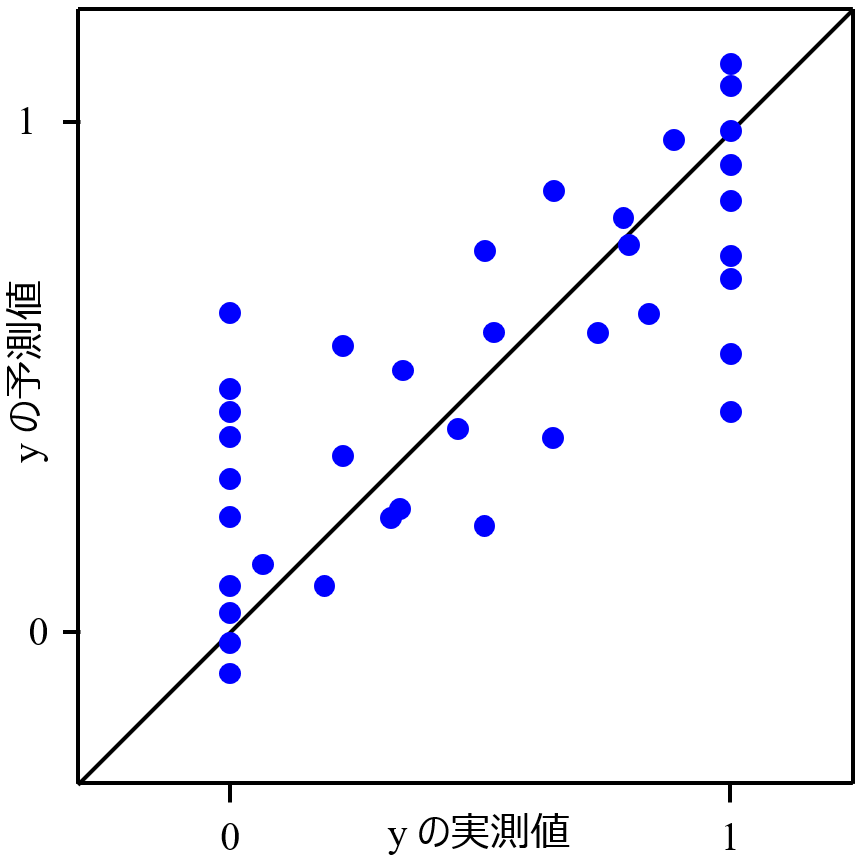
分子設計・材料設計・プロセス設計・プロセス管理において、分子記述子・実験条件・合成条件・製造条件・評価条件・プロセス条件・プロセス変数などの特徴量 x と分子・材料の物性・活性・特性や製品の品質などの目的変数 y との間で数理モデル y = f(x) を構築し、構築したモデルに x の値を入力して y の値を予測したり、y が目標値となる x の値を設計したりします。
モデルを構築するとき、ドメイン知識を考慮したりモデルの予測精度を上げたりするため、x ごとに異なる重みを付けたいことがあると思います。ドメイン知識的に、他より重要な x だけ 100 倍の重みにしたい、といった具合です。このとき、ただ単純に x に 100 を掛けたり、他の x に 1/100 を掛けたりしただけでは、まったく意味がないことがあります。また、意味がある場合でも、適切に重みを与えないと意味がなくなってしまいます。このあたりを説明します。
最小二乗法に基づく線形重回帰分析において重みは意味がない
まず、最小二乗法に基づく線形重回帰分析においては、x に何を掛けても意味がありません。
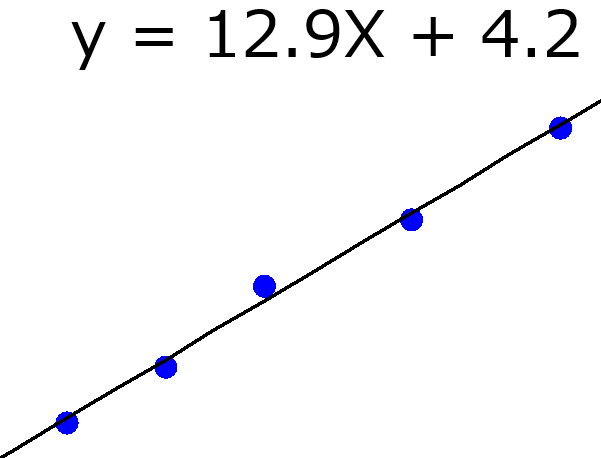
例えば、x に1億をかけて回帰係数を計算しても、元の回帰係数が1億分の1になった回帰係数が出力されるのみになってしまいます。
決定木や決定木+アンサンブル学習系 (ランダムフォレストなど) でも重みは意味がない
また、決定木や、ランダムフォレスト・決定木を用いる勾配ブースティングなどの、決定木系の手法においても、x に何を掛けても意味がありません。
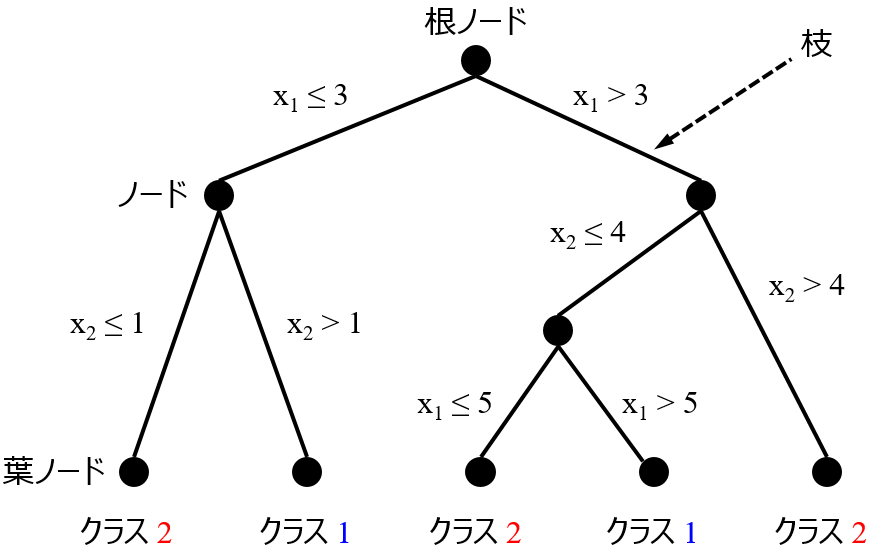
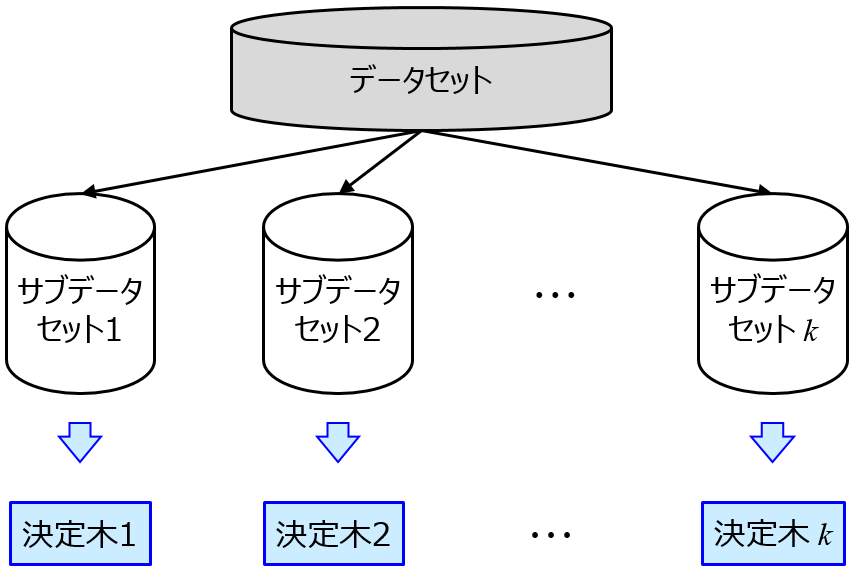

