2018年5月22日 (火) に第7回ケモインフォマティクス若手の会@渋谷ヒカリエ に参加して参りました。金子研の学生たちも一緒です。修士一年の3人は、グループディスカッションの話題提供もしました。
- 小島巧, 金子弘昌, “時間軸を用いたソフトセンサーの新規評価手法の開発”
- 清水直斗, 金子弘昌, “少数サンプルにおける活性予測モデルの性能評価および精度向上”
- 菅野泰弘, 金子弘昌, “半教師あり学習の新規手法を提案”
学生たちのグループディスカッションの資料は、金子研オンラインサロンで共有しています。
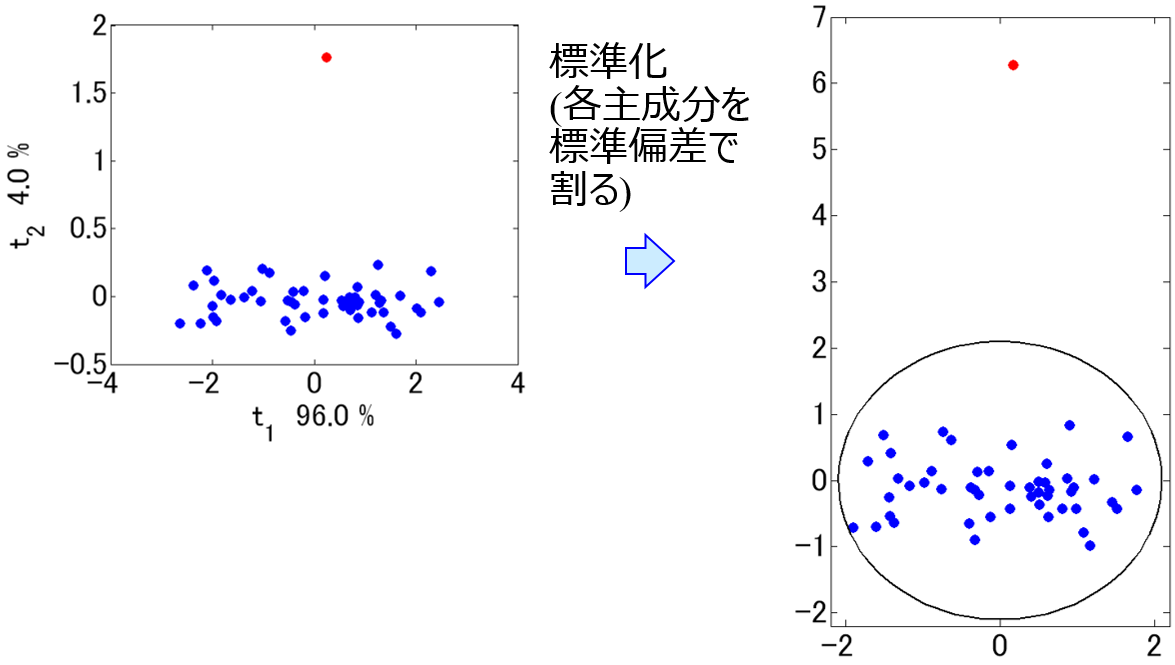
私のグループディスカッションの内容についてはこちらをご覧ください。

第7回ケモインフォマティクス若手の会はDeNAにスポンサーになっていただき、会場を提供していただいたり、事前準備・当日のサポート・後片付けをやっていただいたり、コーヒーブレイクや懇親会などの費用を負担していただいたりしました。DeNAのお陰で懇親会も全員無料だったのです!どうもありがとうございました。
今回の若手の会では、最初に参加者を6グループに分けて、テレパシーというゲームをしました。適当なお題 (好きな機械学習の手法は?とか) を決めて、グループの一人ひとりが他の人に見えないように紙に答えを書いて、いっせーのーせ、で見せあって、二人だけ同じ答えの人がいたら、その二人にポイントが与えられる、というゲームです。お題や答えについて、グループ内でワイワイ話し合って、参加者の方々で打ち解けあっていました。
そのゲームのあとに続いてグループディスカッションがスタートしますので、参加者の皆さんも質問しやすく、話しやすい、といった感じです。各グループ、にぎやかに盛り上がっていました。ちなみにグループディスカッションのテーマはこちらの通りです。
創薬の現場で機械学習をどう活かすか?
