
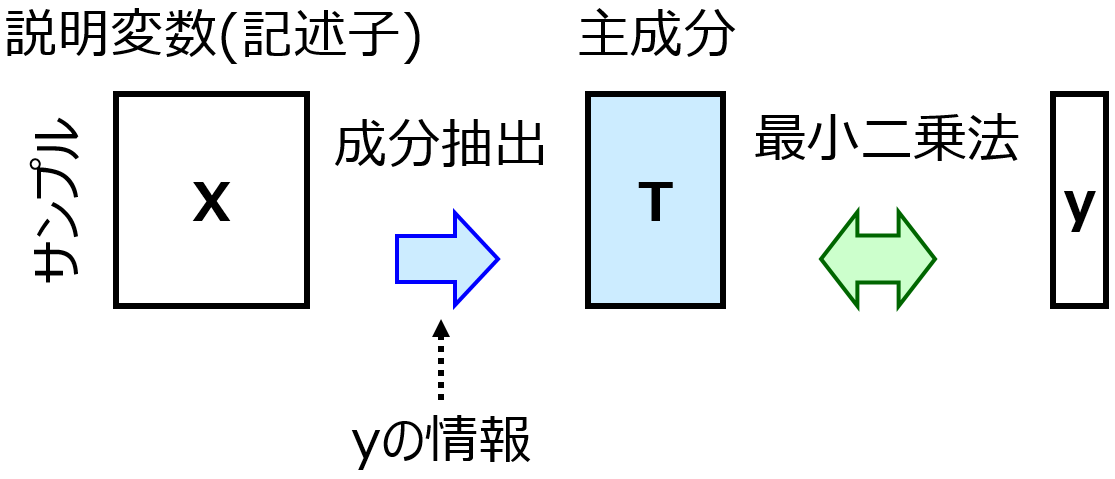
回帰モデル・クラス分類モデルの評価

のなかで、yランダマイゼーション (y-randomization) についてです。y-scrambling と呼んだりもします。
やることは簡単で、目的変数 y の値をサンプル間でシャッフルして、回帰モデル・クラス分類モデルを構築するといった、あえておかしなことをするだけです。これで、解析しているデータセットが、用いている回帰分析・クラス分類手法によって、どれくらい過学習 (オーバーフィット) しやすいか、を評価できます。ただ注意点として、ハイパーパラメータも、シャッフルした後の y のデータを使って、あらためて最適化してください。
回帰モデルを構築するとき、推定性能の高いモデルを構築することが目的の一つになります。今、トレーニングデータにおける決定係数 r2 の値が 1 に近い値で、Root-Mean-Square Error (RMSE) や Mean Absolute Error (MAE) が 0 に近い値のとき、以下の2つの可能性があります。
- 推定性能の高いモデルを構築できた!
- モデルがトレーニングデータにオーバーフィットしている!
ちなみに、r2, RMSE, MAE の詳細については以下をご覧ください。
もちろん、実際は 1. と 2. の間のグラデーションの中ということになります。説明変数の数が少ないほど、サンプルの数が多いほど、1. の傾向が強くなりますし、その逆 (変数の数が多くサンプル数が少ない) になるほど、2. の傾向が強くなります。
サンプル数が少ないときに問題となるのが、chance correlation (偶然の相関) です。説明変数と目的変数との間に関係がないにもかかわらず、偶然に相関関係が得られてしまった、ということです。たとえば、ただの乱数なのに y との相関係数が高い、みたいな状況です。サンプル数が少ないほど、chance correlation が起きやすくなります。また、説明変数の数が多くなるほど、chance correlation の可能性も大きくなります。
y-randomization であえて y をシャッフルすることで、普通だったら精度の高いモデルは作れない状況にします。r2 が 0 付近になり、RMSE, MAE が大きくなるのが普通です。chance correlation が生じやすい状況では、y をシャッフルしたようなおかしな状況でも、chance correlation によって精度の高いモデルが作れてしまいます。r2 が 1 付近になり、RMSE, MAE が小さくなってしまうんです。つまり、y-randomization によって計算された r2, RMSE, MAE が、元の r2, RMSE, MAE と近いほど、元のデータセットでモデリングしたときに chance correlation が起きている可能性が高いですよ!、ということです。y-randomization を複数回行って、そのときの r2, RMSE, MAE の分布を見るとよいです。
y-randomization により、解析しているデータセットと回帰分析手法の組み合わせは 1. になりやすいのか、2. になりやすいのか、つまり chance correlation によって r2 が高く RMSE, MAE が小さくなってしまったのかどうか、を評価できます。
ここで、scikit-learn の sklearn.datasets.make_regression を用いて生成したサンプルデータを用いて、y-randomization のデモをします。サンプルコードはこちらです。
目的変数の数が 1、説明変数の数が 100 とします。回帰分析手法は Partial Least Squares (PLS) です。
トレーニングデータ数が多いとき
まず、トレーニングデータ数がある程度多いときとして、2000 個のときを考えます。トレーニングデータで PLS モデルを構築し、10000 個のテストデータを予測した結果がこちらです。
| r2 | RMSE | MAE | |
| トレーニングデータ | 0.969 | 29.2 | 23.4 |
| テストデータ | 0.967 | 30.9 | 24.6 |
本来であれば、データセットが異なるときに r2, RMSE, MAE の値を比較してはいけませんが、今回はトレーニングデータもテストデータも同じ関数から生成したものでありデータ分布はほとんど同じなので、比較します。
