データ化学工学研究室 (金子研) では、分子のデータや材料のデータやプロセスの時系列データなど、化学データ・化学工学データを扱ってデータ解析・機械学習をしています。データ解析の基本的な流れは、ある程度固まっていることから、

データ解析を成功させる秘訣の一つはデータベースにあります。ただ、実際にデータベースを用いてデータ解析してみないと、データ解析が成功したかどうかはわからず、どのようなデータベースであれば成功するのに十分か、といった議論は難しいです。
とはいえ、こんなデータベースであれば、(成功するかどうかはさておき) データ解析しやすいよね、ということはあります。このあたりを解説します。
まず基本的なこととして、csv ファイルにまとめておくと、データ解析しやすいです。エクセルで作成しようとすると、基本的には xlsx ファイルになりますが、保存するときに csv にしましょう。csv ファイルのほうが、余計な情報がなく扱いやすいです。
その他については、データセットの種類ごとに説明します。
実験条件・製造条件のデータセット
たとえば高機能性材料を作るための実験条件・製造条件 (レシピ) と、その結果としての物性・活性・特性などがそろったデータセットです。下図のような感じです。
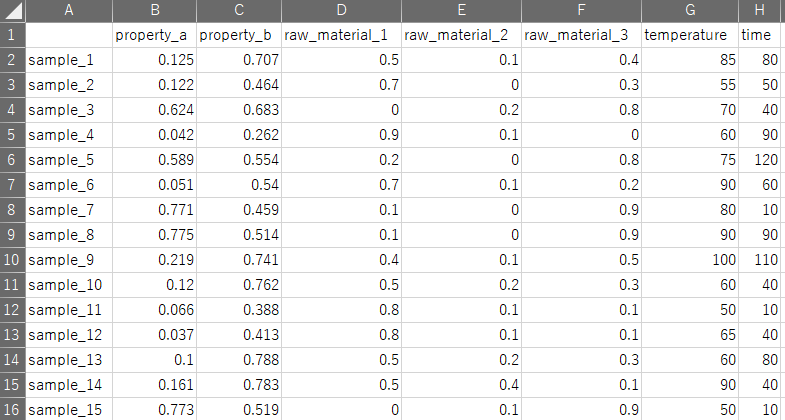
このように、縦にサンプルを、横に実験条件・製造条件といったパラメータを並べたデータセットを作ります。
文字が入ったパラメータがあってもよい
サンプルによってカテゴリーが違うような、文字の入ったパラメータ (実験条件・製造条件) があってもよいです。こちら
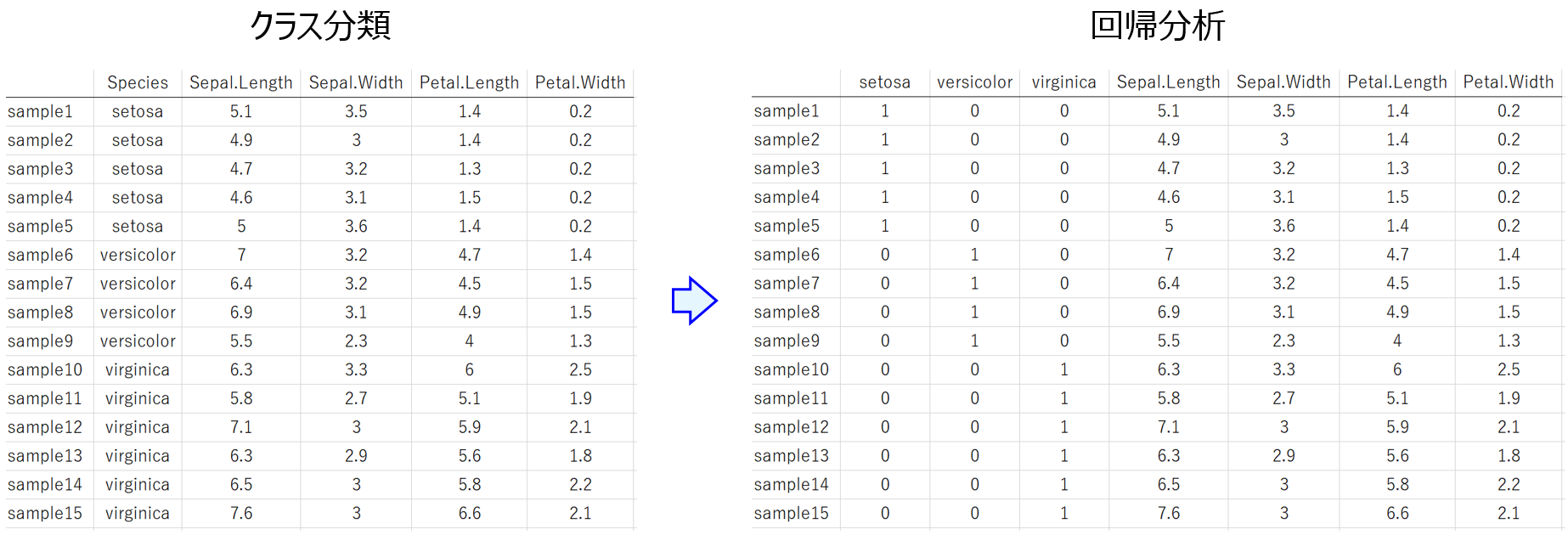
に示したように、文字のパラメータがあっても簡単に数値化できます。
とはいえ、たとえば添加剤Aを 「入れる」 or 「入れない」 といった単純なパラメータであれば、データベースを作る段階で、「入れる」 を 1 で、「入れない」 を 0 として、数値のパラメータとしておいたほうが楽かもです。まあ、どちらでも OK です。
欠損値があってもよい (穴あきのデータセットでもよい)
材料によっては、ある物性Aの測定値はあっても別の物性Bの測定値はないサンプルがあったり、別のサンプルでは物性Bの測定値はありますが物性Aの測定値はなかったり、穴あきの状態のこともあります。それでも問題ありませんので、とにかくサンプル数を増やしましょう。
ちなみに、欠損値は以下の手法で補完することができます。

「ない」 場合にはしっかりと 0 を入れておきましょう
たとえば、いろいろな原料を使ったり使わなかったりする場合に、原料Aの組成、のようなパラメータがあったとします。原料Aを使わないサンプルのとき、何も値を入れないのではなく、しっかりと意味のある「0」を入れましょう。上の欠損値の場合と区別するためです。何も書かれていないと、測定されていないのか、入れてないのか、わかりません。「入れていない」 ことを明確に示すため、0 を入れるわけです。
もし、「ない」 ところを空白にしておくデータベースであれば、欠損値にはありえない値 (-999など) を入れて、区別することもできます。
化合物のデータセット
