回帰モデルやクラス分類モデルを構築した後の、モデルの逆解析の話です。

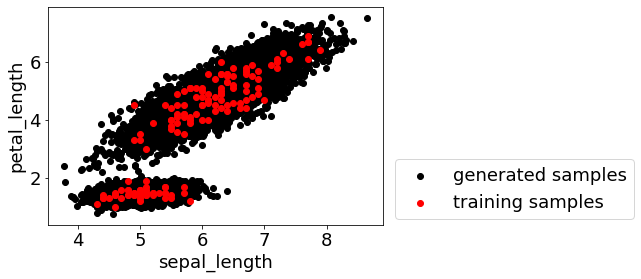
上の [Pythonコードあり] 既存のサンプルの分布に従うように、モデルの逆解析用のサンプルをたくさん生成する方法 では、既存のサンプルのデータ分布を求めて、その分布に従うようにして新たなサンプルを生成する方法を、Python コード付きで紹介しました。モデルの逆解析の流れも説明していますので、興味がありましたらご覧ください。
今回は、特徴量ごとに制限があったり、特徴量の間に制限があったりするときに、モデルの逆解析用のサンプルを生成します。Python コードもあります。こちら https://github.com/hkaneko1985/dcekit の demo_sample_generation_restricted.py です。
デモンストレーションでは、仮想的な樹脂材料のデータセット (virtual_resin.csv) に基づいて、モデルの逆解析用のサンプルを生成しています。
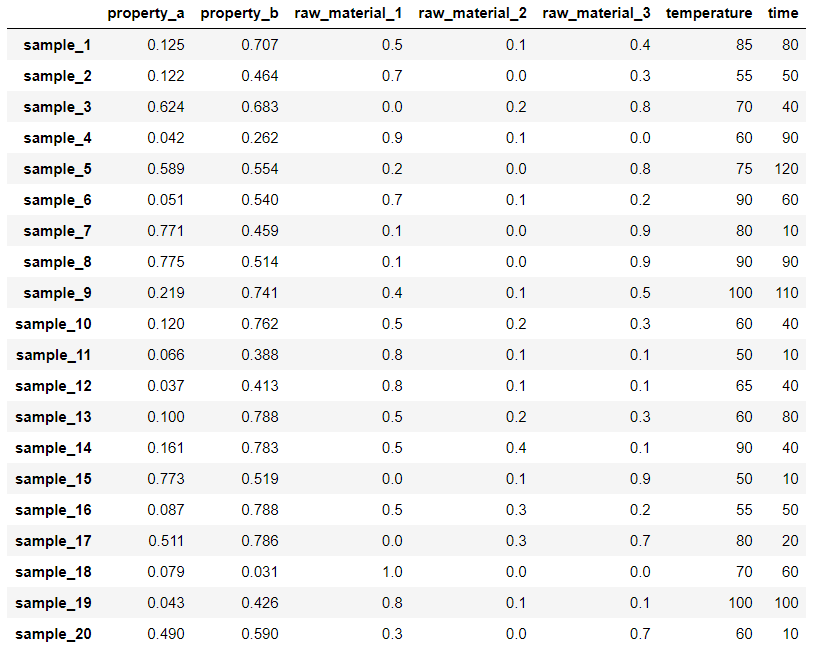
仮想的な樹脂材料のデータセット
原料として 3 種類 (raw material 1, raw material 2, raw material 3) あり、それらの組成比と重合温度 (temperature)・重合時間 (time) をそれぞれ変えて樹脂材料が作られ、物性 a (property a) と物性 b (property b) が測定されたような 20 サンプルがあるとします。
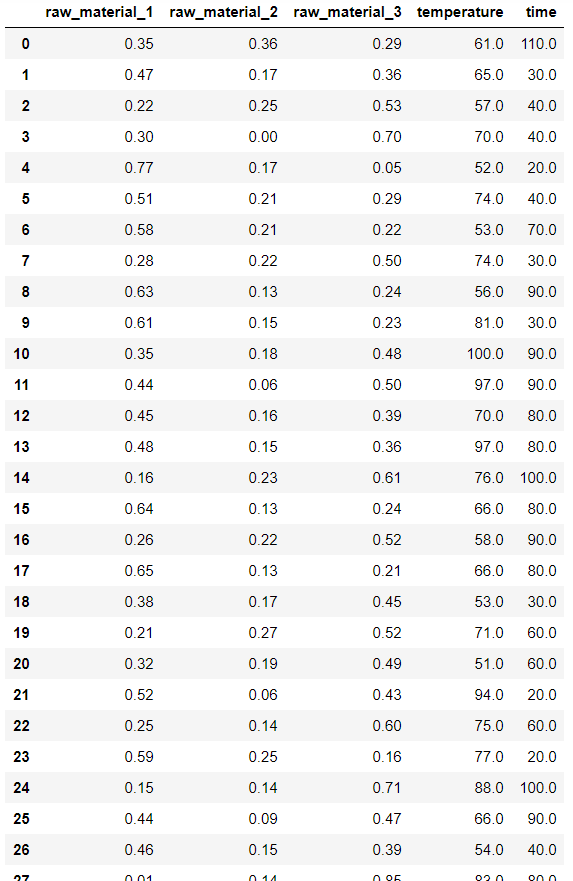
今回はモデルの逆解析用のサンプル生成ですので、目的変数である物性a, b は除いた、説明変数のみのデータセット virtual_resin_x.csv を用います。

サンプルプログラム demo_sample_generation_restricted.py では、
file_name = ‘virtual_resin_x.csv’
でファイル名を設定します。ご自身でお持ちの csv ファイルの名前にすれば、それに基づいてモデルの逆解析用のサンプルを生成できます。
また生成するサンプルの数を
number_of_samples_generated = 10000
で設定します。初期設定では 10000 サンプル生成することになります。
生成するサンプルについて、各説明変数の上限値と下限値を
x_max_rate = 1.1
x_min_rate = 0.9
で設定します。これらの値を、それぞれ既存のデータセット (ここでは virtual_resin_x.csv) の最大値・最小値にかけることで、上限値・下限値にします。初期設定では、各説明変数の最大値の 1.1 倍を上限値に、最小値の 0.9 倍を下限値にしています。