上の表より、トレーニングデータ・テストデータそれぞれの r2 は 1 に近く、精度の高いモデルおよび良好な推定結果が得られたことがわかります。また、トレーニングデータの RMSE, MAE と、テストデータの RMSE, MAE とが、それぞれ大きくは離れていません。このとき、1. の “推定性能の高いモデルを構築できた!” ときだと考えられます。ただこれは、テストデータがあるからこそわかることです。ないと仮定したらどうでしょうか。
ここで、トレーニングデータのみを用いて 30 回 y-randomization を行います。r2, RMSE, MAE の平均値がこちらです (サンプルコードでは 30 回の分布も確認できます)。
| r2 | RMSE | MAE | |
| 30回の y-randomization の平均 | 0.05 | 162.1 | 129.7 |
r2 は 0 付近であり、RMSE, MAE が元のデータセットの結果より大きくなっていることから、今回のデータセットと PLS との組み合わせでは、chance correlation はほとんど起きていないといえます。実際、トレーニングデータの推定結果と同様の精度で、テストデータを推定できています。
トレーニングデータ数が少ないとき
次に、トレーニングデータ数を減らして 100 個にしたときを考えます。トレーニングデータで PLS モデルを構築し、10000 個のテストデータを予測した結果がこちらです。
| r2 | RMSE | MAE | |
| トレーニングデータ | 0.998 | 6.9 | 5.8 |
| テストデータ | 0.673 | 90.8 | 72.3 |
ここでも、トレーニングデータもテストデータも同じ関数から生成したものでありデータ分布はほとんど同じであるため、r2, RMSE, MAE を比較します。
上の表より、トレーニングデータの r2 は 1 に近い一方で、テストデータの r2 は小さく、またトレーニングデータの RMSE, MAE よりテストデータの RMSE, MAE がとても大きいことがわかります。今回は、2. の “モデルがトレーニングデータにオーバーフィットしている!” 状況だと考えられます。Chance correlation もあってよくフィッティングしたのでしょう。ただこれは、テストデータがあるからこそわかりました。テストデータがなければ、推定精度の高いモデルなのかオーバーフィッティングしているのか、わかりません。
ここで、トレーニングデータのみを用いて 30 回 y-randomization を行います。r2, RMSE, MAE の平均値がこちらです (サンプルコードでは 30 回の分布も確認できます)。
| r2 | RMSE | MAE | |
| 30回の y-randomization の平均 | 0.95 | 33.0 | 26.6 |
r2 は 1 に近いことから、今回のデータセットと PLS との組み合わせで、chance correlation が起きうると考えられます。実際、トレーニングデータの推定結果と比較して、テストデータの推定性能は低いです。Chance correlation によってモデルがトレーニングデータにオーバーフィットしてしまったのです。
このように y-randomization により、扱うデータセットと回帰分析手法との組み合わせで、chance correlation が起きやすいのかどうかや、オーバーフィットしているのかどうかが分かります。
なおサンプルコードでは、クロスバリデーションの結果も一緒に比較しています。
変数選択のときにも y-randomization を使える!
説明変数を最適化するときも、chance correlation が生じやすいです。たとえば、Genetic Algorithm-based Partial Least Squares (GAPLS) や Genetic Algorithm-based Support Vector Regression (GASVR)

を用いるとき、トレーニングデータの r2 ではなくクロスバリデーション後の r2 (r2CV) を最大化しているとはいっても、特にサンプル数が小さいとき、chance correlation によりオーバーフィットすることがあります。実際、y-randomization して GAPLS をしたときに、r2CV が 1 近くになることもあります。このようなとき、元のデータセットで GAPLS により選択された変数は、chance correlation により選択された変数と考えられます。変数選択するときは、並行して y-randomization してから同様に変数選択し、結果を比較・確認するとよいです。
[New] こちらの DCEKit で、便利に y-randamization をご利用いただけます。

以上です。
質問やコメントなどありましたら、twitter, facebook, メールなどでご連絡いただけるとうれしいです。