タンパク質超二次構造コードを用いたインターフェロンα、β、γの構造相同性アライメント解析
Spresso – 超高速なタンパク質立体構造ベース創薬を目指して
Grammatical evolution を用いた集団最適化による新規分子設計
少数サンプルにおける活性予測モデルの性能評価および精度向上
半教師あり学習の新規手法を提案
Generative Topographic Mapping (GTM) でデータの可視化・回帰分析・モデルの逆解析を一緒にやってみた
糖摂取後のヒト血中分子濃度の時間変動解析
時間軸を用いたソフトセンサーの新規評価手法の開発
どのテーマも面白い話ばかりで、自分のグループディスカッションもあって他の人のディスカッションにあまり参加できなかった身としては、時間が足りない!といった感じでした。
その後わたしが、” QSPR/QSARモデルの適用範囲~基礎・応用事例・最近の研究内容~” というタイトルで講演をやらせていただきました。講演資料は金子研オンラインサロンに入れば見ることができます。
ちなみに、スライドのタイトルはこんな感じです。
- 自己紹介
- データ化学工学研究室(金子研)
- 金子研オンラインサロン
- QSAR・QSPR
- モデルは役に立っているのか?
- まとめ~7つのメッセージ~
- モデルの構築と予測
- 誤差
- 回帰モデルを構築する
- どのモデルが良いか?
- 別のデータを用いてモデルを検証する
- 検証した結果
- 誤差をまとめてどう考えるか?
- 回帰分析 決定係数 r2
- 回帰分析 RMSE
- 回帰分析 MAE
- クラス分類 混同行列・正解率・精度・検出率
- クラス分類 Kappa係数
- もう一つのモデルの検証方法
- クロスバリデーション
- クロスバリデーションの補足
- モデル選択の例: サポートベクター回帰 (SVR)
- モデル選択が必要な手法の例
- モデル選択した後は?
- どんなXの値でもモデルに入力してよいのか?
- モデルの適用範囲・適用領域のイメージ
- モデルの適用範囲・適用領域
- AD の設定
- トレーニングデータの範囲
- トレーニングデータの中心からの距離
- データ密度
- k-NN法
- アンサンブル学習
- モデルとの距離 (Distance to Model)
- 回帰モデルの予測誤差(信頼性)の推定
- ケーススタディ: QSPR
- 回帰モデルの構築および検証結果
- DMと予測誤差の関係(バリデーションデータ)
- DMと予測誤差の標準偏差の関係
- テストデータの推定結果
- 注意!
- 数値シミュレーションデータで確認
- すべてのサブモデルで分類結果が一致した領域
- データ密度も使いましょう!
- ケーススタディ:QSPR
- 回帰分析
- 回帰分析 予測値の信頼性
- クラス分類
- クラス分類結果 k-NN
- いろいろな(回帰)モデルがあるはず!
- サポートベクター回帰 (SVR) [1]
- ハイパーパラメータの値の候補
- ハイパーパラメータの選択
- クロスバリデーション (交差検定)
- ハイパーパラメータの選択
- これでいいのか??
- モデルの適用範囲を考慮した新しい指標 [1]
- ケーススタディ
- Coverage vs. RMSE
- logSの実測値 vs. logSの推定値
- アンサンブル学習における適用範囲
- サブモデルの適用範囲
- サブモデルの適用範囲を考慮したアンサンブル学習
- ケーススタディ
- 比較した手法
- 実測値 vs. 推定値
- QSAR / QSPR + AD [1]
- モデルの適用範囲内への化学構造生成手法
- データ密度の推定
- OCSVM
- OCSVMモデルの微分
- 構造生成の例 [1]
- おまけ:化学プロセスにおける異常検出
- 異常に関係するプロセス変数の検出
- まとめ~7つのメッセージ~
皆さん、データを使って何らかのモデルを作ったら、使うときは必ずモデルの適用範囲を考慮しましょう!あとで痛い目を見ても知りませんよ!!・・・といった話です。
講演のあとは懇親会。お酒もはいって皆さん舌がなめらかになり、さらに会場が盛り上がっていました。初めてお会いする方や久しぶりにお会いする方など、いろいろな方々とお話できてよかったです。
というわけで、勉強にもなり、楽しくもあり、今後の話にも繋がり、充実した一日でした。
若手の会への参加者は、5年前の第一回と比べて2倍になり、過去最高人数を記録しました。参加者のアンケートの結果も、ポジティブなコメントが多く、ケモインフォマティクスの若手の方々のこれからの活躍が楽しみです!


以上です。
質問やコメントなどありましたら、twitter, facebook, メールなどでご連絡いただけるとうれしいです。