もし、強制的に値を 0 にしたい説明変数があれば、zero_variable_numbers でそれらの説明変数の番号を指定します。複数の番号を設定しても OK です。初期設定では、強制的に値を 0 にする説明変数はないとして、空の list
zero_variable_numbers = []
にしています。
今回の仮想的な樹脂のデータセットでは、raw_material_1 から raw_material_3 までの合計が 1 という制約があります。このように、いくつかの特徴量の合計に制約があるときは、list_of_component_numbers で制約のある説明変数の番号を設定し、desired_sum_of_components で合計の値を設定します。初期設定では、
list_of_component_numbers = [0, 1, 2]
desired_sum_of_components = 1
として、0, 1, 2 番目の説明変数の合計が 1 になるようにしています。なお、説明変数の合計の制約を満たすように説明変数の値を変換したとき、説明変数によっては変換後の値が上限値や下限値を超えてしまうことがあります。それらのサンプルを削除するため、最終的に生成されるサンプルの数が number_of_samples_generated で設定した値より小さくなることがあります。注意しましょう。
説明変数の合計に制約がない場合は、list_of_component_numbers を空の list
list_of_component_numbers = []
にしましょう。
もし、四捨五入で端数処理をしたいときは、decimals で説明変数ごとの桁の数を指定します。桁数の指定の仕方として、小数点 m 桁目まで残したい ((m + 1) 桁目を四捨五入したい) 場合は、m と設定します。10 の n 乗の位まで残したい (10 の (n – 1) 乗の位で四捨五入したい) 場合は -n と設定します。初期設定では、
decimals = [2, 2, 2, 0, -1]
として、raw_material_1, raw_material_2, raw_material_3 の説明変数は小数点 2 桁目まで残し、temperature の説明変数は 10 の 0 乗の位まで残し、time の説明変数は 10 の 1 乗の位まで残すようにします。
四捨五入で端数処理をしない場合は、decimals を空の list
decimals = []
にしてください。ただし、端数処理をする場合は、decimals ですべての説明変数の設定をする (説明変数の数だけ要素をもつ list にする) 必要があります。
以上の設定をして実行すると、生成されたサンプルが generated_samples.csv に保存されます。
参考になりましたら、ぜひご活用いただければと思います。
以上です。
質問やコメントなどありましたら、twitter, facebook, メールなどでご連絡いただけるとうれしいです。