
一般的なデータ解析・機械学習では、一つのデータセットがあるとき、一つのモデルを構築します。こちらのデータ解析の流れにそって、

最終的に、例えばガウス過程回帰で、一つのモデルを構築することになります。アンサンブル学習では、たくさんのサブデータセットを作成して、それぞれでモデル (サブモデル) を構築するため多くのモデルがありますが、予測するときはそれらすべてのモデルを用いますので、ここでは広い意味で一つのモデルととらえます。
一方で、例えばデータセットをクラスタリングしてからクラスターごとにモデルを構築したり、決定木を使ってサンプルを分けてからサンプル集団ごとにモデルを構築したりすることがあります。これにより全体的な予測精度の向上や、モデルの解釈性を達成できると期待できます。実際、金子研では決定木 + Random Forests で予測精度の高さとモデルの解釈性の両立するような手法を開発しましたし (以下の URL 先の “Naoto Shimizu, Hiromasa Kaneko, Constructing Regression Models with High Prediction Accuracy and Interpretability Based on Decision Tree and Random Forests, Journal of Computer Chemistry, Japan, accepted. (2021年3月28日現在)”、

ソフトセンサーにおいてデータセットをクラスタリングした後に、動特性を考慮するモデルを構築することで、プロセス状態ごとに異なる動特性を考慮する手法の研究もしています。
以上のように、大きく分けると、データセットごとに一つのモデル (グローバルモデル) を構築することと、複数のローカルモデルを構築することに分けられます。アンサンブル学習で (最終的に) 構築されるモデルはグローバルモデルです。
特に分子設計、材料設計、プロセス設計では、外挿の予測が重要です。ここで、外挿の予測にグローバルモデルとローカルモデルのどちらが向いているか考えます。まず、そもそもの大前提として、外挿を予測した結果だけでは、それが正しいかどうかは誰にも分かりません。もちろん外挿を予測した結果に基づいて実験をして、予測結果があっているかを確認できますが、モデルが外挿を予測した段階では、モデルAの予測結果とモデル B の予測結果のどちらが確からしいかはわかりません。そのため、以下のことは単に私の考えです。
繰り返しますが外挿における説明変数 x と目的変数 y の間の関係の正解は誰にもわからないことから、できる限り多くのサンプルを用いて、今のデータ範囲 (モデルの適用範囲) の x と y の関係をモデル構築して、その少し外挿もしくはモデルの適用範囲外を予測するのがよいと思います。

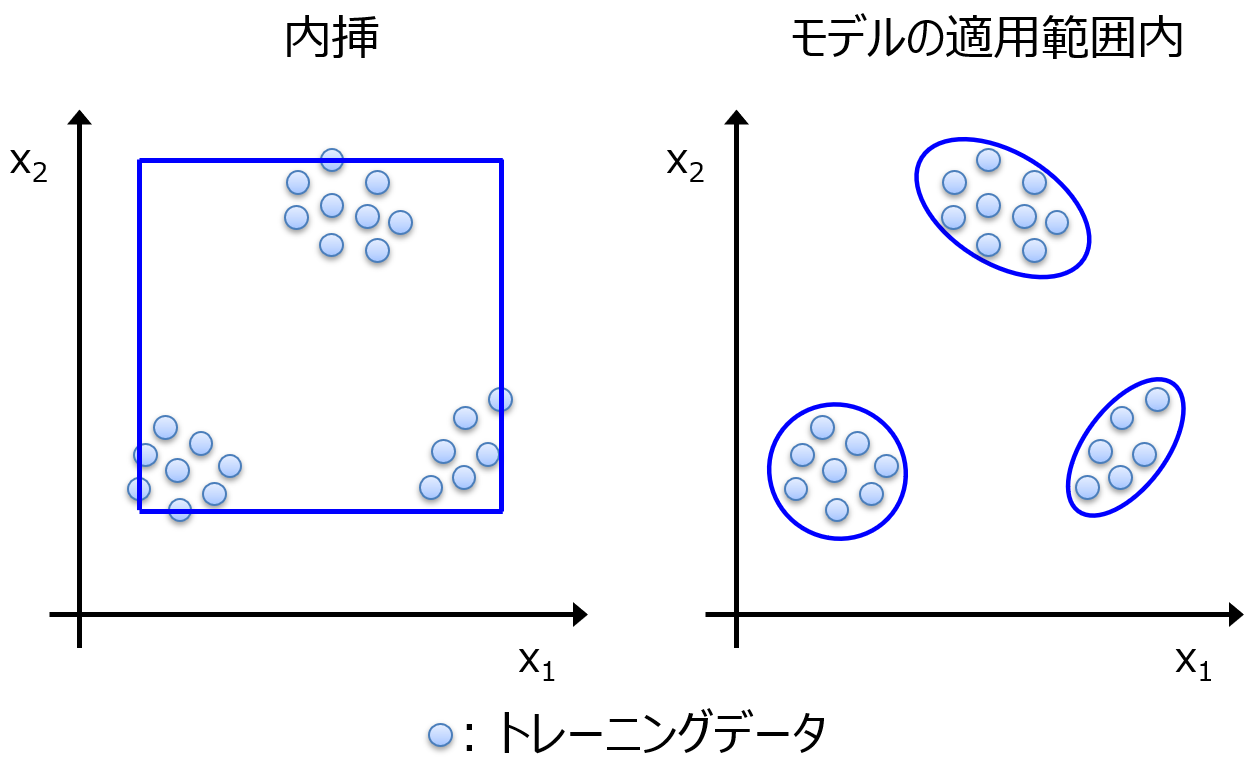
ローカルモデルでは、データセットを分割した後に一部のサンプルのみを用いてモデルを構築することから、より多くのサンプルを用いて構築されたグローバルモデルと比べて、モデルを構築したデータ範囲の少し先の信頼性が低くなると考えられます。
もちろん、x と y の関係性が異なるサンプルが混在するデータセットにおいて、ローカルモデルを構築することで様々な x と y の関係をモデル化できると考える方もいらっしゃるかもしれませんが、そもそも x と y の関係が異なる時点で、x の値だけから、すなわち予測するデータだけから、x と y の間の関係の違いを判断することはできません。仮に x の値の違いで、例えば x が 0 以上と 0 以下とで x と y の傾きが異なるのであれば、x が 0 以上のローカルモデルと x が 0 以下のローカルモデルに分ける必要はなく、一つのグローバルモデルで十分対応できます。さらに、x が 0 以上のデータセットだけでなく x が 0 以下のデータセットも用いて、x と y の関係を求めることで、より確からしい x と y の関係を求められると考えられます。その関係性が成り立つのであれば、ある程度モデルの適用範囲外でも同じ予測できると考えられます
ちなみに、チャンピオンデータを含むポジティブデータだけでなく、ネガティブデータもモデル構築のために重要というのは、上の話と同じです。より確からしい x と y の関係性を求めるためには、よくない結果と良い結果との関係性を抽出することも重要です。
以上のように、グローバルモデルとローカルモデルはそのモデルを使用する目的によって使い分けるとよいです。もちろんグローバルモデルもローカルモデルも、データ解析の基本的な流れにそって、
予測精度を検証しつつ、どちらを使用するべきか考える必要があります。ただ一方で、基本的にローカルモデルは内挿もしくはモデルの適用範囲内の予測やモデルの解釈が得意であり、外挿の予測はグローバルモデルが向いているといえます。
以上です。
質問やコメントなどありましたら、twitter, facebook, メールなどでご連絡いただけるとうれしいです。