決定木は、x の閾値のみが重要ですので、x に値を掛けて重みを付与したとしても、閾値が変わるだけでモデルの予測結果には影響がありません。
値を掛けるときはオートスケーリングしてから!
線形のモデルでも、リッジ回帰、LASSO、Elastic net など、回帰係数の大きさも目的関数に入っている手法であれば、モデルに対する重みの影響はあります。
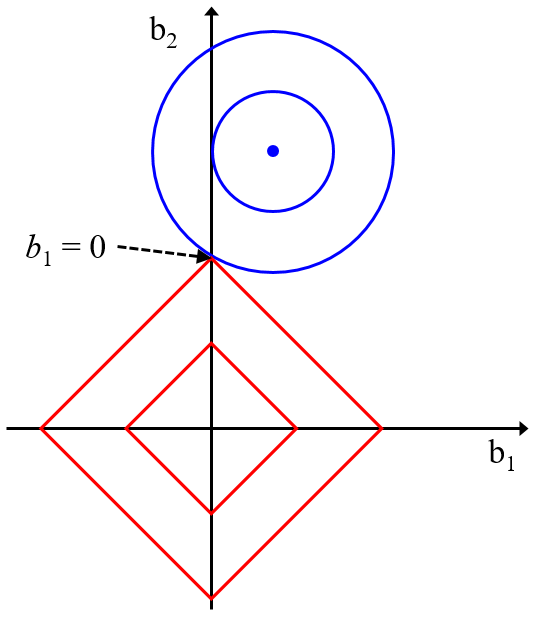
また、ガウシアンカーネルを使用したときのサポートベクター回帰やガウス過程回帰のように、サンプル間の類似度もしくは距離に基づくモデルであれば、重みの効果があります。

距離を計算するときに、重みを掛けた x における値の大小関係が、計算される距離により依存するようになり、これが重みの効果になります。

ただ、一つ注意することとしては、いきなり最初に重みを掛けない、ということです。基本的にモデル構築前にオートスケーリングをすると思いますので、オートスケーリング前に重みをかけてしまうと、結局オートスケーリングして平均 0、標準偏差 1 になってしまいます。そのため、オートスケーリング後に重みを掛けるようにしましょう。
特徴量 x の重みを考慮してデータ解析・機械学習するときは、以上の点に注意するようにしてください。
以上です。
質問やコメントなどありましたら、twitter, facebook, メールなどでご連絡いただけるとうれしいです。