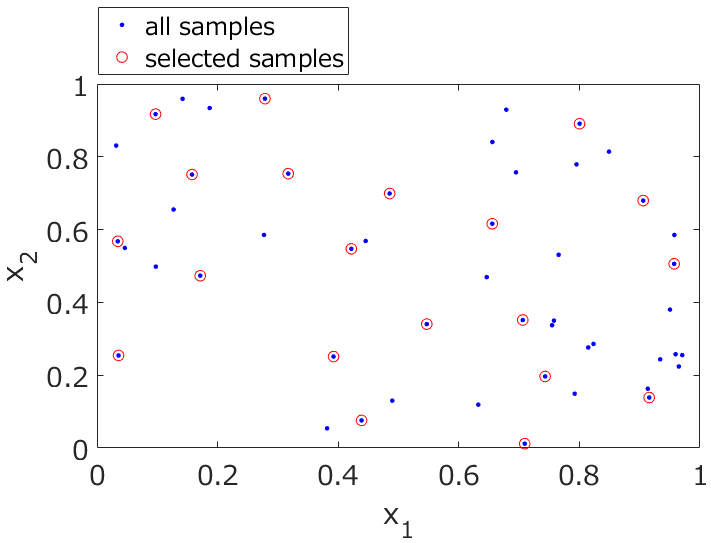
トレーニングデータ・バリデーションデータ・テストデータの定義について書いておきます。バリデーションデータとテストデータとを逆の意味に使う人もいますが、ここでは wikipedia に記載されている内容にあわせます。
トレーニング、つまり学習についてはこちらをご覧ください。
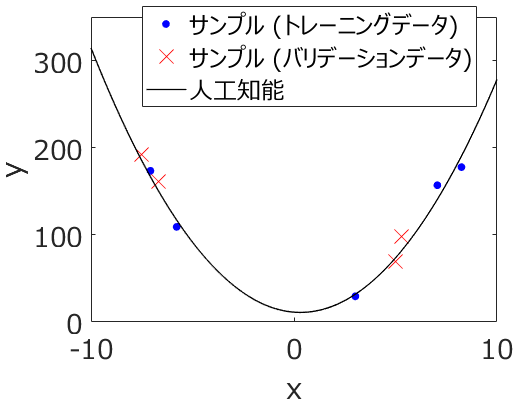
トレーニングデータ (training dataset)
トレーニングデータは、回帰モデルやクラス分類モデルを構築するためのデータです。たとえば最小二乗法による線形重回帰分析をするとき、このデータにおける目的変数 y の誤差の二乗和を最小にするよう回帰係数が決められます。
トレーニングデータは、特にスペクトル解析の分野において、キャリブレーションデータ (calibration dataset) とよばれることもあります。
ちなみに日本語でいうと、モデル構築用データです。
バリデーションデータ (validation dataset)
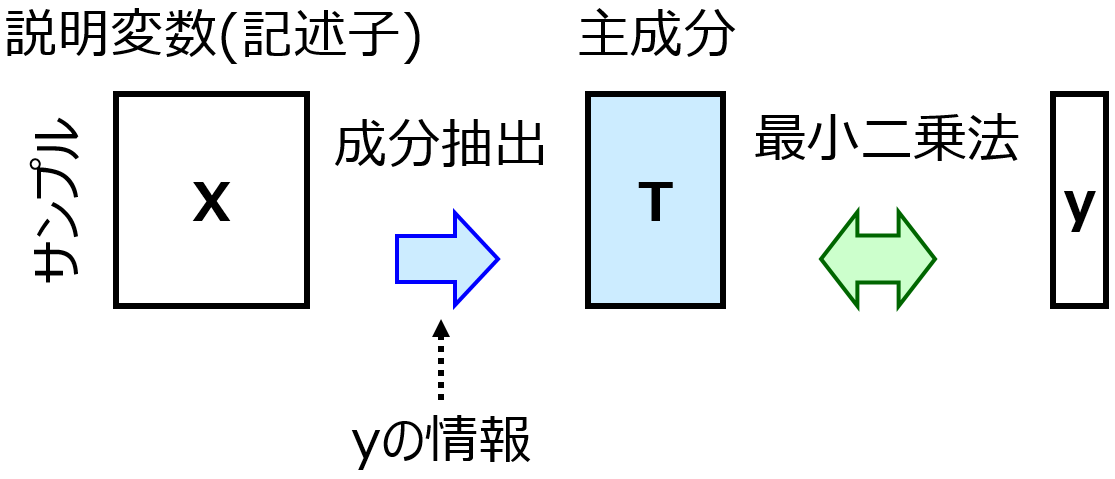
バリデーションデータは、回帰モデルやクラス分類モデルのハイパーパラメータを決めるためのデータです。たとえば部分的最小二乗回帰 (Partial Least Squares Regression, PLS) におけるハイパーパラメータは成分数です。成分数を 1, 2, 3, … と変えてモデルを構築し、それぞれのモデルでバリデーションデータの y の値を推定します。そして、yの実測値と推定値で計算された決定係数 r2 が最大となる成分数を選ぶわけです。
ハイパーパラメータを選んだ後は、トレーニングデータとバリデーションデータとを合わせてモデルを構築します。たとえばPLSのときは、選ばれた成分数で再び回帰モデルを構築するわけです。
ちなみに、バリデーションデータを用いずに、トレーニンデータのみからクロスバリデーションによりハイパーパラメータを選ぶ方法もあります。わたしは、ほとんどの場合において、クロスバリデーションでハイパーパラメータを選んでいます。


テストデータ (test dataset)
テストデータは、トレーニングデータとバリデーションデータとを合わせたデータで構築された、回帰モデルやクラス分類モデルの推定性能を、最終的に検証するためのデータです。y の実測値を隠しておき、最終的なモデルで y の値を推定してから答え合わせをするため、ブラインドデータ (blind dataset) とも呼ばれます。
日本語でいうと、モデル検証用データです。
以上です。
質問やコメントなどありましたら、twitter, facebook, メールなどでご連絡いただけるとうれしいです。