化合物の物性・活性などの情報と化学構造のデータベースは、こちらの「化合物群のデータセットの扱い」に示したように、
化合物ごとに SMILES と物性・活性等を併記する方法や、 Structure-Data File (SDF) と呼ばれるデータベース形式で整理する方法があります。mol ファイルがたくさんある場合は、csv ファイルの SMILES の部分を mol ファイルのファイル名にして、別のフォルダ (ディレクトリ) に mol ファイル群を置いておくとよいでしょう。データベースを使用するときは、mol ファイルの名前から対象の mol ファイルを読み込む流れになります。
あとは、実験条件・製造条件のデータベースのように、物性や活性の値に欠損値があってもかまいませんので、とにかくサンプル数を増やしましょう。また、値が 0 のサンプルには、しっかりと 0 を入れましょう。
サンプルに対して、化学構造だけでなく実験条件・製造条件もある場合は、パラメータとして横に追加してデータベースを作りましょう。
スペクトルのデータセット
1つのサンプルは、物性・活性の値とスペクトルとのセットになります。まず物性や活性、そして強度・吸光度の値のある波長・波数がパラメータになります。上の図のようにして、パラメータを横に並べて、サンプルごとに値を格納していきましょう。
あとは、実験条件・製造条件のデータベースのように、値が 0 のサンプルには、しっかりと 0 を入れましょう。
時系列データ (連続・バッチ)
プラント・装置におけるプロセスデータのように、時刻ごとにサンプルが並んだデータセットです。新しい時刻のサンプルほど下に来るようにデータベースを作りましょう。
測定されていない時刻は、欠損値にしておくか、直近に測定された値を入れておく
プロセス変数によっては、特に推定したいパラメータなど、頻繁には測定されていないものもあります。ある時刻において、他のパラメータの測定値はあっても、あるパラメータの測定値はない状況です。そのような場合には、以下のどちらかにしましょう。
- 測定値のない時刻を欠損値にする
- 直近に測定された値を入れておく
2. では、データ解析のときに、値が変化した時刻をそのパラメータが測定された時刻とします。たまたま測定値が直近の測定値の (厳密に) 同じ値となってしまったとき、その時刻は測定された時刻とは認識されませんので、その可能性があり避けたい場合は、1. にしておくとよいです。
あとは、実験条件・製造条件のデータベースのように、値が 0 のサンプルには、しっかりと 0 を入れましょう。
また、バッチプロセスのデータは、バッチごとに csv ファイルを作成しておくとよいです。そして、バッチごとの情報をまとめる csv ファイルも作成し、そこに各バッチの csv ファイルの名前を入れるパラメータや、最終製品の品質やある時刻での物性・活性といったバッチごとのパラメータを準備します。こうすることで、バッチごとに特徴量を計算したり、特徴量とバッチごとのパラメータとの間でモデル構築をしたりすることが、やりやすいです。
以上です。
質問やコメントなどありましたら、twitter, facebook, メールなどでご連絡いただけるとうれしいです。